Cognee:6行代码落地的AI代理内存方案,融合知识图谱与向量搜索的开源工具
一、Cognee是什么?
Cognee是一个面向AI代理(AI Agents)设计的开源内存工具与平台,其核心定位是解决AI代理“记忆碎片化”“数据关联弱”“检索精度低”的痛点,将分散的原始数据转化为“可理解、可关联、可复用”的持久动态内存。
从本质来看,Cognee并非简单的数据存储工具,而是一套完整的“数据结构化-知识关联-智能检索”解决方案:它通过整合向量搜索(语义搜索能力)与图数据库(关系关联能力),让数据既能够按“意义”被检索,又能通过内在关系形成结构化知识网络,最终为AI代理提供类人类的“长期记忆”。
根据项目文档描述,Cognee的核心优势在于替代传统RAG系统——相比传统RAG 5%的回答相关性、ChatGPT(无定制化内存)5%的回答相关性,Cognee的回答相关性高达92.5%,能显著提升AI代理基于特定数据的响应精度。
其核心定位可概括为三点:
AI内存引擎:为AI代理提供持久化、动态更新的“记忆系统”,而非临时数据缓存;
数据结构化工具:将非结构化数据(文本、图像、音频转录)转化为结构化知识图谱;
轻量化开发框架:通过极简API和CLI工具,降低AI内存层的开发门槛,支持快速落地。
Cognee支持两种核心使用模式,满足不同用户需求:
自托管模式(Cognee Open Source):所有数据默认本地存储,适合注重隐私保护、需要高度定制化的开发者或企业;
云托管模式(Cognee Cloud):基于托管基础设施提供服务,包含Web UI、自动更新、资源分析等功能,适合快速开发与生产部署。
二、功能特色
Cognee的功能设计围绕“高效、灵活、精准”三大核心,结合项目文档梳理其核心特色如下:
1. 多类型数据全兼容,打破数据孤岛
Cognee支持接入多种类型的数据,无需额外数据转换工具,直接作为AI内存的输入源:
文本类:纯文本、文档(隐含支持30+数据源摄入,推测含PDF、Word、Markdown等);
交互类:历史对话记录(适配AI代理的对话记忆场景);
多模态类:图像、音频转录文件(满足复杂场景下的多源数据整合需求)。
这种兼容性让Cognee能够无缝对接AI代理的各类数据场景,无需用户单独处理数据格式,降低集成成本。
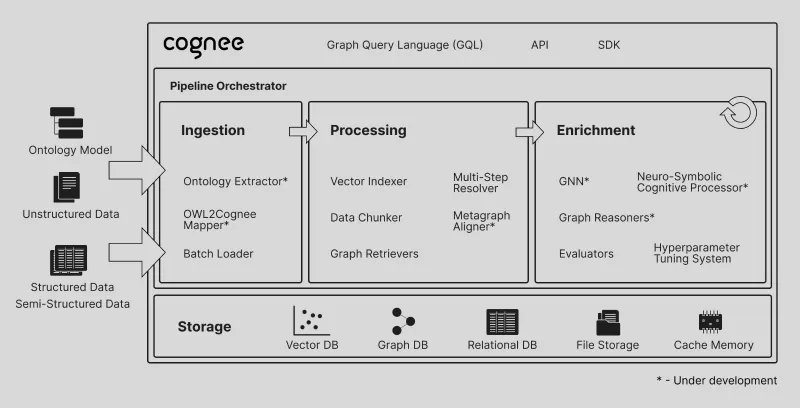
2. ECL管道架构,替代传统RAG的核心优势
Cognee以“Extract(提取)- Cognify(认知化)- Load(加载)”的模块化管道替代传统RAG的“检索-增强”流程,核心优势在于:
Extract(提取):自动从原始数据中提取关键信息,无需人工标注;
Cognify(认知化):将提取的信息转化为知识图谱,建立数据间的关联关系(如“Cognee”与“AI内存”的“功能归属”关系);
Load(加载):将知识图谱与内存算法结合,形成可检索的AI内存层。
相比传统RAG仅依赖向量匹配的检索逻辑,ECL管道通过“语义+关系”双重维度提升检索精度,这也是其92.5%高回答相关性的核心原因。
3. 双部署模式,兼顾灵活性与便捷性
Cognee提供自托管与云托管两种模式,用户可根据需求自由选择,且核心功能完全一致:
| 功能维度 | 自托管模式(Cognee Open Source) | 云托管模式(Cognee Cloud) |
|---|---|---|
| 数据存储位置 | 本地存储,隐私可控 | 托管基础设施,无需本地维护 |
| 核心功能 | 数据摄入、知识图谱构建、内存算法集成、检索 | 与自托管一致,额外提供增值服务 |
| 增值功能 | 无(需自行开发扩展) | Web UI仪表板、自动版本更新、资源使用分析 |
| 安全合规 | 依赖本地部署配置 | GDPR合规、企业级安全保障 |
| 适用场景 | 隐私敏感场景、高度定制化需求、本地AI代理开发 | 快速原型开发、生产部署、企业级规模化使用 |
4. 极简开发体验,6行代码快速落地
Cognee的核心设计理念是“降低开发门槛”,无论是API还是CLI工具,都追求“轻量化、直观化”:
API层面:核心流程仅需
add(添加数据)→ cognify(构建图谱)→ memify(集成内存算法)→ search(检索)4个步骤,异步支持让代码更简洁;CLI层面:提供
cognee-cli命令行工具,无需编写代码即可完成数据添加、图谱构建、检索等核心操作;本地UI:通过
cognee-cli -ui命令即可启动本地可视化界面,直观查看知识图谱与检索结果。
5. 高度定制化,适配多样化需求
Cognee的模块化设计支持多维度定制:
数据源定制:支持30+数据源摄入,可通过Pythonic数据管道扩展自定义数据源;
任务定制:支持用户定义个性化处理任务(如特定数据的提取规则、图谱关系定义);
LLM定制:兼容OpenAI、Ollama等多种LLM提供商,可根据需求切换底层大模型;
存储定制:支持多种向量数据库与图数据库适配(如项目中提到的Kuzu、Redis锁集成),可根据性能需求选择存储方案。
6. 时序查询支持,适配动态场景
在examples模块的更新记录中提到,Cognee已支持“temporal queries(时序查询)”,即能够基于时间维度筛选记忆内容,适配需要“时间关联记忆”的场景(如AI代理的历史对话回溯、按时间排序的文档检索)。
7. 完善的工具链与生态支持
Cognee提供了从开发到部署的完整工具链:
开发工具:支持pip、poetry、uv等多种Python包管理器安装,兼容主流开发环境;
调试工具:内置日志系统(支持文件日志输出)、本地UI可视化;
部署工具:提供Dockerfile、docker-compose.yml配置,支持容器化部署;
生态资源:包含Notebooks教程、Examples演示脚本(如LangGraph集成、Ollama集成)、研究论文支持。
8. 安全与稳定性保障
自托管模式:数据本地存储,避免数据传输过程中的隐私泄露;
云托管模式:GDPR合规,提供企业级安全保障;
技术层面:支持Redis锁集成(解决并发问题)、向量数据库异步锁(避免数据冲突)、Kuzu图数据库持久化(防止数据丢失)。

三、技术细节
1. 核心技术栈
| 技术维度 | 具体实现细节 |
|---|---|
| 开发语言 | Python(兼容3.10-3.13版本) |
| 核心依赖 | 异步编程框架(asyncio)、LLM API客户端(OpenAI等)、向量数据库适配器、图数据库驱动 |
| 数据库支持 | 向量数据库(适配多提供商)、图数据库(Kuzu为核心支持,文档中提到Kuzu持久化优化) |
| 锁机制 | Redis锁(解决分布式并发问题)、向量数据库异步锁(避免数据写入冲突) |
| 前端技术 | 前端UI基于Next.js(cognee-frontend模块) |
| 部署工具 | Docker、docker-compose、Alembic(数据库迁移) |
| 开发工具链 | Poetry(依赖管理)、UV(快速安装)、pytest(测试)、ruff(代码检查) |
2. 核心架构:ECL管道 + 双数据库融合
Cognee的底层架构可拆解为“数据输入层-ECL处理层-存储层-检索层-接口层”五大模块,核心逻辑是“ECL管道处理数据,双数据库(向量+图)存储知识,轻量化接口提供服务”:
(1)数据输入层
支持多源数据接入:通过Pythonic数据管道对接30+数据源,包含文本、文件、图像、音频转录等;
数据输入方式:API调用(
cognee.add())、CLI命令(cognee-cli add)、文件导入(隐含支持,通过示例推测)。
(2)ECL处理层(核心逻辑)
Extract(提取):从原始数据中提取实体(如“Cognee”)、属性(如“开源工具”)、关系(如“转化→AI内存”),无需人工干预;
Cognify(认知化):将提取的实体与关系构建为知识图谱,核心依赖图数据库(Kuzu),支持实体间多维度关系关联;
Memify(内存化):将知识图谱与内存算法结合,本质是为知识图谱添加“检索优化逻辑”(如向量嵌入、时序索引),让图谱具备高效检索能力。
(3)存储层
双数据库融合:向量数据库负责“语义相似性检索”(快速匹配与查询意图相关的实体),图数据库负责“关系遍历”(追溯实体间的关联路径);
数据持久化:自托管模式下支持本地文件存储+数据库持久化(Kuzu图数据库持久化优化已在更新记录中提及),云托管模式下依赖托管存储基础设施;
锁机制保障:Redis锁用于分布式场景下的并发控制,向量数据库异步锁用于避免多线程写入冲突。
(4)检索层
检索逻辑:结合“向量语义匹配”与“图关系遍历”,先通过向量搜索筛选出候选实体,再通过图数据库追溯关联关系,最终返回精准结果;
支持查询类型:普通语义查询(如“What does Cognee do?”)、时序查询(基于时间维度的记忆检索,文档examples模块提及)。
(5)接口层
API接口:Python异步API(
cognee.add()/cognify()/memify()/search()),支持集成到Python开发的AI代理中;CLI工具:
cognee-cli命令行工具,支持无代码快速操作;UI接口:本地Web UI(通过
cognee-cli -ui启动),可视化查看知识图谱与检索结果;第三方集成:通过MCP(模型上下文协议)服务器(cognee-mcp模块),支持与其他工具通过SSE/HTTP/stdio集成。
3. 核心模块解析
根据项目仓库的目录结构,核心模块功能如下:
cognee/:核心库,包含ECL管道实现、API接口、数据库适配器等核心逻辑,最新更新支持OllamaEmbeddingEngine的多响应格式处理;cognee-frontend/:基于Next.js的前端UI,用于本地开发时的可视化操作,支持知识图谱查看、检索结果展示;cognee-mcp/:模型上下文协议服务器,负责将Cognee暴露为MCP工具,支持与其他AI生态工具集成;cognee-starter-kit/:入门套件,优化了结构与可读性,帮助新手快速上手;distributed/:分布式执行模块,支持Modal、工作队列等分布式部署场景,修复了分布式管道的稳定性问题;examples/:示例脚本,包含LangGraph集成、Ollama集成、时序查询等场景的可运行代码;notebooks/:Jupyter笔记本教程,包含核心功能的分步演示,定期更新以适配最新版本;deployment/:部署配置模块,包含Dockerfile、docker-compose.yml,支持容器化部署与数据库持久化优化;evals/:评估模块,已弃用SearchType.INSIGHTS,优化检索评估逻辑。
4. 数据处理流程(以最小示例为例)
结合项目文档中的代码示例,Cognee的核心数据处理流程如下:
数据输入:通过
cognee.add()传入原始数据(文本、文件等),数据被暂存并等待处理;知识图谱构建:调用
cognee.cognify(),ECL管道的Extract模块提取关键信息,Cognify模块构建知识图谱并存储到图数据库;内存算法集成:调用
cognee.memify(),为知识图谱添加向量嵌入、索引等优化,使其具备高效检索能力;智能检索:调用
cognee.search(),检索层结合向量搜索与图关系遍历,返回精准结果;结果输出:支持通过API返回、CLI打印、UI展示三种方式获取结果。
5. 关键技术优化(从更新记录中提取)
多响应格式支持:OllamaEmbeddingEngine已支持多种响应格式,适配不同LLM的输出逻辑;
数据库稳定性:修复Kuzu图数据库持久化问题,添加所有向量数据库的异步锁,避免数据冲突;
时序能力增强:支持“now”概念的时序查询,适配动态时间相关的记忆检索场景;
日志系统:支持文件日志输出,方便调试与问题排查;
依赖管理优化:更新版本锁文件(poetry.lock、uv.lock),确保依赖兼容性。
四、应用场景
1. 持久化AI代理开发
场景描述:为AI代理(如LangGraph、AutoGPT等框架开发的代理)提供长期记忆,避免“对话失忆”或“数据碎片化”。
核心价值:AI代理可通过Cognee存储历史对话、任务进度、用户偏好等信息,下次交互时直接调用内存,无需重复输入或重新检索;
示例:项目中的
cognee_langgraph.mp4演示了Cognee与LangGraph集成,实现AI代理的持久化记忆。
2. 轻量化GraphRAG落地
场景描述:替代传统RAG,快速构建基于知识图谱的检索增强生成系统,适用于需要高精度响应的场景。
核心价值:相比传统RAG仅依赖语义匹配,GraphRAG通过关系关联提升检索精度,Cognee简化了GraphRAG的开发流程,无需手动构建知识图谱;
示例:
simple_graphrag_demo.mp4演示了通过Cognee快速实现GraphRAG,仅需少量代码即可完成文档结构化与检索。
3. 本地隐私优先AI工具开发
场景描述:开发本地运行的AI工具(如本地知识库、私人AI助手),需要数据本地存储、隐私不泄露。
核心价值:Cognee自托管模式支持所有数据本地存储,结合Ollama等本地LLM,可构建完全离线的AI工具,避免数据上传第三方服务器;
示例:
cognee-with-ollama.mp4演示了Cognee与本地LLM(Ollama)集成,实现离线的知识图谱构建与检索。
4. 企业知识库构建与检索
场景描述:企业内部有大量分散的文档(PDF、Word、音频会议记录),需要构建结构化知识库,支持精准检索。
核心价值:Cognee支持30+数据源摄入,可自动将企业文档转化为知识图谱,员工通过自然语言查询即可获取精准答案(如“XX产品的核心功能是什么?”),无需手动翻阅文档;
适配模式:自托管模式(适合注重数据安全的企业)或云托管模式(适合快速部署、无需维护基础设施的企业)。
5. 智能客服系统优化
场景描述:传统智能客服无法记住用户历史咨询,导致重复提问;或无法关联多轮对话中的关键信息。
核心价值:Cognee可存储用户的历史咨询记录、问题类型、解决方案等信息,客服AI可通过内存快速定位用户需求,提供个性化响应,同时关联相关问题的解决方案(如“上次你咨询的XX问题,后续可通过XX方式优化”)。
6. 学术研究助手开发
场景描述:研究人员需要整理大量文献(论文、报告),提取核心观点、研究方法、数据结论,并建立文献间的关联(如“A论文引用了B论文的方法”)。
核心价值:Cognee可自动提取文献中的实体(研究方法、结论、作者)与关系(引用、改进、对比),构建学术知识图谱,研究人员可通过查询快速获取相关文献的核心信息及关联关系(如“哪些论文使用了XX研究方法?”)。
7. 开发测试工具
场景描述:开发者需要快速验证AI代理的内存功能,或测试知识图谱的构建效果,无需编写复杂的底层代码。
核心价值:Cognee的CLI工具与Notebooks教程支持快速上手,开发者可通过几条命令或示例代码验证功能,缩短开发测试周期。

五、使用方法
Cognee的使用流程极简,项目文档提供了“代码快速入门”“CLI工具入门”两种方式,以下是详细步骤(基于项目官方文档整理):
1. 前提条件
操作系统:无明确限制(支持Docker部署,推测兼容Windows、macOS、Linux);
Python版本:3.10 ~ 3.13(项目README明确要求,需提前安装对应版本);
依赖工具:pip、poetry、uv或其他Python包管理器(推荐uv,安装速度更快);
可选依赖:Docker(用于容器化部署)、LLM API密钥(如OpenAI API Key,用于数据处理与检索)。
2. 安装Cognee
支持多种Python包管理器安装,以下是官方推荐的三种方式:
方式1:使用uv(推荐,快速安装)
uv pip install cognee
方式2:使用pip
pip install cognee
方式3:使用poetry
poetry add cognee
3. 配置LLM(核心步骤)
Cognee依赖LLM完成数据提取、知识图谱构建与检索,需先配置LLM提供商的API密钥:
方式1:直接在代码中配置
import os # 替换为你的LLM API密钥(以OpenAI为例) os.environ["LLM_API_KEY"] = "YOUR_OPENAI_API_KEY"
方式2:使用.env文件配置(推荐,更安全)
从项目仓库下载
.env.template文件,重命名为.env;打开
.env文件,添加LLM API密钥:LLM_API_KEY=YOUR_OPENAI_API_KEY
代码中自动加载(无需额外配置,Cognee会自动读取
.env文件)。
扩展:集成其他LLM提供商
Cognee支持除OpenAI外的其他LLM提供商(如Ollama、Anthropic等),具体配置方法参考官方《LLM Provider Documentation》(链接见“相关官方链接”部分)。
4. 代码快速入门(核心流程)
通过6行核心代码即可完成“数据添加-图谱构建-内存集成-检索”全流程,以下是官方示例代码(异步实现):
import cognee
import asyncio
async def main():
# 步骤1:添加数据(支持文本、文件路径等,此处以纯文本为例)
await cognee.add("Cognee turns documents into AI memory.")
# 步骤2:构建知识图谱(Extract + Cognify)
await cognee.cognify()
# 步骤3:为图谱添加内存算法(Memify)
await cognee.memify()
# 步骤4:检索知识图谱(自然语言查询)
results = await cognee.search("What does Cognee do?")
# 步骤5:输出结果
for result in results:
print(result)
if __name__ == '__main__':
# 运行异步函数
asyncio.run(main())运行结果
代码执行后,会输出基于添加数据的精准响应:
Cognee turns documents into AI memory.
5. CLI工具快速入门(无代码方式)
如果无需集成到Python代码中,可直接使用cognee-cli命令行工具操作,核心命令如下:
步骤1:添加数据
cognee-cli add "Cognee turns documents into AI memory."
步骤2:构建知识图谱
cognee-cli cognify
步骤3:检索数据
cognee-cli search "What does Cognee do?"
步骤4:删除所有数据(可选)
cognee-cli delete --all
步骤5:启动本地UI(可视化操作)
cognee-cli -ui
启动后,会自动在浏览器打开本地UI界面,可可视化查看知识图谱、检索结果等。
6. 进阶使用:Colab教程
项目提供了完整的Colab教程,包含核心功能的分步演示(如多数据源接入、知识图谱可视化、时序查询等),可通过以下链接打开: Open in Colab(具体链接需参考项目文档,此处为官方指引位置)
7. 容器化部署(自托管模式进阶)
如果需要通过Docker部署自托管版本,可参考以下步骤:
克隆项目仓库:
git clone https://github.com/topoteretes/cognee.git cd cognee
配置
.env文件(参考.env.template);使用docker-compose启动服务:
docker-compose up -d
访问本地UI:通过浏览器访问
http://localhost:xxxx(端口需参考docker-compose配置)。
六、常见问题解答(FAQ)
1. Cognee支持哪些Python版本?
根据项目文档,Cognee仅支持Python 3.10 ~ 3.13版本,低于3.10或高于3.13的版本可能会出现依赖兼容性问题。
2. 自托管模式下,数据存储在哪里?
自托管模式下,数据默认存储在本地目录(具体路径可通过配置文件自定义),知识图谱存储在Kuzu图数据库(本地文件形式),向量数据存储在指定的向量数据库中,所有数据均不离开本地环境。
3. 除了OpenAI,还支持哪些LLM提供商?
Cognee支持多种LLM提供商,具体包括Ollama、Anthropic、Google Gemini等,配置方法参考官方《LLM Provider Documentation》,需根据不同提供商的要求设置对应的API密钥或本地连接参数。
4. Cognee是否支持多模态数据?
支持。根据项目文档,Cognee可处理图像、音频转录等多模态数据,无需额外插件,直接通过cognee.add()或CLI命令添加即可,ECL管道会自动提取关键信息并构建知识图谱。
5. 自托管模式与云托管模式的核心区别是什么?
核心区别在于“基础设施维护”与“增值功能”:自托管模式需要用户自行维护服务器、数据库等基础设施,但数据隐私可控、支持高度定制;云托管模式无需维护基础设施,提供Web UI、自动更新、资源分析等增值功能,适合快速部署与规模化使用。
6. 构建知识图谱需要专业的图数据库知识吗?
不需要。Cognee的cognify()方法会自动完成知识图谱的构建,用户无需了解图数据库的底层原理或查询语法,仅需调用API或CLI命令即可。
7. Cognee的检索速度如何?
检索速度取决于数据量与硬件配置:小规模数据(万级以下实体)可实现毫秒级响应;大规模数据(百万级实体)建议搭配高性能向量数据库(如Milvus、Chroma)与图数据库优化,可通过分布式部署(distributed模块)提升检索效率。
8. 如何查看知识图谱的可视化效果?
有两种方式:
本地UI:通过
cognee-cli -ui命令启动本地Web UI,在界面中直接查看知识图谱的结构与实体关系;Notebooks教程:项目提供的Jupyter笔记本中包含知识图谱可视化代码,可运行后查看。
七、相关链接
项目GitHub仓库:https://github.com/topoteretes/cognee
官网地址:https://cognee.ai/
八、总结
Cognee作为一款开源AI内存工具,以“极简开发体验+高精准检索+灵活部署”为核心优势,通过ECL管道整合向量搜索与图数据库技术,成功替代传统RAG系统,将AI代理的回答相关性提升至92.5%。其支持多类型数据接入、双部署模式(自托管+云托管)、轻量化API与CLI工具,既满足了个人开发者快速落地AI内存层的需求,也适配了企业级用户对隐私安全、规模化部署的要求。项目提供了完整的教程资源(Notebooks、Colab、演示视频)与活跃的社区支持,同时通过持续的技术优化(如时序查询、多LLM兼容、数据库稳定性提升)完善功能,是AI代理开发、知识库构建、GraphRAG落地等场景下的高效解决方案,显著降低了AI内存系统的开发门槛与基础设施成本。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/cognee.html





