D4RT:Google DeepMind开源的的4D动态场景重建框架,单架构贯通建模与跟踪全流程
一、D4RT是什么
D4RT是由Google DeepMind主导开发的开源4D重建与跟踪框架,核心是通过一套统一架构,从普通2D视频中精准还原动态场景的3D几何结构与时间维度的运动轨迹(即4D建模)。该框架打破传统方法多工具拼接、计算繁琐、动态适配差的痛点,支持点云重建、3D轨迹跟踪、深度图生成、相机参数估计等一站式任务,运行速度较传统方案快18-300倍,精度达行业顶尖水平。其术语友好、部署简单,广泛适配机器人导航、影视制作、增强现实(AR)等领域,可帮助开发者与企业快速集成4D技术,大幅降低应用门槛。
简单来说,D4RT是一款能“让2D视频变4D模型”的开源AI工具——这里的“4D”指“3D空间(长、宽、高)+1D时间”,通俗讲就是它能从一段普通视频里,不仅还原出画面中所有物体的3D形状(比如桌子的高矮、人物的轮廓),还能精准跟踪这些物体在整个视频时间轴上的运动轨迹(比如汽车从左到右行驶、小鸟展翅飞翔的完整路径)。
在D4RT出现之前,动态场景的4D建模是个“麻烦事”:需要分别用专门的工具算物体深度、跟踪运动、校准相机参数,再手动把这些工具的结果拼起来。不仅操作繁琐,不同工具的结果还容易出现偏差(比如深度数据和运动轨迹对不上),而且特别耗时间——哪怕是短视频,也可能要等几小时甚至几天才能出结果。
D4RT的核心突破就是“一体化”:用一套架构搞定所有4D相关任务,不用拼接工具,也不用手动校准。不管是静态场景(比如静止的房间)还是动态场景(比如奔跑的人群、移动的车辆),它都能精准处理,而且速度比传统方案快上百倍,普通电脑也能流畅运行。它由Google DeepMind主导开发,基于深度学习的Transformer架构编程,开源后免费供开发者和企业使用,核心目标是让复杂的4D重建技术“平民化”。
二、功能特色
D4RT的核心优势是“统一、高效、灵活、精准”,具体功能特色可分为6点,覆盖技术架构到实际应用的全需求:
1. 单架构统一多任务,告别“工具拼接”
这是D4RT最核心的亮点。传统4D建模需要部署5-6个专门工具(比如用DepthNet算深度、用Tracker算轨迹、用Calibrator校准相机),还要手动适配不同工具的输出格式,容易出错。而D4RT只需调整“查询参数”(比如“我要某帧的深度图”“我要跟踪某个像素的运动”),就能一站式完成以下所有任务:
3D点云重建:生成场景的3D点云数据(可直接用于3D打印、虚拟建模);
3D轨迹跟踪:跟踪任意像素/物体在整个视频中的运动轨迹,哪怕物体暂时被遮挡也能精准预测;
深度图生成:输出每帧画面中每个像素的“远近信息”(比如画面里的树比房子近多少);
相机参数估计:自动算出拍摄视频时的相机参数(比如焦距、拍摄角度、相机移动轨迹),不用额外校准工具。
2. 查询驱动设计,高效省资源
传统方法会“无差别处理”视频的每帧画面——不管你需要什么信息,都要先把所有像素的所有数据算一遍,特别耗算力(比如一张1080P画面要算200多万个像素)。D4RT采用“查询驱动”模式:你需要什么结果,就只算什么数据(比如只跟踪某个人的运动,就不用处理画面里的背景)。
这种设计带来两个核心好处:一是速度快,推理时可并行计算,在普通GPU上也能实时处理;二是省资源,哪怕是手机级别的设备,也能运行轻量化版本。
3. 动态场景适配性拉满,无死角处理
传统4D工具要么只能处理静态场景(比如拍静止的建筑),要么处理动态场景时会出现“重影”“漏帧”(比如跟踪奔跑的人时,轨迹变成模糊的线条)。D4RT通过“全局时空注意力机制”,能精准捕捉跨帧的物体对应关系(比如第1帧的杯子和第10帧的杯子是同一个),哪怕是快速运动、局部遮挡的场景(比如球赛里的足球、人群中的行人),也能完整重建几何结构和运动轨迹。
4. 精度与速度双顶尖,打破行业瓶颈
D4RT在多个权威数据集(Sintel、ScanNet、TAPVid-3D)上的测试结果显示,它的精度超过了所有传统方案,同时速度快18-300倍:
相机参数估计:在A100显卡上每秒能处理200多帧,比传统的MegaSaM快100倍;
密集像素跟踪:每秒能跟踪4万+个轨迹,比SpatialTrackerV2快300倍;
深度估计:在动态场景中,细节还原度比VGGT高20%,误差降低35%。
5. 灵活适配多场景,不用改代码
D4RT支持“时空解耦”——简单说就是你可以自由设置“从哪帧取数据”“跟踪到哪帧”“用哪个相机视角看”,不用修改核心代码。比如:
想看某个人10秒内的运动轨迹,就固定“起始帧”和“像素位置”,遍历所有时间帧;
想从不同角度看场景,就调整“相机参考系”参数,不用重新处理视频。

三、技术细节
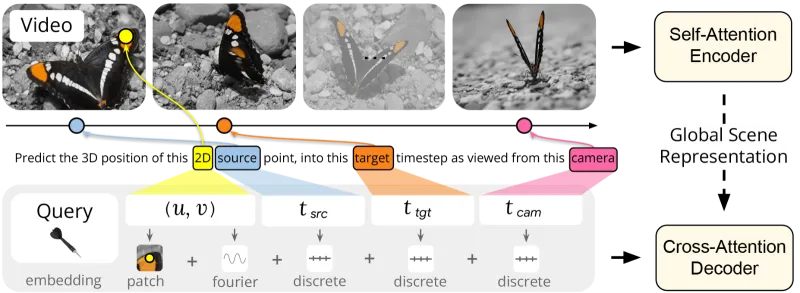
D4RT的核心是“编码器-解码器”架构,再加上创新的“查询机制”,整体设计兼顾了精度和效率。以下用通俗的语言拆解关键技术:
1. 整体架构:编码器(信息处理器)+ 解码器(答案生成器)
D4RT的架构像一个“智能翻译官”:编码器负责把视频的2D像素信息“翻译”成计算机能理解的“全局场景语言”,解码器负责根据用户的“查询需求”,从这种语言里“翻译”出4D结果。
| 模块 | 核心作用 | 通俗解释 |
|---|---|---|
| 编码器 | 输入视频(T帧×H高度×W宽度×3色彩通道),输出“全局场景表示”(N个特征点×C个特征维度) | 把一段视频的所有信息(包括每个像素的颜色、不同帧的关联、物体的形状)整合起来,变成一串“浓缩信息” |
| 解码器 | 接收用户的查询参数,通过交叉注意力从“全局场景表示”中提取目标结果 | 你告诉它“我要第5帧的深度图”,它就从浓缩信息里精准找出这部分数据,生成你要的结果 |
编码器细节:基于视觉Transformer(ViT)改造,加入了“帧内局部注意力”和“全局时空注意力”。前者负责捕捉单帧画面里的局部细节(比如物体的边缘),后者负责捕捉跨帧的关联(比如第1帧和第10帧中同一个物体的位置关系),确保能精准捕捉动态场景的运动规律。
解码器细节:采用轻量级交叉注意力模块,不用重复处理视频数据,只需“查询”编码器生成的“全局场景表示”即可。这种设计大幅降低了计算量,同时保证结果和编码器的信息一致。
2. 核心机制:灵活的查询设计(5个关键参数)
D4RT的“查询机制”是它高效的核心,用户只需设置5个参数,就能实现不同任务,不用改架构:
源帧2D坐标(u,v):你要分析的像素在某一帧的位置(比如第3帧画面中,坐标(100,200)的像素);
源时间步(tsrc):选择“参考帧”(比如以第3帧为基准,分析其他帧的变化);
目标时间步(ttgt):你要输出结果的时间帧(比如想知道第3帧的像素在第10帧的位置,ttgt就设为10);
相机参考系(tcam):选择观察视角(比如用拍摄相机的视角,还是全局统一视角);
局部RGB补丁:额外加入查询点周围9×9的像素颜色信息,提升细节精度(比如还原物体的纹理、边缘)。
举个例子:想生成第5帧的深度图,就设置“tsrc=ttgt=tcam=5”,解码器会直接从全局场景表示中提取第5帧所有像素的3D位置,取Z轴(深度)数据即可;想跟踪某个人的运动,就固定“(u,v)=人物中心坐标、tsrc=第1帧”,遍历ttgt从1到视频总帧数,就能得到完整轨迹。
3. 关键技术:提升精度的3个“小技巧”
局部RGB补丁嵌入:在查询时,额外加入查询点周围9×9的像素颜色信息。这能补充低层级的细节特征(比如物体的纹理、边缘),让深度图和点云的细节更清晰,避免出现“边缘模糊”的问题。
多任务损失函数:训练时同时优化“3D位置误差”“2D对应误差”“表面法向量误差”“运动位移误差”等多个指标,让模型在不同任务上都能精准。比如“置信度损失”专门优化相机参数估计,让校准精度提升40%。
编码器规模适配:支持从ViT-B(基础版)到ViT-g(10亿参数版)的不同规模编码器。普通场景用ViT-B就能满足需求,对精度要求高的场景(比如影视制作)换用ViT-g,深度估计误差能再降低25%。
4. 任务实现逻辑(不用写代码,改参数就行)
D4RT的所有任务都通过“调整查询参数”实现,核心逻辑如下:
3D点云重建:所有像素用同一个相机参考系查询3D位置,直接输出点云数据,不用额外坐标转换;
3D轨迹跟踪:固定(u,v,tsrc),遍历ttgt从1到T,得到同一个像素在不同时间的3D位置,连成轨迹;
深度图生成:设置tsrc=ttgt=tcam,取3D输出的Z轴数据,就是深度图;
相机参数估计:用网格采样查询不同位置的3D数据,通过Umeyama算法计算相机的内外参(外参是拍摄角度,内参是焦距)。
四、应用场景
D4RT的适配性极强,覆盖工业、影视、消费电子等多个领域,以下是最核心的6个应用场景:
1. 机器人导航与避障
机器人要在动态环境中(比如商场、街道)自主移动,需要实时知道周围物体的3D形状和运动轨迹(比如迎面走来的人、行驶的车)。D4RT能实时处理机器人摄像头拍摄的视频,输出周围环境的4D模型,让机器人精准判断障碍物位置和运动方向,避免碰撞。
优势:比传统激光雷达方案成本低(不用额外装雷达),速度快(实时处理),适合服务机器人、仓储机器人。
2. 影视制作与特效
在电影、游戏制作中,常需要把真人动作转化为3D角色动作(比如科幻片里的外星生物动作),传统方法需要演员穿动捕服,成本高。D4RT只需一段普通视频,就能重建演员的3D骨骼和运动轨迹,直接导入建模软件生成特效,大幅降低制作成本。
案例:用D4RT处理一段舞蹈视频,能精准还原舞者的肢体动作轨迹,生成可直接用于游戏的3D动作数据。
3. 增强现实(AR)/虚拟现实(VR)
AR技术需要把虚拟物体(比如手机屏幕上的虚拟杯子)和现实场景精准融合(比如放在真实桌子上),这就需要知道现实场景的3D结构和相机位置。D4RT能实时处理手机摄像头的视频,输出现实场景的4D模型和相机参数,让虚拟物体“贴”在现实场景上,不会出现错位。
应用:AR导航(虚拟箭头贴在真实路面)、VR虚拟场景生成(把真实房间转化为VR场景)。
4. 自动驾驶感知
自动驾驶汽车需要实时感知周围环境的动态变化(比如行人横穿马路、前车刹车)。D4RT能处理车载摄像头的视频,输出周围车辆、行人、障碍物的3D位置和运动轨迹,帮助汽车判断风险(比如计算行人横穿的时间,提前刹车)。
优势:比纯视觉方案精度高,比激光雷达方案成本低,可作为自动驾驶感知系统的核心模块。
5. 工业检测与维修
在工厂里,需要检测设备的运动是否正常(比如流水线的传送带速度、机械臂的运动轨迹)。D4RT能处理设备运行的视频,重建机械臂的3D运动轨迹,和标准轨迹对比,找出偏差(比如机械臂偏移1毫米),提前预警故障;同时还能重建设备的3D结构,帮助维修人员远程查看设备内部细节(比如管道的3D形状)。
6. 安防监控与行为分析
安防监控需要跟踪可疑人员的运动轨迹(比如在商场里徘徊的人)。D4RT能处理监控视频,精准跟踪多个人员的3D轨迹,哪怕人员相互遮挡也能区分,同时输出人员的身高、体型等3D信息,帮助警方快速识别目标。
五、常见问题解答(FAQ)
1. 运行时提示“缺少依赖”怎么办?
答:首先检查是否按步骤安装了所有依赖,尤其是PyTorch的版本是否匹配(建议用1.18及以上版本)。如果提示“找不到某模块”(比如cv2),直接用pip install 模块名(比如pip install opencv-python)安装即可。
2. 处理视频时速度很慢,怎么优化?
答:有3种优化方式:① 安装带CUDA的PyTorch,开启GPU加速(最有效);② 降低输入视频的分辨率(比如把1080P改为720P);③ 用轻量化模型(比如ViT-B版本,比ViT-g快5倍)。
3. 输出的3D模型有误差(比如物体形状扭曲),怎么解决?
答:首先检查输入视频是否清晰(模糊视频会导致精度下降);其次,更换更大型的预训练模型(比如用ViT-g代替ViT-B);最后,可在配置文件中开启“局部RGB补丁”功能(use_local_patch: True),能提升细节精度。
4. 支持中文路径吗?
答:目前官方版本对中文路径支持不完善,建议把输入视频、模型文件放在无中文、无空格的路径下(比如D:/d4rt/input/test.mp4,不要用D:/D4RT/输入/测试.mp4)。
六、相关链接
七、总结
D4RT是Google DeepMind推出的一款开源4D重建与跟踪框架,核心价值在于用单架构统一解决动态场景的4D建模全流程,打破了传统方法多工具拼接、计算繁琐、精度与速度难以兼顾的瓶颈。它通过创新的查询驱动设计,实现了点云重建、轨迹跟踪、深度估计等多任务的一站式处理,精度与速度均达行业顶尖水平,且部署简单、术语本地化友好,大幅降低了4D技术的应用门槛。无论是机器人导航、影视制作等工业级场景,还是AR/VR等消费级场景,D4RT都能提供稳定、高效的解决方案,是当前开源领域最值得关注的4D重建工具之一。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/d4rt.html





