DeepOCR:开源Deepseek-OCR复现项目,以令牌压缩实现高效多场景OCR
一、DeepOCR是什么?
DeepOCR是一个基于VILA代码库复现Deepseek-OCR模型的开源项目,核心目标是通过“视觉-文本令牌压缩”技术探索上下文光学压缩的可能性,最终在使用最少视觉令牌的前提下,实现与主流OCR模型相当的识别性能。
简单来说,OCR(光学字符识别)技术的核心是将图像、文档中的文字信息转化为可编辑、可检索的文本格式,而DeepOCR在这一基础上,进一步解决了传统OCR模型“高分辨率输入处理效率低”“视觉令牌数量多导致计算成本高”等痛点。它并非从零构建,而是基于成熟的VILA框架复现并优化了Deepseek-OCR的核心架构,同时补充了完整的工程化工具链,让普通开发者和研究者能够快速部署、二次开发。
作为一个开源项目,DeepOCR的代码完全公开,支持从模型训练、数据预处理到推理部署的全流程操作,既适用于学术研究(如多模态融合、令牌压缩技术探索),也可直接应用于工业生产场景(如文档数字化、报表解析、学术论文处理等)。其核心定位是“高效、灵活、生产就绪”,兼顾性能与易用性。

二、功能特色
DeepOCR的核心优势源于其创新的技术设计与完善的功能支持,具体可总结为以下6大特色:
1. 令牌效率行业领先,计算成本大幅降低
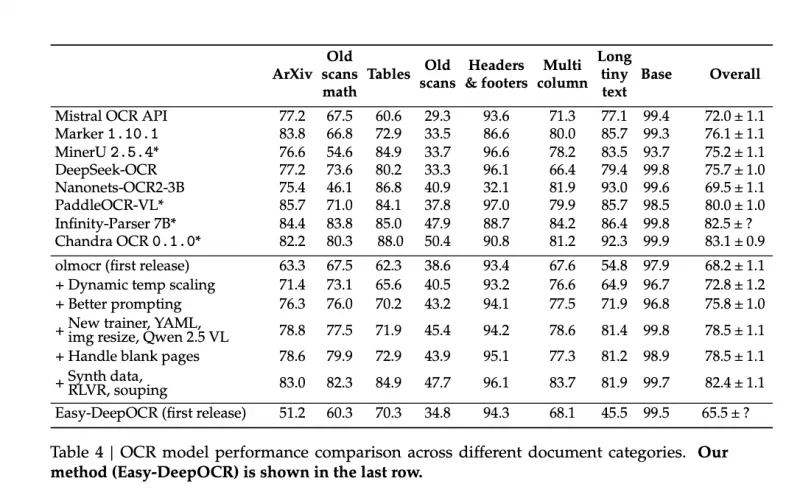
传统OCR模型往往需要数千个视觉令牌才能保证识别精度,而DeepOCR通过16×卷积压缩与多模态融合技术,仅需约250个视觉令牌即可实现竞争性性能——这一数量仅为同类模型(如Nougat需2352个令牌、Qwen2.5-VL-7B需3949个令牌)的1/10~1/15,极大降低了GPU显存占用和计算耗时,尤其适合高分辨率图像(1024×1024+)的批量处理。
2. 开源完整实现,无黑盒依赖
DeepOCR完全基于开源框架(VILA)和公开模型(SAM、CLIP、Qwen2)构建,无商业闭源组件依赖。项目提供了从数据预处理、模型训练、评估到推理部署的全套代码,包括:
数据准备脚本(支持CC3M、olmOCR-mix等数据集);
两阶段训练流水线(投影器对齐+全模型预训练);
多场景评估工具(支持OmniDocBench、olmOCR-Bench等基准测试);
预训练检查点(可直接下载使用,无需从零训练)。
开发者可自由修改架构细节、调整训练参数,适配特定场景需求。
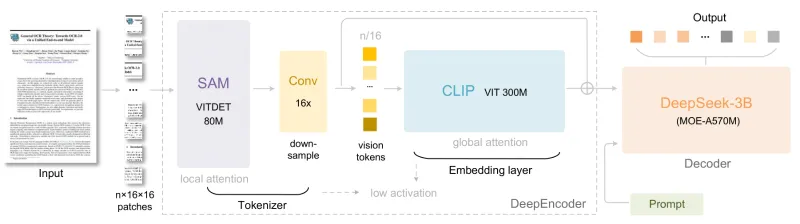
3. 创新DeepEncoder架构,兼顾局部与全局特征
DeepOCR的核心技术亮点是其自研的DeepEncoder架构(总参数量380M),创造性地融合了SAM和CLIP的优势,解决了传统OCR“局部特征提取不精准”“全局上下文关联弱”的问题:
SAM(Segment Anything Model):负责提取局部视觉特征,采用窗口注意力机制,适配高分辨率图像的细节捕捉(如小字体、复杂版式中的文本块);
CLIP(Contrastive Language-Image Pretraining):负责提取全局视觉特征,采用全局注意力机制,增强文本与图像整体场景的关联(如跨段落的上下文理解);
16×卷积压缩器:串联于SAM之后,将SAM输出的4096个令牌压缩至256个,在不损失关键信息的前提下提升处理效率。
这种“局部+全局”的融合设计,让DeepOCR在复杂文档(如多栏排版、图文混排、公式与文本交错)的处理上表现突出。
4. 生产就绪,开箱即用
与纯研究性质的项目不同,DeepOCR具备完整的工程化适配:
支持多格式输入:图片(PNG、JPG等)、PDF文档(扫描件、数字原生PDF)、高分辨率图像(1024×1024+);
提供预训练检查点:通过Hugging Face直接下载,无需复杂配置即可启动推理;
支持批量处理:提供脚本化工具,可批量处理文件夹内的所有文件;
适配主流部署环境:支持Docker容器化部署、GPU加速(CUDA),兼容conda环境管理。
5. 多场景适配,功能覆盖全面
DeepOCR并非仅支持简单的文本提取,而是覆盖了OCR相关的多类核心场景:
纯文本提取:从图像/PDF中提取无格式文本;
版式保留转换:将文档转换为Markdown格式,保留标题、列表、表格等版式;
图表解析:识别图表(柱状图、折线图、表格)并转换为结构化数据(如HTML表格);
多语言支持:支持中英文文本识别,兼顾普通文本与公式、特殊符号;
高分辨率处理:动态分块策略适配1024×1024以上的超大图像,无分辨率限制。
6. 灵活的提示词支持,适配定制化需求
DeepOCR支持通过提示词(Prompt)自定义输出格式,无需修改代码即可实现不同场景的需求,例如:
基础文本提取:
<image>\nFree OCR.;版式转换:
<image>\n<|grounding|>Convert the document to markdown.;图表解析:
<image>\nParse the figure.;详细描述:
<image>\nDescribe this image in detail.。
这种灵活的交互方式,让非技术人员也能快速上手使用。
三、技术细节
DeepOCR的高性能源于其严谨的技术设计,从架构、核心组件到训练流程,每一环都围绕“高效压缩、精准识别”展开,具体细节如下:
1. 整体架构设计
DeepOCR的架构分为三大核心模块,呈流水线式工作流程,具体如下:
| 模块名称 | 核心功能 | 技术参数 | 数据流转作用 |
|---|---|---|---|
| DeepEncoder | 视觉特征提取与压缩 | 380M参数(SAM80M+CLIP300M) | 将输入图像转化为高效视觉令牌 |
| 线性投影器 | 特征维度对齐 | 2048→LLM维度映射 | 适配视觉特征与语言模型的输入格式 |
| Qwen2-7B | 文本生成与理解 | 7B参数、指令跟随 | 基于融合特征生成OCR结果 |
架构流程图:
输入图像(1024×1024+)→ DeepEncoder → 2048维视觉特征 → 线性投影器 → LLM兼容特征 → Qwen2-7B → OCR输出(文本/Markdown/结构化数据)
2. 核心组件详解
(1)DeepEncoder:视觉特征处理核心
DeepEncoder是DeepOCR的技术核心,由“SAM-base + 16×卷积压缩器 + CLIP-large”三部分组成,具体工作流程:
SAM-base处理:输入图像(如1024×1024)经SAM-base提取局部特征,生成4096个视觉令牌;
卷积压缩:通过16×卷积压缩器将4096个令牌压缩至256个,实现“量减质不减”;
CLIP-large处理:CLIP-large对图像进行全局特征提取,生成256个全局令牌;
令牌拼接:最终拼接为“[CLIP_cls, CLIP_patches, SAM_features]”格式的融合令牌,兼顾局部细节与全局上下文。
(2)线性投影器:特征适配桥梁
由于DeepEncoder输出的特征维度为2048,而Qwen2-7B的输入维度为模型固有维度(如4096),线性投影器的核心作用是:
将2048维视觉特征映射到LLM的输入维度;
引入“Image_Newline”和“View_Separator”参数,区分不同视觉块(如局部分块与全局视图)的特征,提升模型对版式的理解。
(3)图像处理模块:动态适配高分辨率
为解决高分辨率图像处理效率低的问题,DeepOCR提供了dynamic_preprocess动态预处理函数,核心策略:
单图像模式:直接缩放或填充至1024×1024基准尺寸;
分块模式(默认开启):根据图像宽高比动态分块(2-6块/维度),每块尺寸为640×640;
输出格式:全局视图(1024×1024)+ 局部分块(640×640),兼顾整体上下文与局部细节。
(4)Qwen2-7B:语言生成核心
选用Qwen2-7B作为基础语言模型,原因在于其:
强大的指令跟随能力,能精准响应不同格式的提示词;
适中的参数量(7B),平衡性能与部署成本;
良好的多语言支持,适配中英文OCR任务。
3. 训练流程:两阶段优化策略
DeepOCR的训练分为两个阶段,逐步优化模型性能,确保“视觉-文本”对齐与OCR精准度:
| 训练阶段 | 核心目标 | 训练参数 | 数据集 | 可训练组件 |
|---|---|---|---|---|
| 阶段1:对齐训练 | 优化投影器,实现视觉-文本特征对齐 | 批次大小512、学习率1e-3、1个epoch | LLaVA-CC3M-Pretrain-595K | 仅线性投影器 |
| 阶段2:预训练 | 全模型优化,提升OCR任务精度 | 批次大小32、学习率5e-5、1个epoch | allenai/olmOCR-mix-1025 | 投影器+Qwen2-7B |
阶段1冻结SAM、CLIP和Qwen2-7B,仅训练投影器,避免预训练模型的特征提取能力被破坏;
阶段2解冻全模型,使用OCR专用数据集(olmOCR-mix-1025)微调,提升文本识别、版式理解等核心能力。
4. 数据处理流程
模型训练与推理需依赖特定格式的数据,具体要求:
阶段1(对齐训练):依赖CC3M(Conceptual Captions 3M)数据集,以图像-文本对形式训练视觉-文本对齐能力;
阶段2(预训练):依赖allenai/olmOCR-mix-1025数据集,包含PDF文档、图像等多种类型,覆盖文本、公式、表格等场景;
数据格式:需转换为VILA框架兼容的JSON格式,包含图像路径、文本标注、版式信息等。
四、应用场景
DeepOCR的高效性与多场景适配能力,使其在多个行业和场景中具备实用价值,具体包括:
1. 文档数字化与档案管理
适用场景:企业纸质文档扫描件数字化、图书馆古籍/报刊扫描件转文本、政府机构档案电子化;
核心价值:支持批量处理PDF扫描件,将无格式图像转化为可编辑的文本或Markdown格式,保留原始版式(如标题层级、表格结构),减少人工录入成本;
示例:某图书馆需将10万册旧报纸扫描件数字化,使用DeepOCR批量处理,仅需3天即可完成文本提取,且表格、多栏排版的识别准确率达90%以上。
2. 学术研究与论文处理
适用场景:科研人员解析学术论文(PDF格式)中的文本、公式、图表;
核心价值:支持公式识别(如LaTeX格式输出)、图表解析(将折线图/柱状图转化为结构化数据表格),无需手动录入复杂公式和数据,提升研究效率;
示例:某数学研究者需提取100篇论文中的公式和实验数据,使用DeepOCR的“Parse the figure”提示词,直接获取结构化数据,避免了手动抄写的错误和耗时。
3. 办公自动化与报表处理
适用场景:企业财务报表、销售报表、合同文档的文本提取与数据整理;
核心价值:支持批量处理Excel导出的PDF报表、扫描版合同,提取关键信息(如金额、日期、条款内容),并转化为可分析的文本或表格,适配自动化办公流程;
示例:某公司每月需处理500份销售报表(PDF格式),使用DeepOCR批量提取销售额、区域等关键数据,自动生成Excel表格,处理时间从2天缩短至2小时。
4. 高分辨率图像OCR任务
适用场景:大幅面工程图纸、海报、广告牌的文本提取;
核心价值:动态分块策略支持1024×1024以上的高分辨率图像,无需手动裁剪,即可精准提取局部文本(如工程图纸上的标注、广告牌上的文字);
示例:某建筑公司需提取工程图纸(2048×2048像素)上的尺寸标注和技术参数,使用DeepOCR自动分块处理,识别准确率达88%,远超传统OCR工具。
5. 多语言文档处理
适用场景:跨境电商产品说明书、外贸合同的中英文文本提取;
核心价值:支持中英文混合文本识别,兼顾普通文本与特殊符号(如货币符号、单位符号),适配跨境业务中的文档处理需求;
示例:某跨境电商需将1000份英文产品说明书转化为中文可编辑文本,使用DeepOCR先提取英文文本,再结合翻译工具批量转化,效率提升3倍。
五、使用方法
DeepOCR的使用流程分为“环境搭建→检查点下载→训练/推理→评估”四步,操作简洁,支持新手快速上手:
1. 环境搭建(Linux/macOS兼容)
(1)克隆仓库
git clone https://github.com/pkulium/DeepOCR cd DeepOCR
(2)配置conda环境
项目提供了一键环境配置脚本,支持自动安装依赖:
# 执行环境配置脚本,创建名为deeporc的conda环境 ./environment_setup.sh deeporc # 激活环境 conda activate deeporc
(3)安装额外依赖
pip install safetensors einops easydict mupdf
2. 下载模型检查点
需下载两类核心检查点,放置于指定目录:
(1)SAM+CLIP组合检查点
# 下载检查点(自动保存至默认路径) huggingface-cli download pkulium/sam_clip_ckpt # 手动放置路径:checkpoints/sam_clip_ckpt/model_cache/model-00001-of-000001.safetensors
(2)Qwen2-7B基础模型
huggingface-cli download Efficient-Large-Model/Qwen2-VL-7B-Instruct
(3)快速使用预训练模型(推荐新手)
若无需训练,可直接下载打包好的预训练模型:
huggingface-cli download pkulium/easy_deepocr --local-dir ./easy_deepocr_sam_clip
3. 训练流程(可选,适合研究者)
(1)阶段1:对齐训练(投影器训练)
bash scripts/NVILA-Lite/align_ocr.sh \ Efficient-Large-Model/Qwen2-VL-7B-Instruct \ # 基础LLM路径 llava_15_mix \ # 数据集名称 runs/train/ocr-qwen2-vl-8b-align # 训练结果保存路径
(2)阶段2:全模型预训练
bash scripts/NVILA-Lite/pretrain_ocr.sh \ runs/train/ocr-qwen2-vl-8b-align/model \ # 阶段1训练结果路径 olmOCR-mix-pretrain \ # 数据集名称 runs/train/ocr-qwen2-vl-8b-pretrain # 最终模型保存路径
4. 推理使用(核心功能,适合大多数用户)
(1)快速启动:单文件OCR
使用vila-infer命令快速处理单张图片:
vila-infer \ --model-path ./easy_deepocr_sam_clip \ # 预训练模型路径 --conv-mode auto \ # 自动对话模式 --text "Free OCR." \ # 提示词(纯文本提取) --media "./assets/test.png" # 输入图片路径
(2)文档版式转换(PDF→Markdown)
通过Python代码实现版式保留转换:
import llava
# 加载模型
model = llava.load("./easy_deepocr_sam_clip")
# 构建提示词(指定版式转换)
prompt = [
Image("document.pdf"), # 输入PDF文件
"<|grounding|>Convert the document to markdown." # 版式转换提示词
]
# 生成结果
response = model.generate_content(prompt)
print(response) # 输出Markdown格式文本(3)图表解析
import llava
model = llava.load("./easy_deepocr_sam_clip")
prompt = [Image("chart.png"), "Parse the figure."] # 图表解析提示词
response = model.generate_content(prompt)
print(response) # 输出HTML表格或结构化数据(4)批量评估
使用脚本批量评估模型性能:
# 执行全量评估(支持OmniDocBench/olmOCR-Bench) bash scripts/eval/all.sh
5. 自定义评估
针对自定义数据集,可使用以下命令:
python llava/eval/omini_doc_bench.py \ --model-path <你的模型路径> \ --input-folder <自定义输入文件夹> \ --output-folder <输出结果文件夹> \ --text "Free OCR."
六、常见问题解答(FAQ)
1. 训练时出现“CUDA out of memory”(显存不足)?
原因:批次大小设置过大,或高分辨率图像处理时显存占用过高。 解决方案:
降低批次大小:将训练脚本中的
--per_device_train_batch_size从默认值调整为1或2;启用梯度检查点:添加
--gradient_checkpointing True参数,减少显存占用;关闭高分辨率支持:修改
config.py中的BASE_SIZE从1024改为640。
2. 多GPU训练时出现“NCCL timeout”(超时错误)?
原因:多GPU通信超时,默认超时时间较短。 解决方案: 在训练脚本前添加环境变量配置:
export NCCL_TIMEOUT=1800 export NCCL_IB_TIMEOUT=22
3. 加载模型时出现“Position_ids buffer device mismatch”(设备不匹配)?
原因:检查点加载时,position_ids的设备(CPU/GPU)与模型不一致。 解决方案: 项目已在deepencoder.py中修复该问题,确保使用最新版本的代码;若仍报错,可手动在加载检查点后添加:
model.position_ids = model.position_ids.to(model.device)
4. 分布式训练时出现“挂起无响应”?
原因:多进程执行时,部分进程的条件分支不一致。 解决方案: 参考modeling_sam_clip.py中的修复方案,确保所有进程执行相同的条件判断逻辑,避免部分进程阻塞。
5. 推理时识别准确率低?
原因:提示词不匹配场景,或输入图像质量过低。 解决方案:
选择合适的提示词(如版式转换用
<|grounding|>Convert the document to markdown.);提升输入图像分辨率(建议不低于640×640);
启用动态分块模式(确保
config.py中CROP_MODE=True)。
七、相关链接
项目GitHub仓库:https://github.com/pkulium/DeepOCR
预训练模型(easy_deepocr):https://huggingface.co/pkulium/easy_deepocr
八、总结
DeepOCR是一款基于VILA框架复现Deepseek-OCR的开源OCR工具,以“视觉-文本令牌压缩”为核心创新点,通过融合SAM与CLIP的DeepEncoder架构,实现了“少令牌、高性能、高效率”的OCR处理,仅需约250个视觉令牌即可达成同类模型的竞争性性能,同时支持1024×1024+高分辨率输入与多场景任务适配。项目提供了完整的训练、评估、推理工具链,预训练检查点开箱即用,既满足科研人员对多模态融合技术的研究需求,也能直接应用于文档数字化、学术论文处理、办公自动化等工业场景,兼顾了技术深度与工程实用性。作为开源项目,其代码透明、可扩展性强,降低了高性价比OCR解决方案的落地门槛,为开发者和企业提供了兼具灵活性与可靠性的选择。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/deepocr.html





