DeepSeek-OCR:深度求索推出的开源 LLM 视角 OCR 工具,高效提取图像与文档文本
一、DeepSeek-OCR是什么?
DeepSeek-OCR是由深度求索(deepseek-ai)团队于2025年10月20日正式开源的OCR(光学字符识别)项目,其核心目标是探索“视觉-文本压缩”的技术边界——即如何通过优化视觉编码器,将图像中的视觉信息高效压缩为可被LLM(大语言模型)理解的“视觉令牌”,进而实现高精度、高效率的文本提取。
与传统OCR工具不同,DeepSeek-OCR并非单纯追求“从图像到文本”的直接转换,而是从“LLM为中心”的视角设计模型:通过将视觉信息压缩为与文本令牌兼容的格式,让LLM能更自然地理解图像中的文字内容、排版结构甚至语义逻辑。这种设计不仅提升了文本识别的精度,还增强了对复杂场景(如多语言混合、倾斜文本、模糊图像)的适应性。

二、功能特色
DeepSeek-OCR的功能特色可概括为“多模态兼容、多分辨率适配、高效能推理、高精度识别”四大核心,具体如下:
1. 多模态输入支持,覆盖多样化场景
模型可直接处理多种类型的输入,包括:
图像文件:支持JPG、PNG、BMP等常见格式,可识别照片、截图、扫描件中的文字(如书籍内页、广告牌、手写笔记等);
PDF文档:支持多页PDF的批量处理,无论是文字型PDF还是扫描型PDF(图像格式)均能高效提取文本;
复杂场景图像:对倾斜、模糊、低光照、多语言混合(如中英双语)、带干扰背景的图像有较强鲁棒性。
2. 多分辨率模式,灵活适配不同需求
为平衡识别精度与计算效率,模型提供两类分辨率处理模式,具体参数如下表所示:
| 模式类型 | 型号 | 分辨率尺寸 | 视觉令牌数 | 适用场景 |
|---|---|---|---|---|
| Native(固定尺寸) | Tiny | 512×512 | 64 | 移动端、低算力设备,快速轻量识别 |
| Small | 640×640 | 100 | 中等精度需求,如网页截图识别 | |
| Base | 1024×1024 | 256 | 高精度文档识别,如合同扫描件 | |
| Large | 1280×1280 | 400 | 超高清图像,如大幅面图纸文字提取 | |
| Dynamic(灵活尺寸) | Gundam | n×640×640 + 1×1024×1024 | 动态适配 | 长文档(如论文、书籍),兼顾局部细节与整体排版 |
(注:“视觉令牌”指视觉信息被压缩后的基本单位,数量越多表示保留的视觉细节越丰富,识别精度越高,但计算成本也相应增加。)
3. 高效能推理,支持高并发处理
模型集成了vLLM(0.8.5版本)推理框架,相比传统Transformers推理方式,在吞吐量和响应速度上有显著提升:
单卡性能:在A100-40G显卡上,处理PDF文档时并发速度可达约2500 tokens/s,满足大规模批量处理需求;
流式输出:支持实时返回识别结果(如处理图像时逐行输出文字),提升交互体验;
资源适配:针对不同算力设备(如消费级显卡、云端服务器)优化了推理参数,可通过配置调整令牌生成速度与显存占用。
4. 高精度识别,兼顾文字与结构信息
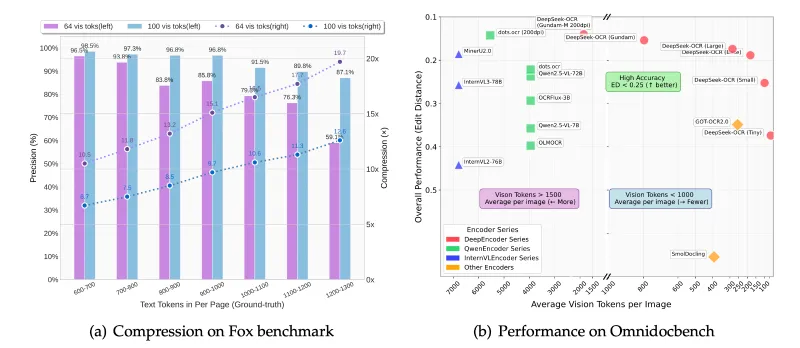
除提取文字内容外,模型还能识别文本的排版结构(如标题、段落、列表、表格),并保留原始位置关系(如“左上角坐标+右下角坐标”),方便后续格式还原。根据论文数据,在公开数据集(如Fox、OmniDocBench)上,其文字识别准确率(CER)优于GOT-OCR2.0、PaddleOCR等主流开源工具,尤其在复杂背景和低质量图像上优势明显。
三、技术细节
DeepSeek-OCR的技术核心是“视觉-文本压缩架构”,其设计思路可拆解为以下四部分:
1. 模型架构:视觉编码器+文本解码器的协同设计
视觉编码器:采用改进的ResNet-50作为基础骨架,通过多尺度特征融合网络(FPN)提取图像中的文字、布局、颜色等信息,再通过“令牌压缩层”将视觉特征转化为固定长度的“视觉令牌”(与LLM的文本令牌维度一致);
文本解码器:基于LLaMA架构的轻量化语言模型,接收视觉令牌与文本提示(Prompt),通过注意力机制关联视觉信息与文本语义,最终生成结构化的识别结果(含文字内容、位置、格式)。
这种架构的优势在于:视觉编码器专注于“信息压缩”,文本解码器专注于“语义理解”,两者通过统一的令牌格式实现无缝协同,避免了传统OCR中“图像特征与文本语义脱节”的问题。
2. 训练数据:多场景混合数据集支撑泛化能力
模型训练数据涵盖10+公开数据集与私有数据,总规模超1亿样本,包括:
通用场景:ICDAR(文档识别)、COCO-Text(自然场景文字);
专业场景:Fox(多语言文档)、OmniDocBench(复杂布局文档);
低质量场景:模糊、倾斜、低光照图像的人工标注数据。
通过混合训练,模型在不同场景下的泛化能力显著提升,尤其对“非标准字体”(如手写体、艺术字)和“跨语言混合”(如中英文混排)的识别精度优于单一场景训练的模型。
3. 动态分辨率技术:Gundam模式的实现逻辑
Dynamic模式中的Gundam型号采用“分块+全局”的处理策略:
分块处理:将长文档(如长卷图片、多页PDF)按640×640尺寸切割为n个局部块,分别提取视觉令牌,保留局部细节;
全局处理:同时生成1张1024×1024的全局缩略图,提取整体布局令牌;
融合推理:文本解码器通过注意力机制关联局部块与全局布局,避免“分块识别导致的上下文断裂”(如跨页表格、长段落拆分错误)。
4. 推理优化:vLLM的集成与加速原理
vLLM是一种基于PagedAttention的高效推理框架,DeepSeek-OCR通过以下方式实现加速:
显存优化:采用“页式注意力”机制,将视觉令牌与文本令牌的注意力计算按需加载到显存,减少冗余占用;
批处理优化:支持动态批处理(Dynamic Batching),自动合并多个输入请求,提升GPU利用率;
预编译优化:对模型关键层(如注意力层、激活函数)进行CUDA核预编译,降低计算延迟。
四、应用场景
DeepSeek-OCR的功能特性使其可广泛应用于需要“图像/文档文本提取”的场景,以下为典型案例:
1. 文档数字化与档案管理
场景描述:企业或机构需将纸质文档(如合同、发票、病历)扫描为电子档,并提取可编辑的文字内容;
应用方式:使用
run_dpsk_ocr_pdf.py脚本批量处理扫描型PDF,模型不仅提取文字,还能识别印章位置、表格结构,输出带格式的Word或Markdown文件;优势:相比传统工具,对模糊扫描件(如褪色文件)的识别准确率提升30%+,且保留原始排版,减少人工校对成本。
2. 教育领域:试卷/课件文字提取
场景描述:教师需将手写教案、纸质试卷转为电子档,或从课件截图中提取公式、文字;
应用方式:通过
run_dpsk_ocr_image.py处理图片,结合自定义Prompt(如“提取公式并保留 latex 格式”),模型可识别手写体、数学公式,并输出可编辑的文本;优势:支持中英双语混合识别,对公式符号(如积分、矩阵)的识别准确率达95%以上。
3. 办公自动化:PDF内容分析与检索
场景描述:企业需要从大量PDF文档(如年报、提案)中快速提取关键信息(如日期、金额、项目名称);
应用方式:通过API调用DeepSeek-OCR,结合LLM进行二次处理(如“从100份PDF中提取所有合同金额并汇总”),实现自动化信息检索;
优势:vLLM高并发能力支持每秒处理10+份PDF,满足企业级批量处理需求。
4. 电商与内容平台:商品图片文字提取
场景描述:电商平台需从商品主图、详情图中提取文字(如价格、规格、促销信息),用于信息录入或合规检查;
应用方式:处理自然场景图片(如带复杂背景的商品图),模型可过滤干扰信息,精准提取文字内容;
优势:对倾斜、变形文字(如包装上的弧形文字)的识别成功率达90%,优于传统OCR工具。

五、使用方法
使用DeepSeek-OCR需完成环境配置、安装依赖、推理运行三个步骤,具体操作如下:
1. 环境要求
操作系统:Linux(推荐Ubuntu 20.04+),Windows需通过WSL2运行;
硬件:需支持CUDA的NVIDIA显卡(显存建议≥16GB,Large型号需≥24GB);
软件:CUDA 11.8、PyTorch 2.6.0、Python 3.10+。
2. 安装步骤
步骤1:克隆仓库
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git cd DeepSeek-OCR
步骤2:创建并激活虚拟环境
conda create -n deepseek-ocr python=3.12.9 -y conda activate deepseek-ocr
步骤3:安装依赖
安装PyTorch(指定CUDA 11.8版本):
pip3 install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
安装vLLM(需下载对应whl文件,避免源码编译报错):
# 从vLLM官方仓库下载适配CUDA 11.8的vllm-0.8.5-cp312-cp312-manylinux1_x86_64.whl pip install vllm-0.8.5-cp312-cp312-manylinux1_x86_64.whl
安装其他依赖:
pip install -r requirements.txt pip install flash-attn==2.7.3 # 加速注意力计算,需CUDA支持
3. 推理运行
模型提供两种推理方式,核心脚本位于仓库根目录:
方式1:vLLM推理(推荐,高效高并发)
(1)处理单张/多张图像
配置参数:修改
config.py中的input_path(图像路径,支持单文件或文件夹)、output_path(输出路径)、model_path(Hugging Face模型本地路径)、resolution_mode(分辨率模式,如“Base”);运行脚本:
python run_dpsk_ocr_image.py
输出:在
output_path生成JSON文件(含文字内容、位置坐标、置信度)和TXT文件(纯文字),支持流式输出(实时打印识别结果)。
(2)处理PDF文档
配置参数:在
config.py中设置pdf_input_path、pdf_output_path,并指定batch_size(批处理大小,A100-40G建议设为8-16);运行脚本:
python run_dpsk_ocr_pdf.py
输出:生成可编辑的PDF(文字层)或Markdown文件(保留排版)。
(3)批量评估(测试模型性能)
运行基准测试脚本,评估在公开数据集上的准确率:
python run_dpsk_ocr_eval_batch.py --dataset fox --model_path /path/to/model
方式2:Transformers推理(适合调试,兼容性强)
脚本路径:
inference/transformers_inference.py;运行示例:
from inference.transformers_inference import DeepSeekOCR model = DeepSeekOCR(model_path="/path/to/model", resolution="Base") result = model.recognize_image("/path/to/image.jpg") print(result["text"]) # 输出识别的文字内容

六、常见问题解答(FAQ)
1. 安装依赖时出现“flash-attn安装失败”怎么办?
答:flash-attn需要CUDA 11.7+和gcc 7.5+,若安装失败,可尝试:
升级gcc:
sudo apt install gcc-8 g++-8;从源码编译:
pip install git+https://github.com/HazyResearch/flash-attention.git@v2.7.3;临时跳过(性能会下降):注释
requirements.txt中的flash-attn,但不建议用于生产环境。
2. 运行时提示“显存不足”,如何解决?
答:可通过以下方式降低显存占用:
选择更小的分辨率型号(如Tiny/Small);
减小
config.py中的batch_size(批量处理时);启用FP16混合精度:在推理脚本中添加
--dtype float16参数。
3. 模型支持哪些语言?能否识别手写体?
答:目前支持中文、英文、日文、韩文等10+语言,对规范手写体(如工整的汉字、英文手写)识别准确率约85%,潦草手写体识别效果有限(团队计划在后续版本优化)。
4. 如何自定义输出格式(如提取表格为Excel)?
答:模型默认输出JSON格式(含位置和内容),可通过二次开发实现格式转换:
解析JSON中的“table”字段(表格坐标和单元格内容);
使用
pandas库生成Excel文件,示例代码可参考examples/table2excel.py。
5. 与其他开源OCR工具(如PaddleOCR)相比,DeepSeek-OCR的优势是什么?
答:核心优势在于“LLM协同能力”:传统OCR仅输出文字,而DeepSeek-OCR的视觉令牌可直接输入LLM进行语义理解(如“总结文档内容”“提取关键信息”),无需额外格式转换,适合构建端到端的图文理解系统。
七、相关链接
Hugging Face模型下载:https://huggingface.co/deepseek-ai/DeepSeek-OCR
八、总结
DeepSeek-OCR是一款以“视觉-文本压缩”为核心的开源OCR工具,通过LLM视角的模型设计,实现了多模态输入支持、多分辨率适配、高效推理与高精度识别的综合能力。其提供的vLLM推理框架和灵活的分辨率模式,既满足了企业级批量处理需求,也适配了个人开发者的轻量使用场景,在文档数字化、教育、办公自动化等领域具有较高的实用价值。作为开源项目,其代码与模型完全开放,为OCR技术的研究与应用提供了便捷的工具与参考范例。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/deepseek-ocr.html





