HunyuanImage-3.0:腾讯混元开源的原生多模态图像生成模型,兼顾超高性能与智能推理
一、HunyuanImage-3.0是什么?
HunyuanImage-3.0是腾讯混元团队推出的原生多模态图像生成模型,核心定位是“统一多模态理解与生成的自回归框架工具”。与传统基于DiT(Diffusion Transformer)的图像生成模型不同,它突破性地采用“单架构整合多模态能力”设计,将文本理解、语言建模与图像生成功能融入同一自回归框架,无需拆分模块即可实现从文本输入到视觉输出的端到端生成。
该模型于2025年9月28日正式开源,同步发布了推理代码、基础模型权重及技术报告;10月30日推出vLLM加速版本,大幅提升推理效率。作为目前最大的开源图像生成MoE模型,其总计800亿参数中,每个token会激活130亿参数参与运算,既保证了模型的能力深度,又兼顾了推理的效率平衡。
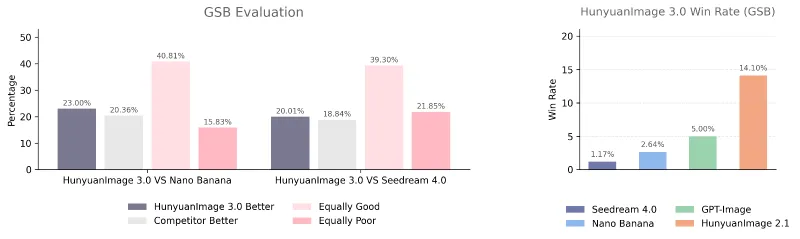
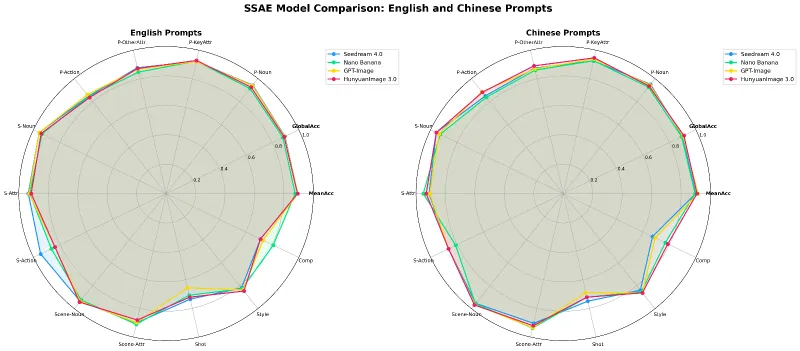
HunyuanImage-3.0的核心目标是解决传统图像生成模型“语义脱节”“细节粗糙”“交互单一”等问题,通过原生多模态融合设计,实现“文本意图精准捕捉+视觉效果高保真呈现”的双重优势,其文生图性能经官方评估,已达到或超越主流闭源模型水平。

二、功能特色
1. 统一多模态架构,打破模态壁垒
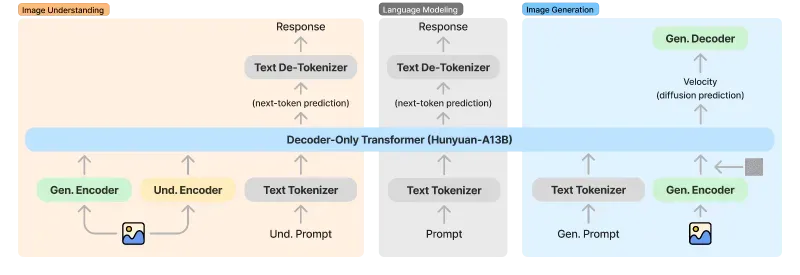
传统图像生成模型多采用“文本编码器+扩散解码器”的分离架构,容易导致文本与图像的语义衔接不自然。HunyuanImage-3.0基于“Decoder-Only Transformer(Hunyuan-A13B)”构建统一自回归框架,将图像理解、语言建模、图像生成三个核心能力整合为一体:
文本输入经Tokenizer处理后,与图像特征在同一编码器中进行跨模态融合;
生成阶段通过“扩散预测+下一个token预测”的双任务协同,确保文本语义与视觉细节高度对齐;
无需额外的模态转换模块,减少信息损耗,生成结果更贴合上下文逻辑。
这种设计让模型不仅能“听懂”文本指令,还能基于文本逻辑主动补充合理细节,例如输入“一只狗在草地上跑”,模型会自动添加“阳光照射下的草地纹理”“狗的毛发动态”等符合场景逻辑的元素。
2. 超大规模MoE架构,性能天花板级
作为开源领域目前最大的图像生成MoE模型,HunyuanImage-3.0的架构设计极具突破性:
包含64个专家节点,总计800亿参数,远超同类开源模型;
采用“激活稀疏”机制,每个token仅激活130亿参数(约16%的专家参与),在保证模型能力的同时控制推理成本;
专家节点分工明确,分别负责语义理解、细节渲染、风格把控等不同任务,协同提升生成质量。
这种大规模MoE设计让模型具备更强的复杂场景处理能力,既能生成“超写实摄影级”图像,也能驾驭“抽象艺术”“动漫风格”等多样化创作需求,同时支持超长文本提示词输入,精准捕捉复杂指令中的每个细节。
3. 优异生成性能,兼顾精准与美感
通过“高质量数据集筛选+强化学习后训练”的双轮优化,HunyuanImage-3.0实现了“语义准确性”与“视觉美感”的最优平衡:
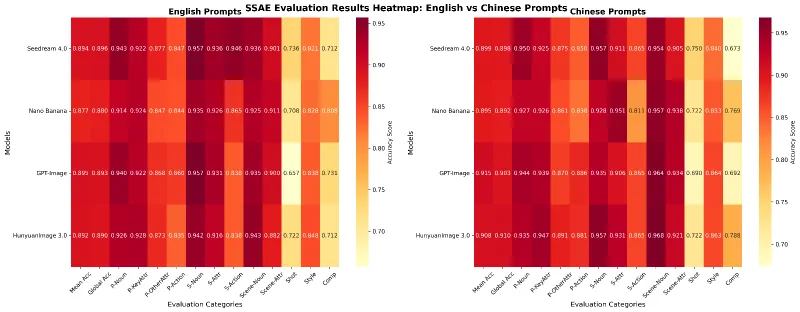
语义精准:官方SSAE评估显示,模型在“核心属性捕捉”“动作匹配”“场景还原”等12个维度的平均准确率达到0.89以上,能精准还原文本中的关键信息(如物体颜色、姿态、场景关系);
视觉优质:生成图像具备“ photorealistic(照片级真实感)”特质,细节表现细腻——无论是布料的纹理、金属的反光,还是光影的渐变,都能呈现出高保真效果;
风格灵活:支持超写实、动漫、油画、素描、平面设计等多种风格,且能通过提示词精准控制风格强度与细节特征。
4. 智能世界知识推理,优化稀疏提示
针对用户常遇到的“提示词过于简单导致生成效果不佳”的问题,HunyuanImage-3.0内置了强大的世界知识推理能力:
对于稀疏提示(如“一个女孩看书”),模型会自动基于常识补充合理细节(如“午后阳光照射的书房”“女孩手中的精装书纹理”“柔软的沙发坐姿”);
Instruct版本支持“提示词自改写+CoT(思维链)思考”,能先分析用户意图,再优化提示词结构,最后生成图像;
支持中文、英文双语言提示词,其中中文提示词经官方优化,语义捕捉准确率更高。
5. 灵活部署与加速,降低使用门槛
为了让不同用户都能便捷使用,HunyuanImage-3.0提供了丰富的部署与加速方案:
支持vLLM加速,推理速度提升3倍以上,适配高并发场景;
提供FlashAttention、FlashInfer两种优化工具,进一步降低显存占用、提升运算效率;
支持本地部署、Web交互演示、Transformers库调用三种使用方式,适配开发者、创作者等不同用户群体。
三、技术细节
1. 核心架构
HunyuanImage-3.0的核心架构为“统一自回归Transformer + MoE专家系统”,具体组成如下:
输入层:支持文本提示词(中文/英文)输入,最长可处理千级字符长度;
编码模块:包含“理解编码器(Und. Encoder)”和“生成编码器(Gen. Encoder)”,分别负责文本语义理解与跨模态特征融合;
核心网络:Decoder-Only Transformer(Hunyuan-A13B)为基础,整合64个MoE专家节点,每个专家专注于特定任务(如语义映射、纹理生成、光影计算);
输出层:通过“扩散预测”生成图像像素,支持多分辨率输出,最大可支持1280x768等高清规格。
2. 关键技术参数
| 类别 | 具体要求/参数 | 备注 |
|---|---|---|
| 模型规格 | 64个专家节点,总计800亿参数,激活130亿参数 | 开源领域最大图像生成MoE模型 |
| 支持功能 | 文生图、提示词改写(Instruct版)、CoT思考 | 图生图、多轮交互暂未开源,后续将支持 |
| 运行环境 | Python 3.12+、PyTorch 2.7.1、CUDA 12.8 | 需严格匹配CUDA版本,否则影响优化工具 |
| 硬件要求 | GPU:≥3×80GB(推荐4×80GB);磁盘:170GB | 用于存储模型权重,多GPU推理更稳定 |
| 推理优化 | vLLM加速、FlashAttention 2.8.3、FlashInfer | 可单独启用,也可组合使用 |
| 输出分辨率 | 支持auto/自定义(如1280x768)/比例(如16:9) | auto模式可根据提示词自动匹配分辨率 |
3. 训练与优化
数据集:采用“高质量公开数据集+私有筛选数据集”混合训练,涵盖12个大类、3500个关键属性,确保模型对不同场景、风格的适配性;
训练方法:基础训练+强化学习后训练(RLHF),其中强化学习阶段重点优化“语义对齐”与“视觉美感”两个指标;
推理优化:通过vLLM的“预编译+批量处理”机制,降低推理延迟;FlashAttention优化注意力计算,减少显存占用;FlashInfer针对MoE架构优化,提升专家节点调度效率。
四、应用场景
1. 创意设计领域
海报/UI设计:支持“UI/海报文本渲染”专用提示词优化,生成符合设计规范的高清素材,如产品宣传海报、APP界面原型图;
材质可视化:可生成不同材质的产品渲染图,如文档中示例的“石膏、玻璃、钛金属、毛绒”四种材质的兔子模型,适配工业设计、电商产品展示需求;
风格化创作:支持古风、现代、科幻、动漫等多种风格,可用于广告设计、品牌视觉素材制作。
2. 内容创作领域
文学配图:为小说、诗歌等文本内容生成场景化插图,支持超长文本提示词,精准还原复杂场景;
影视概念图:生成电影场景、角色设定图,支持“ cinematic(电影级)”风格,可用于影视前期策划;
艺术创作:模拟梵高、毕加索等名家风格,或生成抽象艺术作品,为艺术家提供灵感素材。
3. 教学演示领域
绘画教学:生成步骤化教学图,如文档中示例的“九宫格鹦鹉素描教程”,清晰展示从基础形状到成品的全过程;
知识点可视化:将抽象概念转化为具象图像,如数学公式图解、物理实验场景模拟,提升教学趣味性;
技能培训:生成“堆排序图解”“解方程组步骤”等专业素材,适配编程、数学等学科的教学需求。
4. 个人创作与娱乐
个性化头像/壁纸:根据用户提示生成专属头像(如“古风汉服特写”)、桌面壁纸(如“电影级城市街景”);
创意合成:支持复杂场景组合,如“微缩景观+油画质感”“暗黑风格+古典元素”,满足个性化创作需求;
照片还原:输入文字描述,生成类似真实照片的图像,如“ dimly lit room里的亚洲女性”,可用于纪念场景还原。
五、使用方法
1. 环境准备
(1)系统要求
操作系统:Linux(仅支持Linux环境,Windows/Mac暂不兼容);
硬件:NVIDIA GPU(支持CUDA 12.8),显存≥3×80GB(推荐4×80GB),磁盘空间≥170GB(用于存储模型权重);
软件:Python 3.12+(需提前安装,推荐使用conda创建虚拟环境)。
(2)依赖安装
# 1. 安装PyTorch(CUDA 12.8版本,必须严格匹配) pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128 # 2. 安装腾讯云SDK(用于提示词改写功能) pip install -i https://mirrors.tencent.com/pypi/simple/ --upgrade tencentcloud-sdk-python # 3. 安装基础依赖 pip install -r requirements.txt # 4. 可选:安装性能优化工具(推荐安装,提升3倍推理速度) pip install flash-attn==2.8.3 --no-build-isolation pip install flashinfer-python==0.3.1
2. 模型下载
模型权重需从HuggingFace下载,命令如下:
# 下载基础模型(HunyuanImage-3.0) hf download tencent/HunyuanImage-3.0 --local-dir ./HunyuanImage-3 # 可选:下载Instruct版本(支持提示词改写与CoT思考) hf download tencent/HunyuanImage-3.0-Instruct --local-dir ./HunyuanImage-3-Instruct
⚠️ 注意:下载后的文件夹名称不能包含小数点(如“ HunyuanImage-3.0 ”需改为“ HunyuanImage-3 ”),否则会导致Transformers库加载失败。
3. 三种使用方式
(1)Transformers快速调用(推荐开发者)
from transformers import AutoModelForCausalLM
# 模型路径(本地下载后的文件夹路径)
model_id = "./HunyuanImage-3"
# 配置参数(根据是否安装优化工具调整)
kwargs = dict(
attn_implementation="sdpa", # 安装FlashAttention后可改为"flash_attention_2"
trust_remote_code=True,
torch_dtype="auto",
device_map="auto",
moe_impl="eager" # 安装FlashInfer后可改为"flashinfer"
)
# 加载模型与Tokenizer
model = AutoModelForCausalLM.from_pretrained(model_id,** kwargs)
model.load_tokenizer(model_id)
# 生成图像
prompt = "一只棕白相间的狗在草地上奔跑,阳光明媚,草地纹理清晰"
image = model.generate_image(prompt=prompt, stream=True)
image.save("output.png") # 保存图像(2)本地脚本运行(支持更多参数配置)
# 配置DeepSeek API(用于提示词改写,可选) export DEEPSEEK_KEY_ID="你的DeepSeek密钥ID" export DEEPSEEK_KEY_SECRET="你的DeepSeek密钥Secret" # 运行生成脚本 python3 run_image_gen.py \ --model-id ./HunyuanImage-3 \ --prompt "一只棕白相间的狗在草地上奔跑" \ --attn-impl flash_attention_2 \ --moe-impl flashinfer \ --image-size 1280x768 \ --save dog_run.png \ --verbose 1
本地脚本支持的核心参数如下表所示:
| 参数 | 描述 | 默认值 |
|---|---|---|
| --prompt | 输入文本提示词(必填) | 无 |
| --model-id | 模型本地路径(必填) | 无 |
| --attn-impl | 注意力实现方式:sdpa/flash_attention_2 | sdpa |
| --moe-impl | MoE实现方式:eager/flashinfer | eager |
| --image-size | 输出分辨率:auto/1280x768/16:9等 | auto |
| --diff-infer-steps | 扩散推理步数 | 50 |
| --save | 图像保存路径 | image.png |
| --rewrite | 是否启用提示词改写(1=启用,0=关闭) | 1 |
| --sys-deepseek-prompt | 提示词改写风格:universal/text_rendering | universal |
(3)Gradio交互演示(推荐非开发者)
适合不熟悉代码的用户,通过网页界面操作:
# 1. 安装Gradio pip install gradio>=4.21.0 # 2. 配置环境变量 export MODEL_ID="./HunyuanImage-3" # 模型本地路径 export GPUS="0,1,2,3" # 可用GPU编号,默认使用前4块 export HOST="0.0.0.0" # 访问地址 export PORT="443" # 端口号 # 3. 启动Web界面(启用性能优化) sh run_app.sh --moe-impl flashinfer --attn-impl flash_attention_2 # 4. 访问界面 # 浏览器打开 http://localhost:443,输入提示词即可生成图像
六、常见问题解答
1. 模型加载失败,提示“目录名包含无效字符”怎么办?
答:这是因为模型文件夹名称包含小数点(如“ HunyuanImage-3.0 ”),Transformers库不支持带小数点的目录名。解决方案:将下载后的文件夹重命名为“ HunyuanImage-3 ”(去掉小数点),并确保model_id参数指向重命名后的路径。
2. 第一次推理速度很慢(约10分钟),后续变快是正常的吗?
答:正常。这是因为启用了FlashInfer优化工具,第一次运行时需要编译内核(约10分钟),编译完成后会缓存,后续推理速度会大幅提升(3倍以上)。如果不需要优化,可将moe_impl设为“eager”,避免编译等待。
3. 运行时提示“显存不足”,如何解决?
答:首先检查GPU显存是否满足≥3×80GB的要求,推荐使用4×80GB GPU;其次,可关闭部分优化工具(如FlashInfer),减少显存占用;最后,降低diff-infer-steps(如从50改为30),或选择较小的图像分辨率(如800x600)。
4. 生成的图像与提示词语义不符,怎么办?
答:分两种情况:① 使用基础版模型(HunyuanImage-3.0):该版本不支持自动提示词改写,建议参考官方《提示词手册》,按照“主体+场景+风格+细节”的结构编写详细提示词;② 需自动改写:下载Instruct版本模型,或启用--rewrite 1参数,配合DeepSeek API实现提示词优化。
5. 支持英文提示词吗?生成效果和中文比哪个好?
答:支持英文提示词,但官方优化更偏向中文。如果使用英文提示词,建议:① 将系统提示词(PE文件夹中的文件)翻译为英文;② 提示词尽量详细,避免简洁表达;③ 优先使用Instruct版本,其语义捕捉能力更强,对英文的适配性更好。
6. 为什么安装FlashAttention时提示“编译失败”?
答:大概率是GCC版本过低(需≥9.0)或CUDA版本不匹配(需12.8)。解决方案:① 升级GCC至9.0以上(Ubuntu可通过sudo apt install gcc-9安装);② 确认PyTorch版本为“cu128”(通过torch.version.cuda查看),若不是,重新安装对应版本的PyTorch。
七、相关链接
GitHub仓库:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
模型下载(HuggingFace):https://huggingface.co/tencent/HunyuanImage-3.0
Instruct版本下载:https://huggingface.co/tencent/HunyuanImage-3.0-Instruct
技术报告(arXiv):https://arxiv.org/pdf/2509.23951
八、总结
HunyuanImage-3.0作为腾讯混元团队开源的原生多模态图像生成模型,凭借统一自回归架构、超大规模MoE设计、优异的生成性能和智能推理能力,成为开源图像生成领域的重要突破——它既解决了传统模型“语义与视觉脱节”的核心问题,又通过vLLM、FlashAttention等优化工具降低了部署门槛,同时提供了开发者友好的代码调用、非开发者便捷的Web界面等多种使用方式。其800亿参数的规模的规模与64个专家节点的协同设计,确保了在复杂场景、多样风格下的高保真生成能力,而丰富的应用场景覆盖(创意设计、内容创作、教学演示等),使其既能满足专业开发者的技术落地需求,也能适配普通用户的个性化创作需求。依托完善的官方文档、活跃的社区支持及持续的功能更新,HunyuanImage-3.0为开源多模态生成技术提供了高质量的实践范本,也为各类视觉生成需求提供了强大且灵活的工具支撑。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/hunyuanimage-3-0.html





