Keye-VL:快手推出的高性能开源多模态大语言模型,支持复杂多模态推理与长文本处理
一、Keye-VL是什么
Keye-VL是快手Keys团队面向多模态AI领域开源的高性能多模态大语言模型(VLM),全称为Kwai Keye-VL,是快手先进AI技术生态中的核心开源项目。该项目并非单一模型,而是包含了一系列不同参数规模、不同能力侧重的多模态模型版本,以及配套的工具库、评估套件等完整生态,旨在为开发者提供从模型推理到性能评测的一站式多模态AI解决方案。
从定位来看,Keye-VL区别于传统单一模态的语言模型或视觉模型,它实现了文本、图像、视频等多模态信息的深度融合与统一理解,既具备大语言模型的文本生成、逻辑推理能力,又拥有顶尖的视觉感知与视频内容解析能力,能够处理复杂的跨模态交互任务。项目开源在GitHub平台,基于友好的开源协议向全球开发者开放,支持商用和研究场景的灵活适配。

二、功能特色
Keye-VL凭借其创新的技术架构和针对性的训练策略,形成了多项核心功能特色,覆盖多模态理解、长上下文处理、复杂推理等多个维度,具体如下:
1. 多模态统一理解能力
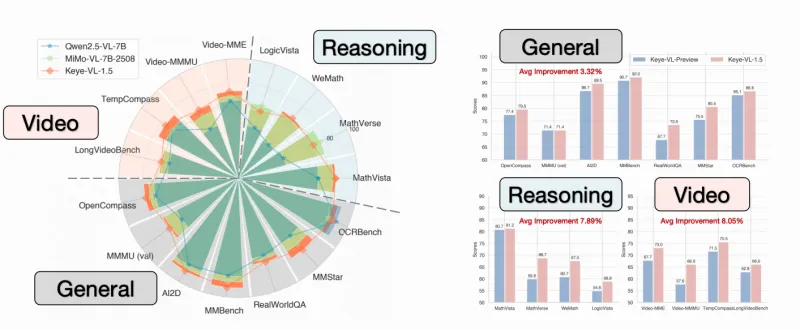
Keye-VL实现了图像、视频、文本的端到端统一建模,无需依赖多个独立模型进行模态转换。对于图像输入,它能精准识别物体、场景、颜色、空间关系,还可解读图表、公式、手写体等特殊视觉内容;对于视频输入,其创新的“慢-快”视频编码策略,既可以捕捉视频的长时序逻辑(如剧情发展、动作流程),又能识别帧级别的细节(如物体细微变化、表情动作),解决了传统视频理解模型“要么丢细节、要么缺逻辑”的痛点。
2. 超长上下文处理能力
Keye-VL 1.5及以上版本支持最长128k tokens的上下文长度,远超常规多模态模型的上下文上限。这一能力使其可以处理超长文本对话(如多轮复杂咨询、长篇文档解读),同时结合视觉信息完成跨模态长任务,例如:基于长达数万字的技术文档和配套的设计图纸,生成完整的项目实施方案;或是解析时长数十分钟的长视频,并结合视频字幕生成详细的内容总结。
3. 顶级复杂推理能力
在推理层面,Keye-VL通过引入LongCoT冷启动数据管道和强化学习训练策略,大幅提升了跨模态推理和逻辑链推理能力。它不仅能完成基础的视觉问答(如“图中有几只动物”),还可处理数学推理(如基于图表数据计算增长率)、逻辑推理(如根据视频剧情推导人物动机)、因果推理(如分析图像中事件的前因后果)等复杂任务,在多个权威评测集上达到行业领先水平。
4. 完善的开源生态配套
Keye-VL并非孤立的模型,而是配备了完整的工具链和评估体系:
配套的
keye-vl-utils工具库,提供了多模态数据预处理、模型推理加速、结果解析等一站式辅助功能;基于VLMEvalKit的评估套件,支持一键完成模型在数十个多模态基准测试集上的性能评测,无需手动准备数据和配置评测流程;
提供了丰富的示例代码和教程,降低了开发者的上手门槛。
5. 多规模模型版本适配
为满足不同场景的资源需求,Keye-VL提供了多个参数规模的版本,具体如下表所示:
| 模型版本 | 核心参数规模 | 核心优势 | 适用场景 |
|---|---|---|---|
| Keye-VL-671B-A37B | 671B | 顶级多模态能力,支持复杂推理和长视频理解 | 企业级复杂任务、科研攻关 |
| Keye-VL-1.5-8B | 8B | 平衡性能与资源,128k长上下文,强化学习优化 | 中小规模应用、边缘端适配 |
| Keye-VL-8B-Preview | 8B | 轻量化预览版,快速体验多模态基础能力 | 个人开发者测试、功能验证 |
三、技术细节
Keye-VL的卓越性能源于其底层创新的技术架构和训练策略,核心技术细节可分为模型架构设计、训练策略优化、多模态编码方案和评估体系构建四个模块:
1. 模型架构设计
Keye-VL采用“视觉编码器+文本大模型+跨模态适配器”的三层架构,实现了多模态信息的高效融合:
视觉编码器:针对图像和视频分别设计了专用编码分支。图像编码基于改进的ViT(视觉Transformer)架构,通过增加注意力头数和特征维度,提升了细粒度视觉信息的提取能力;视频编码则创新性地引入“慢-快”双分支:“慢分支”负责对视频进行低帧率采样,捕捉长时序全局信息,“快分支”负责对关键帧进行高帧率采样,保留细节特征,双分支特征通过交叉注意力机制融合,兼顾了视频的全局逻辑和局部细节。
文本大模型:基于快手自研的大语言模型基座,具备强大的文本理解和生成能力,同时针对多模态任务进行了适配,扩展了模型的token处理能力,支持128k超长上下文。
跨模态适配器:作为连接视觉编码器和文本大模型的桥梁,跨模态适配器采用轻量级的Transformer结构,通过少量参数学习视觉特征与文本token的映射关系,既避免了对大模型基座的大规模修改,又实现了多模态信息的精准对齐。
2. 训练策略优化
Keye-VL的训练过程分为预训练、精调、强化学习三个阶段,每个阶段均采用针对性的优化策略:
预训练阶段:构建了大规模的多模态预训练数据集,包含数亿级的图像-文本对、千万级的视频-文本对,通过对比学习和掩码建模任务,让模型学习到多模态数据的基础关联关系;
精调阶段:引入LongCoT冷启动数据管道,该管道整合了长上下文推理数据、跨模态复杂问答数据,通过指令微调让模型掌握复杂任务的处理逻辑;同时采用“对比精调”策略,对模型输出的答案进行优劣排序,提升回答的准确性和逻辑性;
强化学习阶段:采用RLHF(基于人类反馈的强化学习)和RLO(基于模型反馈的强化学习)结合的方式,先通过人类标注筛选优质回答,再利用大模型对回答进行自动评分,构建奖励模型,最终通过强化学习让模型学会生成符合人类偏好的多模态回答。
3. 多模态编码方案
针对视频和图像的不同特性,Keye-VL设计了差异化的编码方案:
图像编码:采用分块编码+全局注意力机制,将图像划分为固定大小的patch,每个patch生成对应的视觉特征,再通过全局注意力捕捉patch间的空间关系,同时支持对图表、公式等特殊图像的结构化解析,将非文本视觉信息转化为可推理的逻辑特征;
视频编码:除了“慢-快”双分支采样,还引入了时序注意力掩码,让模型能够关注视频中的关键时序节点(如动作发生的时刻、场景切换的瞬间),同时通过帧间特征差分计算,强化对动态变化的感知能力,解决了长视频理解中的时序信息丢失问题。
4. 评估体系构建
为了全面验证模型性能,Keye-VL团队构建了包含通用基准和专属基准的双层评估体系:
通用基准:基于VLMEvalKit工具,对接了MMBench、VQAv2、MSVD等数十个行业通用多模态评测集,覆盖图像问答、视频字幕、视觉推理等基础任务;
专属基准:自研了KC-MMBench评测集,该评测集包含大量贴近实际应用的复杂任务,如长视频剧情推理、跨模态数学计算、多轮多模态对话等,更精准地衡量模型在真实场景中的实用能力。同时,评测体系支持“精确匹配”和“LLM答案提取”两种评分方式,既保证了客观准确性,又兼顾了开放式回答的合理性。
四、应用场景
Keye-VL的多模态能力和灵活的模型版本,使其可适配个人开发、企业服务、科研创新等多个领域的场景,具体典型场景如下:
1. 内容创作辅助
对于自媒体创作者、文案策划人员,Keye-VL可实现“多模态输入-内容输出”的一站式辅助:
输入一段产品演示视频,模型可自动生成产品介绍文案、视频字幕、核心卖点总结,还能根据视频内容生成配套的图文推广素材;
上传设计草图和文字需求,模型可解读草图内容,生成详细的设计方案说明,甚至补充设计中未考虑到的细节;
针对长篇纪录片,模型可基于视频内容和旁白,生成分章节的内容摘要、人物关系图谱和核心观点提炼。
2. 智能客服与咨询
在企业客服场景,Keye-VL可处理跨模态的用户咨询,提升服务效率和准确性:
用户发送产品故障的照片或短视频,模型可自动识别故障现象,结合产品手册文本信息,给出初步的故障排查方案;
针对金融、医疗等专业领域,用户上传报表图片、检查报告图像并附带咨询问题,模型可解析图像中的数据和指标,结合专业知识库给出合规的解答建议(注:医疗场景需结合专业人员审核);
支持多轮跨模态对话,用户可在对话中交替发送文本、图片、视频,模型能保持上下文逻辑一致,持续提供精准服务。
3. 教育与科研辅助
在教育和科研领域,Keye-VL可成为师生和科研人员的得力工具:
学生上传手写的数学题图像,模型可识别题目内容,提供详细的解题步骤和思路,还能结合相关知识点进行拓展讲解;
科研人员上传实验数据图表、论文截图和实验视频,模型可解析数据规律,总结实验现象,甚至辅助生成实验报告的初稿;
针对在线教育平台,模型可实现多模态课件的自动生成,如将文字教案转化为配套的图文讲解、动画脚本,提升课件的趣味性和直观性。
4. 企业级多模态分析
对于需要处理海量多模态数据的企业,Keye-VL可提供高效的数据分析能力:
电商平台可利用模型分析商品评价中的图文/视频反馈,自动提取用户对商品外观、性能、质量的核心诉求,生成用户画像和产品优化建议;
安防领域可通过模型解析监控视频,识别异常行为(如区域入侵、物品遗留),同时结合文本告警规则,生成精准的告警信息和处理预案;
媒体平台可利用模型对平台内的视频、图像内容进行分类标注、违规检测,同时生成内容标签和推荐文案,提升内容分发效率。
5. 轻量化边缘端应用
对于资源受限的边缘端场景(如智能终端、嵌入式设备),Keye-VL-8B系列模型可通过模型量化、裁剪等优化,实现本地化部署:
智能家电可集成模型,识别用户的手势指令、语音指令和设备状态图像,实现多模态智能控制;
移动办公APP可嵌入模型,支持手机端的图片文字提取、手写笔记解析、短视频内容总结,提升办公便捷性;
车载系统可利用模型解析路况图像、行车视频,结合导航文本信息,为驾驶员提供更全面的行车辅助提示。

五、使用方法
Keye-VL提供了清晰的使用流程,涵盖环境准备、工具库安装、模型推理、性能评估四个核心步骤,兼顾了新手入门和进阶开发的需求:
1. 环境准备
首先需要搭建基础的运行环境,推荐配置如下:
操作系统:Linux(Ubuntu 20.04及以上)、Windows 10/11(需开启WSL2)、macOS 12及以上;
Python版本:3.9~3.11(建议使用3.10,兼容性最佳);
硬件要求:若使用8B模型,建议配备至少16GB显存的GPU(如NVIDIA RTX 3090);若使用671B大模型,需依赖多卡集群或云算力平台(如阿里云、腾讯云的GPU服务器);
依赖库:提前安装PyTorch(建议2.0及以上版本)、Transformers、OpenCV、Pillow等基础库,可通过以下命令快速安装基础依赖:
pip install torch==2.0.1 transformers==4.34.0 opencv-python pillow numpy
2. 工具库安装
Keye-VL提供了专用工具库keye-vl-utils,用于简化多模态数据处理和模型调用,安装命令如下:
pip install keye-vl-utils
该工具库包含以下核心功能模块:
数据预处理模块:支持图像的归一化、视频的帧采样、多模态数据的格式转换;
模型推理模块:提供封装好的推理接口,无需手动构建模型输入;
结果解析模块:将模型输出的原始token转化为可读性强的文本、图表等结果。
3. 模型推理
Keye-VL支持Hugging Face Hub调用和本地部署调用两种方式,以下为两种方式的基础示例:
方式1:Hugging Face Hub在线调用(适合快速体验)
首先需要登录Hugging Face账号并获取访问令牌,然后通过以下代码实现多模态推理:
from keye_vl_utils import KeyeVLInference # 初始化推理器 inferencer = KeyeVLInference.from_hf_hub( model_name="Kwai-Keye/Keye-VL-1.5-8B", token="your_hf_token" ) # 输入多模态数据(以图像+文本为例) image_path = "test_image.jpg" question = "请描述这张图片的内容,并分析其中的核心元素" # 执行推理 result = inferencer.infer(image=image_path, text=question) # 输出结果 print(result["response"])
方式2:本地部署调用(适合隐私性要求高的场景)
首先从GitHub或Hugging Face下载模型权重至本地,然后通过以下代码调用:
from keye_vl_utils import KeyeVLInference # 初始化推理器(指定本地模型路径) inferencer = KeyeVLInference.from_local( model_path="./Keye-VL-1.5-8B", device="cuda" # 若无GPU,可指定为"cpu"(推理速度较慢) ) # 输入视频+文本进行推理 video_path = "test_video.mp4" question = "请总结这个视频的核心内容,并列出关键时间节点的事件" # 执行推理 result = inferencer.infer(video=video_path, text=question) # 输出结果 print(result["response"])
4. 性能评估
若需对模型性能进行评测,可使用配套的VLMEvalKit工具,步骤如下:
安装评测工具包:
pip install vlmeval
运行一键评测命令(以MMBench基准为例):
vlmeval --model keye-vl --model-path ./Keye-VL-1.5-8B --dataset mmbench --output ./eval_result
查看评测结果:评测完成后,工具会在
./eval_result目录下生成详细的评测报告,包含模型在各子任务上的准确率、召回率等指标,同时支持可视化对比图表的生成。
六、常见问题解答
1. 问题1:安装keye-vl-utils时提示依赖冲突怎么办?
解答:若出现依赖版本冲突,可通过以下步骤解决:
先卸载冲突的依赖包,例如若提示Transformers版本冲突,可执行
pip uninstall transformers;安装工具库指定的依赖版本,参考
keye-vl-utils官方requirements.txt文件,执行pip install -r requirements.txt;若使用conda环境,建议创建独立的虚拟环境(如
conda create -n keye-vl python=3.10),在新环境中重新安装所有依赖,避免与其他项目的依赖产生冲突。
2. 问题2:调用模型时出现“显存不足”的报错如何处理?
解答:显存不足是大模型推理的常见问题,可根据模型规模和硬件条件采取以下优化方案:
对于8B模型:启用模型量化(如4-bit/8-bit量化),在初始化推理器时添加
load_in_4bit=True参数,可将显存占用降低50%以上,示例代码如下:
inferencer = KeyeVLInference.from_local( model_path="./Keye-VL-1.5-8B", device="cuda", load_in_4bit=True )
对于671B大模型:若单卡显存不足,可启用分布式推理,借助DeepSpeed等框架实现多卡并行;也可使用云服务商提供的大模型推理服务,无需本地部署。
临时优化:关闭其他占用GPU的程序,降低模型的batch_size(推理时每次仅处理1条数据),也可减少上下文长度(如将max_length设置为8192)。
3. 问题3:模型对视频的理解结果不准确,如何提升效果?
解答:若视频理解效果不佳,可从以下维度优化:
数据预处理:对输入视频进行预处理,如裁剪无关片段、提升视频清晰度,使用
keye-vl-utils的视频预处理接口video_preprocess可自动完成降噪、帧筛选;指令优化:优化提问指令,增加任务的明确性,例如将“解读这个视频”改为“请从剧情发展、人物行为、核心观点三个维度解读这个10分钟的科普视频,重点分析第3-5分钟的实验过程”;
模型版本选择:若使用的是Preview版本,可切换至Keye-VL-1.5-8B或更高版本,新版本通过强化学习优化了视频理解能力。
4. 问题4:如何将Keye-VL集成到自己的应用系统中?
解答:Keye-VL支持多种集成方式,可根据应用架构选择:
API集成:通过FastAPI等框架封装模型推理接口,将其部署为微服务,应用系统通过HTTP请求调用接口获取结果;
本地SDK集成:直接在应用代码中引入
keye-vl-utils工具库,调用推理接口实现本地化集成,适合离线应用;云服务集成:使用快手或第三方云平台提供的Keye-VL托管服务,通过平台API实现低代码集成,无需关注模型部署和维护。
5. 问题5:Keye-VL的开源协议是否允许商用?
解答:Keye-VL的开源协议为Apache License 2.0,该协议允许商用,同时允许修改和分发代码,但需要遵守以下条件:
保留原始代码的版权声明和许可证文件;
若修改了模型或工具库代码,需在分发时说明修改内容;
不得使用快手的商标或品牌名称进行虚假宣传。
七、相关链接
为方便开发者获取更多资源和支持,Keye-VL官方提供了以下核心链接:
项目GitHub仓库:https://github.com/Kwai-Keye/Keye
模型Hugging Face Hub地址:
在线演示平台:https://huggingface.co/spaces/Kwai-Keye/Keye-VL-8B-Preview
八、总结
Keye-VL是快手Keys团队开源的一套完整多模态大语言模型生态,涵盖了多参数规模的模型版本、专用工具库和标准化评估套件,其核心优势在于实现了图像、视频、文本的统一多模态理解,支持128k超长上下文处理和复杂逻辑推理,同时提供了轻量化和企业级等不同版本以适配多样场景。从技术层面,它通过“慢-快”视频编码、LongCoT冷启动数据管道、跨模态适配器等创新设计,在多模态融合和推理能力上达到行业领先水平;从使用层面,其封装完善的工具库和清晰的教程大幅降低了开发者的上手门槛,且Apache License 2.0协议支持商用,兼顾了研究和产业需求。无论是个人开发者用于内容创作辅助,还是企业用于多模态数据分析、智能客服搭建,Keye-VL都能提供稳定、高效的技术支撑,是多模态AI领域极具实用价值的开源项目。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/keye-vl.html





