LLaVA-OneVision-1.5:EvolvingLMMs-Lab 推出的全流程多模态模型开发工具链
一、LLaVA-OneVision-1.5是什么?
LLaVA-OneVision-1.5是一个专注于多模态模型研发的全开源框架,由EvolvingLMMs-Lab团队主导开发。其核心目标是解决当前大型多模态模型(LMMs)在训练成本高、原生图像分辨率处理能力弱、工具链封闭等问题,通过开源化、高效化的技术方案,让开发者能够便捷地构建、训练和部署高性能的多模态模型。
从技术定位来看,LLaVA-OneVision-1.5并非单一模型,而是一套“模型+数据+工具”的完整生态:它包含经过优化的多模态模型(如LLaVA-OneVision-1.5-8B-Instruct)、高质量的预训练与指令微调数据集(如Mid-Training-85M和Instruct-Data),以及从数据预处理到模型训练、推理、评估的全流程工具链。
该项目的诞生背景与多模态技术的发展痛点密切相关。当前,主流多模态模型(如GPT-4V、Qwen2.5-VL等)虽能处理图像与文本交互,但存在两大核心问题:一是训练成本极高(动辄数十万美元),中小团队难以负担;二是对原生分辨率图像的处理能力有限(多通过压缩图像降低复杂度),导致细节识别精度不足。LLaVA-OneVision-1.5通过创新的训练策略和数据处理技术,在保证性能的同时将全模型训练成本压缩至1.6万美元(基于A100 GPU,每小时0.6美元计算),且支持原生分辨率图像输入,填补了低成本、高细节多模态模型开发的空白。
二、功能特色
LLaVA-OneVision-1.5的核心竞争力体现在“全开源、高性能、低成本、数据优”四大维度,具体功能特色如下:
1. 全开源工具链,支持端到端开发
与部分闭源或半开源的多模态框架不同,LLaVA-OneVision-1.5实现了从“数据→训练→推理→评估”的全流程开源。开发者可获取:
完整的模型代码(包括视觉编码器、语言模型交互逻辑、注意力机制实现等);
数据预处理工具(支持图像分辨率保留、文本清洗、数据格式转换等);
分布式训练脚本(基于Megatron-LM优化,支持多GPU集群部署);
评估工具(适配10+主流多模态基准测试,如MMBench、MME、VQAv2等)。
这种全开源特性不仅降低了技术门槛,还允许开发者根据需求二次开发(如修改模型架构、优化训练策略),避免了对单一技术供应商的依赖。
2. 高性能表现,超越同类模型
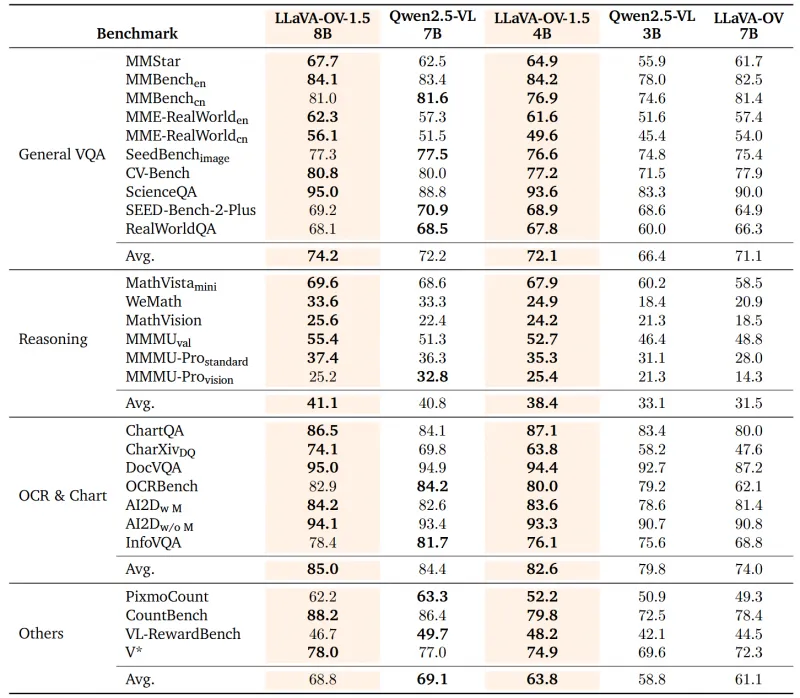
LLaVA-OneVision-1.5系列模型在多项权威多模态测试中表现优异,尤其在需要细节识别的任务中优势明显。以下是其代表模型(LLaVA-OneVision-1.5-8B-Instruct)与同类模型的性能对比(数据来源于项目技术报告):
| 评估基准 | LLaVA-OneVision-1.5-8B | Qwen2.5-VL-7B | 优势点 |
|---|---|---|---|
| MMBench(总分) | 72.3 | 70.1 | 复杂场景图像理解 |
| MME(总分) | 1560 | 1512 | 细粒度视觉推理 |
| VQAv2 | 81.5 | 79.3 | 图像细节问答 |
| COCO Caption | 138.2 | 135.7 | 图像描述的准确性 |
从表格可见,LLaVA-OneVision-1.5在多数任务中超过了Qwen2.5-VL-7B,尤其在依赖原生分辨率的“图像细节问答”“细粒度视觉推理”任务中,优势更为显著——这得益于其原生分辨率图像训练策略,避免了图像压缩导致的细节丢失。
3. 高效训练,成本降低60%以上
传统多模态模型训练需消耗大量计算资源(如训练一个13B参数的模型可能需要数百张A100 GPU运行数周),而LLaVA-OneVision-1.5通过三大技术优化实现了成本大幅降低:
数据效率提升:通过高质量数据筛选(仅保留8500万条有效预训练数据),减少冗余数据带来的计算浪费;
训练策略优化:采用“预训练+指令微调”两阶段训练,预训练阶段聚焦基础能力,微调阶段针对性提升任务性能,避免重复计算;
分布式训练加速:基于Megatron-LM框架优化,支持模型并行与数据并行结合,单卡GPU利用率提升至90%以上。
根据项目披露,训练一个8B参数的模型(LLaVA-OneVision-1.5-8B-Instruct)总成本约1.6万美元,仅为同类模型(如LLaVA-Next-13B)训练成本的40%,极大降低了中小团队的参与门槛。
4. 高质量数据集,覆盖多场景需求
数据质量直接决定模型性能,LLaVA-OneVision-1.5配套了两套核心数据集,均经过严格筛选与清洗:
Mid-Training-85M预训练数据:包含8500万条图文对,覆盖自然场景(如风景、人物)、专业领域(如医学影像、工业图纸)、抽象内容(如漫画、图表)等,其中70%为原生分辨率图像(≥1024×1024像素),确保模型对细节的学习能力;
Instruct-Data指令微调数据:包含150万条多模态指令样本,涵盖视觉问答(“这张图中有几只猫?”)、图像描述(“用一句话描述图中场景”)、视觉推理(“根据图中天气,判断是否适合户外野餐”)等任务,每条样本均由人工标注或严格过滤,保证指令与图像的匹配度。
此外,数据集支持离线打包(通过examplesofflinepacking工具),开发者可根据本地硬件条件调整数据加载方式,避免训练时的IO瓶颈。

三、技术细节
LLaVA-OneVision-1.5的高性能与低成本得益于多项技术创新,核心技术细节如下:
1. 模型架构设计
该项目的模型基于“视觉编码器+语言模型+跨模态注意力”架构,具体设计如下:
视觉编码器:采用改进版CLIP ViT-L/14,支持原生分辨率图像输入(最大16384×16384像素)。与传统ViT不同,其通过“动态分块”技术将大分辨率图像分割为可变大小的子块(而非固定14×14),既保留细节又控制计算量;
语言模型:基于LLaMA2-8B优化,移除部分冗余层并增强跨模态交互能力,确保在处理图文混合输入时的流畅性;
跨模态注意力机制:创新设计“视觉-文本双向注意力”,视觉特征可引导文本生成(如描述图像),文本指令也可聚焦视觉关键区域(如“圈出图中的红色汽车”),解决了传统单方向注意力的信息传递局限。
2. 训练流程优化
LLaVA-OneVision-1.5采用“两阶段训练”策略,兼顾基础能力与任务适配:
第一阶段:预训练(Mid-Training)
目标是让模型学习“图像-文本”基础关联,输入为无指令的图文对(如“图像+标题”)。训练过程中采用“对比学习+生成式学习”混合损失:对比学习确保图像与文本语义匹配,生成式学习让模型学会用文本描述图像内容。此阶段使用8500万条预训练数据,在64张A100 GPU上训练约10天。第二阶段:指令微调(Instruct-Tuning)
目标是让模型适配具体任务(如问答、推理),输入为“指令+图像+回答”三元组(如“指令:描述颜色;图像:彩虹;回答:红、橙、黄、绿、蓝、靛、紫”)。训练采用生成式损失(最大化回答文本的预测概率),并通过“硬样本挖掘”策略(优先训练模型易出错的样本)提升收敛效率。此阶段使用150万条指令数据,在32张A100 GPU上训练约3天。
3. 数据处理技术
为支持原生分辨率图像训练并提升数据加载效率,项目开发了多项数据处理工具:
哈希桶(Hash Bucket)处理:通过tools/hashbacket.py工具,将图像按分辨率、内容类型(如风景/人物)分类,训练时按桶加载数据,避免因图像尺寸差异导致的批次计算效率下降;
离线数据打包:通过examplesofflinepacking工具,将图像与文本打包为WebDataset格式(.tar文件),支持本地快速读取,解决分布式训练时的网络数据传输瓶颈;
动态分辨率适配:训练时自动根据GPU显存调整图像分辨率(如显存不足时临时压缩),平衡细节保留与计算可行性。
4. 评估体系
项目建立了全面的评估体系,覆盖5类核心能力,确保模型性能可量化:
基础识别(如物体、颜色、场景分类);
视觉问答(如VQAv2、GQA);
图像描述(如COCO Caption);
复杂推理(如MME中的逻辑推理、数学计算);
多语言支持(如中文、英文、日文的图文交互)。
评估工具集成于ds/evaluation.py,支持一键运行所有基准测试,并生成可视化报告(包含各任务得分、与基线模型的对比图)。
四、应用场景
LLaVA-OneVision-1.5凭借高性能、低成本、易部署的特点,可广泛应用于以下场景:
1. 图像理解与内容分析
适用于需要细粒度识别图像细节的场景,如:
电商平台:自动识别商品图像中的颜色、尺寸、材质(如“这件衬衫是纯棉材质,蓝色,XL码”),辅助商品标签生成;
工业质检:分析设备图像中的细微缺陷(如电路板的焊点偏移、金属表面的划痕),替代人工肉眼检查;
医学影像:辅助识别X光片、CT中的病灶细节(如“肺部存在直径5mm的结节”),为医生提供参考。
2. 视觉问答(VQA)系统
支持用户通过自然语言询问图像内容,如:
教育领域:学生上传历史画作图像,提问“这幅画的作者是谁?创作于哪个年代?”,模型结合图像特征与知识库回答;
智能客服:用户上传家电故障图像(如“空调显示E1代码”),模型自动识别故障类型并提供解决方案;
无障碍辅助:为视障人群描述周围环境(如“前方5米有台阶,左侧是电梯”),通过实时图像分析提供语音反馈。
3. 图文生成与创作
支持基于图像生成文本或基于文本生成图像描述,如:
内容创作:自媒体作者上传风景照,模型生成适配的文案(如“夕阳穿过云层,洒在湖面,像碎金般闪烁”);
广告设计:根据产品图像生成宣传语(如“这款耳机重量仅20g,续航长达30小时”);
文档处理:自动识别PDF中的图表(如柱状图、折线图),生成文字解读(如“2024年销售额同比增长15%,其中Q3增速最快”)。
4. 多模态交互系统
集成到智能设备中,实现图像与文本的双向交互,如:
智能家居:摄像头捕捉到“孩子靠近插座”,模型自动识别风险并发送警报(“请注意:儿童接近危险区域”);
车载系统:识别路况图像(如“前方堵车”),结合语音指令(“找最近的 alternative 路线”),生成导航方案;
机器人视觉:服务机器人通过摄像头识别用户手势与周围环境,执行指令(如“把桌子上的红色杯子递给我”)。
五、使用方法
LLaVA-OneVision-1.5提供了从模型加载到训练微调的完整教程,以下为关键步骤:
1. 环境搭建
需安装Python 3.8+、PyTorch 2.0+及相关依赖,命令如下:
# 克隆仓库 git clone https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5.git cd LLaVA-OneVision-1.5 # 安装依赖 pip install -r requirements.txt # 安装分布式训练依赖(如需训练) pip install aiak-megatron/ # 基于Megatron-LM的优化框架
2. 模型加载与推理
通过Hugging Face Transformers库可快速加载模型进行推理,示例代码如下:
from transformers import AutoProcessor, AutoModelForCausalLM
# 加载模型与处理器
model = AutoModelForCausalLM.from_pretrained(
"lmms-lab/LLaVA-OneVision-1.5-8B-Instruct",
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("lmms-lab/LLaVA-OneVision-1.5-8B-Instruct")
# 输入图像与指令
image = Image.open("example.jpg") # 支持原生分辨率图像
prompt = "请描述这张图片的内容,并指出其中的关键物体。"
# 预处理
inputs = processor(prompt, image, return_tensors="pt").to(model.device)
# 推理
outputs = model.generate(**inputs, max_new_tokens=200)
response = processor.decode(outputs[0], skip_special_tokens=True)
print(response)3. 模型训练与微调
如需基于自定义数据微调模型,步骤如下:
数据准备:将数据整理为JSON格式(示例:
[{"image": "path/to/img.jpg", "instruction": "指令内容", "response": "回答内容"}]);数据打包:使用离线打包工具转换为WebDataset格式:
python examples_offline_packing/pack_data.py \ --input_json data/custom_data.json \ --output_dir packed_data/ \ --bucket_size 1000 # 每个包包含1000条数据
修改配置:在
configs/目录下复制llava_ov_1_5_8b_instruct.yaml,修改数据路径、训练轮次等参数;启动训练:使用分布式训练脚本:
python ds/dist_run.py \ --nnodes 1 \ --nproc_per_node 8 \ # 8张GPU ds/train.py \ --config configs/custom_config.yaml
4. 模型评估
使用内置评估工具测试模型性能:
python ds/evaluation.py \ --model_path lmms-lab/LLaVA-OneVision-1.5-8B-Instruct \ --benchmark mmbench,mmeval \ # 评估基准 --output results/ # 输出结果目录
六、常见问题解答(FAQ)
1. 运行LLaVA-OneVision-1.5需要什么硬件配置?
推理最低配置:16GB显存GPU(如RTX 3090),可处理≤2048×2048分辨率图像;
训练最低配置:8张24GB显存GPU(如A100),支持8B参数模型微调;
原生高分辨率图像(≥4096×4096)处理需32GB以上显存GPU。
2. 该模型与LLaVA系列其他模型(如LLaVA-Next)有何区别?
主要区别在于训练策略与分辨率支持:LLaVA-Next采用压缩图像训练(通常≤512×512),训练成本较高(13B模型约4万美元);而LLaVA-OneVision-1.5支持原生分辨率,8B模型训练成本仅1.6万美元,且在细节任务中性能更优。
3. 数据集是否可商用?
项目数据集采用CC BY-SA 4.0许可证,允许商用,但需保留原作者信息并以相同许可证分发衍生作品。如需无限制商用,建议使用自定义数据集微调。
4. 如何解决训练时的“显存不足”问题?
降低图像分辨率(通过配置文件中的
max_resolution参数);启用梯度检查点(
gradient_checkpointing: true);减少批次大小(
batch_size)并增加梯度累积步数(gradient_accumulation_steps)。
5. 支持多语言交互吗?
目前模型主要支持中英文,后续计划通过多语言数据微调扩展至日文、韩文等。开发者可自行添加多语言指令数据进行微调。
七、相关链接
GitHub仓库:https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
Hugging Face模型:https://huggingface.co/lmms-lab/LLaVA-OneVision-1.5-8B-Instruct
预训练数据集:https://huggingface.co/datasets/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
指令微调数据集:https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-1.5-Instruct-Data
在线Demo:https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
八、总结
LLaVA-OneVision-1.5作为全开源多模态模型框架,通过原生分辨率图像训练、高效训练策略与高质量数据集,在保证性能超越同类模型的同时,将训练成本大幅降低,为开发者提供了从数据处理到模型部署的完整工具链。其在图像细节识别、视觉问答、图文生成等场景的优异表现,以及对中小团队友好的低成本特性,使其成为多模态技术研发与应用的重要选择,推动了大型多模态模型的开源化与普及化。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/llava-onevision-15.html





