LongCat-Image:美团的开源双语图像生成模型,兼顾中文文本渲染与高效图像编辑
一、LongCat-Image是什么
LongCat-Image是美团LongCat团队开源的一款轻量级双语(中英文)图像生成与编辑基础模型,仅6B参数却具备行业领先的性能表现。该模型不仅能实现高质量文本到图像生成,还支持精准的图像编辑功能,尤其在中文文本渲染的准确性和稳定性上实现突破,同时提供完整的训练工具链和多版本模型支持,有效降低开发者的使用与二次开发门槛,适用于创意设计、内容创作、产品原型设计等多类场景,是兼顾性能、易用性与本土化适配的优秀开源图像生成方案。
LongCat-Image基于先进的扩散模型架构研发,整体参数规模仅为6B,远小于同级别主流开源模型,但在多个权威基准测试中实现了性能反超。该项目以Apache License 2.0协议开源,代码仓库托管于GitHub,同时在Hugging Face提供了预训练模型权重的下载,支持开箱即用的推理和灵活的二次微调,覆盖了从科研探索到商业落地的全链路需求。

二、功能特色
LongCat-Image的核心优势集中在“轻量高性能”“本土化适配”“全链路工具支持”三大维度,具体功能特色可分为以下五大类:
1、轻量参数下的卓越综合性能
不同于行业内部分模型依赖大参数堆砌提升效果的路径,LongCat-Image仅用6B参数就实现了“参数效率”与“生成质量”的平衡。在文本到图像生成的核心基准测试中,该模型在图像真实感、文本指令对齐度、细节丰富度等指标上,均超越了部分10B以上参数的开源模型,大幅降低了模型部署的硬件门槛,普通的消费级GPU即可满足基础推理需求。
2、行业领先的中文文本渲染能力
这是LongCat-Image最突出的本土化特色。当前多数开源图像生成模型由海外团队研发,在中文文本渲染场景下存在“字符错位、笔画缺失、生僻字无法识别”等问题,而LongCat-Image通过构建专属的中文文本图像数据集和优化训练策略,实现了三大突破:一是常见中文字符渲染准确率超95%,远高于同级别开源模型的70%左右;二是中文字典覆盖率达到行业领先水平,可精准渲染生僻字和复杂词组;三是支持多字体、多排版的中文文本生成,能满足海报、文案等场景的定制化需求。
3、高精度图像编辑能力
其衍生模型LongCat-Image-Edit在开源图像编辑模型中处于领先梯队,具备“指令精准遵循”和“视觉一致性保持”两大核心能力。在局部编辑场景中(如替换图片中的某个物体、修改文字内容、调整场景色调),模型可精准识别编辑指令的范围和要求,同时保证未编辑区域的像素、光影、风格与原图完全一致,避免出现“编辑痕迹明显”“整体风格割裂”等常见问题。
4、出色的照片级真实感生成效果
通过创新的多源数据融合策略和训练框架优化,LongCat-Image生成的图像具备极强的照片真实感。无论是人像、风景、静物还是商业产品,模型都能精准还原真实世界的光影层次、材质质感和空间透视,生成的图像可直接用于广告素材、内容创作等商业化场景,无需额外的后期修图。
5、完整的开源生态工具链
项目不仅提供了预训练模型,还配套了全链路的工具支持:从训练中期的检查点,到SFT(监督微调)、LoRA(低秩适应微调)、DPO(直接偏好优化)等多种训练脚本,再到开箱即用的推理代码,覆盖了“模型下载-推理验证-二次训练-应用部署”的全流程,显著降低了开发者的使用和二次开发门槛。
为更直观展示LongCat-Image与同级别开源模型的核心差异,以下是其与某主流10B参数开源图像模型的性能对比:
| 对比维度 | LongCat-Image(6B) | 某主流10B开源模型 |
|---|---|---|
| 中文文本渲染准确率 | >95% | 约70% |
| 基础硬件部署门槛 | 消费级GPU(16G显存) | 专业级GPU(24G显存) |
| 图像编辑视觉一致性 | 92%(权威测评) | 75%(权威测评) |
| 支持的二次训练方式 | SFT/LoRA/DPO/编辑任务 | 仅支持基础SFT微调 |
| 开源协议 | Apache License 2.0 | 非商业用途协议 |
三、技术细节
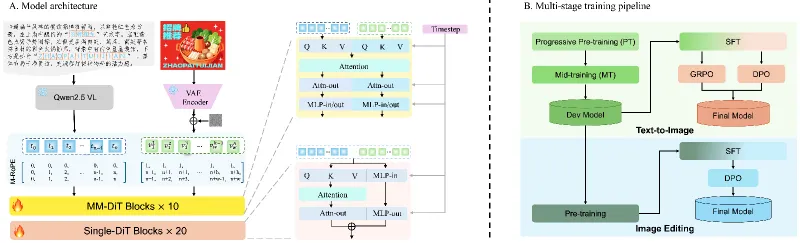
LongCat-Image的技术架构基于经典的扩散模型(Diffusion Model),但在模型结构、训练策略、数据处理三大核心环节进行了针对性创新,以下是具体技术细节:
模型基础架构 模型整体采用“文本编码器+图像扩散解码器”的双编码器架构:
文本编码器:采用多语言预训练的Transformer架构,同时优化了中文文本的tokenizer(分词器),增强了对中文语义和字符结构的理解,可精准解析包含复杂中文文本的生成指令;
图像扩散解码器:采用6B参数的U-Net结构,通过轻量化的注意力机制和残差模块设计,在降低参数规模的同时,保留了对图像细节的建模能力,实现了“轻量”与“高性能”的统一。
核心训练策略 为提升模型的综合性能和中文适配能力,团队采用了分阶段的训练流程:
预训练阶段:基于多源异构数据集训练,包括中英文文本-图像对、中文文本专属数据集、真实照片数据集等,让模型掌握基础的图像生成能力和中文文本的视觉特征;
精调阶段:通过SFT(监督微调)对模型进行指令对齐训练,提升模型对复杂生成指令的理解能力;同时引入DPO(直接偏好优化),基于人工标注的偏好数据优化图像生成质量,让结果更符合人类审美;
编辑任务专项训练:针对LongCat-Image-Edit模型,专门构建了“原图-编辑指令-编辑后图像”的三元数据集,训练模型的局部编辑能力和视觉一致性保持能力。
中文文本渲染优化 针对中文文本渲染的行业痛点,团队采取了两大技术方案:
构建专属中文文本图像数据集:收集了覆盖不同字体、字号、排版的中文文本图像数据,包含常见字、生僻字、复杂词组等,总数超千万级,让模型充分学习中文文本的视觉特征;
优化文本特征编码:在文本编码器中增加“字符结构感知模块”,可识别中文的笔画、偏旁等底层结构,避免出现“笔画缺失”“字形错误”等问题,同时提升多字体文本的生成能力。
四、应用场景
LongCat-Image凭借其“轻量高性能”“中文适配强”“支持编辑”的核心优势,可覆盖多个领域的应用需求,具体场景如下:
创意内容创作领域 对于自媒体创作者、设计师、文案策划等人群,LongCat-Image可快速将文字创意转化为可视化图像。例如,自媒体作者可输入“一张带有‘秋日露营’毛笔字体的森林露营海报,风格为日系清新”,模型能精准生成包含指定中文文本的海报初稿;设计师可通过模型快速生成多个创意方案,再基于方案进行精细化修改,大幅提升创作效率。
电商与商业营销领域 电商商家和营销人员可利用模型生成商品宣传素材,如输入“一款白色陶瓷马克杯,杯身印有‘新年限定’宋体字样,背景为红色喜庆场景,照片级真实感”,模型能生成符合要求的商品图,无需专业摄影和修图;同时可通过LongCat-Image-Edit模型对现有素材进行局部修改,如替换商品上的文字、调整背景色调,快速适配不同营销节点的需求。
科研与教育领域 高校和科研机构的研究人员可基于LongCat-Image的开源代码和训练工具链,开展图像生成模型的相关研究,如探索低参数模型的性能优化方法、研究中文文本与图像的对齐机制等;在教育场景中,教师可利用模型生成包含中文知识点的可视化教具,如历史事件场景图、科学原理示意图等,辅助课堂教学。
产品原型与UI设计领域 产品经理和UI设计师可通过模型快速生成产品原型的可视化效果图,如输入“一款移动端阅读APP的启动页,页面中央显示‘书香阅读’艺术字体,背景为淡蓝色渐变,风格简约清新”,模型能生成符合需求的界面初稿,帮助团队快速确认设计方向;同时可通过编辑模型调整界面元素的位置和样式,提升原型迭代效率。
个性化定制场景 面向普通用户的个性化需求,如定制专属头像、节日贺卡、朋友圈配图等,LongCat-Image可根据用户的自然语言指令生成内容,且能精准融入用户指定的中文文字,如“生成一张生日贺卡,贺卡中央写‘祝XX生日快乐’,周围装饰粉色气球和蛋糕,卡通风格”,满足用户的个性化表达需求。
五、使用方法
LongCat-Image的使用分为“模型下载”“基础推理”“二次训练”三个核心环节,以下是具体操作步骤(以Python环境为例):
(一)环境准备
首先需配置基础运行环境,安装必要的依赖库:
# 安装基础依赖 pip install torch torchvision transformers diffusers accelerate huggingface_hub # 安装额外工具库(如需训练则需安装) pip install peft trl datasets
(二)模型下载
项目在Hugging Face提供了三个核心模型的权重下载,可通过Hugging Face CLI工具或Python代码下载:
通过CLI工具下载
# 安装huggingface_hub CLI pip install "huggingface_hub[cli]" # 下载LongCat-Image(基础生成模型) huggingface-cli download meituan-longcat/LongCat-Image --local-dir ./weights/LongCat-Image # 下载LongCat-Image-Edit(图像编辑模型) huggingface-cli download meituan-longcat/LongCat-Image-Edit --local-dir ./weights/LongCat-Image-Edit
通过Python代码下载
from huggingface_hub import snapshot_download # 下载基础生成模型 snapshot_download( repo_id="meituan-longcat/LongCat-Image", local_dir="./weights/LongCat-Image" )
(三)基础推理
文本到图像生成 基于Diffusers库可快速实现文本到图像的生成,示例代码如下:
import torch
from diffusers import DiffusionPipeline
# 加载模型
pipe = DiffusionPipeline.from_pretrained(
"./weights/LongCat-Image",
torch_dtype=torch.float16 # 启用半精度推理,降低显存占用
).to("cuda") # 若无GPU可改为"cpu"
# 定义生成指令(包含中文文本)
prompt = "一张户外咖啡海报,海报上方有‘秋日限定咖啡’黑体字样,背景为落叶街道,照片级真实感"
# 执行生成
image = pipe(prompt, num_inference_steps=30).images[0]
# 保存生成的图像
image.save("autumn_coffee_poster.png")图像编辑 使用LongCat-Image-Edit模型可实现图像局部编辑,示例代码如下:
import torch
from diffusers import StableDiffusionInpaintPipeline
from PIL import Image
# 加载编辑模型
edit_pipe = StableDiffusionInpaintPipeline.from_pretrained(
"./weights/LongCat-Image-Edit",
torch_dtype=torch.float16
).to("cuda")
# 加载原图和蒙版(蒙版需标记要编辑的区域)
original_image = Image.open("autumn_coffee_poster.png").convert("RGB")
mask_image = Image.open("mask.png").convert("RGB") # 蒙版中白色区域为待编辑区域
# 定义编辑指令
edit_prompt = "将海报上的‘秋日限定咖啡’改为‘冬季热饮特惠’宋体字样"
# 执行编辑
edited_image = edit_pipe(
prompt=edit_prompt,
image=original_image,
mask_image=mask_image,
num_inference_steps=30
).images[0]
# 保存编辑后的图像
edited_image.save("winter_drink_poster.png")(四)二次训练
若需对模型进行二次微调(如LoRA微调),可使用仓库中train_examples目录下的脚本,以LoRA微调为例,核心步骤如下:
准备自定义的文本-图像数据集,格式需符合项目要求(可参考仓库的数据集示例);
修改
train_examples/lora_train.py中的配置参数,包括数据集路径、模型权重路径、训练轮次、学习率等;执行训练脚本:
python train_examples/lora_train.py
训练完成后,可将LoRA权重与基础模型合并,实现定制化的生成效果。

六、常见问题解答
Q:LongCat-Image的部署需要什么硬件配置?
A:基础推理场景下,6B参数的模型在开启半精度推理时,仅需16G显存的消费级GPU(如RTX 3060/3070)即可运行;若需进行二次训练,建议使用24G以上显存的专业GPU(如RTX 3090/A100),同时可通过分布式训练进一步降低单卡显存压力。
Q:模型生成的中文文本出现笔画错误怎么办?
A:可尝试三种解决方案:一是优化生成指令,明确指定字体和字号(如“黑体、12号字”);二是使用LongCat-Image-Edit模型对错误区域进行局部编辑;三是基于自定义的中文文本数据集进行LoRA微调,提升特定场景下的文本渲染准确率。
Q:是否支持非中文的多语言文本生成?
A:LongCat-Image支持基础的英文文本生成,其文本编码器具备双语处理能力,但模型的核心优化方向为中文,若需高质量的小语种文本生成,建议结合对应语种的数据集进行二次微调。
Q:训练过程中出现显存不足的问题如何解决?
A:可通过以下方式优化:一是启用梯度累积(gradient accumulation),减少单次迭代的显存占用;二是使用LoRA而非全量微调,仅训练低秩适配器权重;三是开启混合精度训练(mixed precision),降低张量存储的显存开销;四是采用分布式训练,将计算任务拆分到多张GPU上。
Q:模型生成的图像存在版权问题吗?
A:LongCat-Image以Apache License 2.0协议开源,用户可基于协议进行商用和二次开发,但需注意:生成图像的版权归属需结合具体使用场景判断,若生成内容包含他人知识产权(如品牌标识、肖像),需获得对应授权。
七、相关链接
Hugging Face模型仓库:
八、总结
LongCat-Image是美团LongCat团队面向图像生成领域推出的一款兼具“轻量性”“高性能”“本土化”的开源模型,6B的参数规模大幅降低了部署门槛,同时在中文文本渲染、图像真实感、精准编辑等核心能力上实现了行业领先,配套的全链路工具链又为二次开发和科研探索提供了便利。该项目不仅解决了主流开源模型在中文场景的适配痛点,还通过创新的训练策略实现了参数效率与生成质量的平衡,无论是创意内容创作、电商营销素材生成,还是科研探索、产品原型设计,LongCat-Image都能提供高效、稳定的解决方案,是开源图像生成领域中极具实用价值和本土化特色的优秀项目。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/longcat-image.html