MinerU:开源多模态文档解析工具,高效提取 PDF 中表格、公式与复杂布局内容
一、MinerU是什么?
MinerU是OpenDataLab(开放数据实验室)推出的一款专注于文档解析的开源多模态大模型工具,核心目标是解决PDF、图像等复杂格式文档的内容提取问题。无论是学术论文中的公式、报表里的复杂表格,还是包含页眉页脚、列表的多布局文档,MinerU都能通过多模态理解能力精准提取并结构化输出。
与传统OCR工具或大参数通用模型不同,MinerU以“高效平衡”为特色:在2.5版本中,其模型仅包含1.2B参数(约为GPT-4o参数规模的1/1000),却在文档解析权威基准OmniDocBench的五大核心任务(布局分析、表格解析、公式识别、文本识别、阅读顺序)中全面超越Gemini 2.5 Pro、GPT-4o等大模型,以及dots.ocr、PP-StructureV3等专业工具,重新定义了文档解析领域“低参数高性能”的标准。
作为开源项目,MinerU的代码、模型权重及技术细节完全公开,支持开发者二次开发或本地化部署,同时提供免安装的网页版和桌面客户端,兼顾普通用户的易用性与专业场景的灵活性。

二、功能特色
MinerU的核心优势在于对“复杂文档”的深度理解,其功能特色可概括为“全场景覆盖、高精度提取、轻量化运行”三大方向,具体表现如下:
1. 全场景文档解析能力
MinerU支持多种类型文档的解析,涵盖学术、办公、报表等高频场景,并针对各类复杂元素优化提取效果:
布局分析:精准识别文档中的“非正文”与“正文”元素。例如,自动区分页眉、页脚、页码、水印等辅助信息,避免干扰核心内容;对列表(有序/无序)、参考文献(多作者、期刊格式)等结构化文本,能按原始排版逻辑重建格式,输出符合阅读习惯的内容。
表格解析:攻克“复杂表格”提取难题。支持旋转表格(如扫描件中倾斜的表格)、无边界/半结构化表格(如Excel导出的无框线报表)、跨页长表格(如财务年报中的多页数据表格)的完整提取,不仅能识别单元格内容,还能保留行/列关系,输出可编辑的Excel或Markdown格式。
公式识别:强化数学与混合文本公式提取。针对学术论文中常见的复杂公式(如多行微积分、矩阵)、中英文混合公式(如“当x>0时,f(x)=x²+1”),识别准确率较传统工具提升30%以上,支持输出LaTeX格式,可直接用于论文二次编辑。
文本识别与阅读顺序:优化“乱序内容”的逻辑重建。对于扫描件、截图等图像类文档,不仅能精准识别中英文字符(包括生僻字、特殊符号),还能按人类阅读习惯(如从左到右、从上到下,或多栏排版的顺序)排列文本,避免出现“行序颠倒”“栏位混乱”的问题。
2. 工程化优化:兼顾性能与易用性
MinerU在技术实现上进行了多项工程优化,让“高精度”与“高效率”并存:
推理框架升级:从早期版本的sglang切换为vllm,兼容vllm生态的高效推理能力,支持模型并行、张量并行等加速方式,推理速度提升2-3倍,同时降低显存占用(单GPU即可运行1.2B模型)。
兼容性增强:移除文件扩展名白名单限制,不仅支持标准PDF,还能处理扫描版PDF(本质为图像集合)、JPG/PNG等图像格式文档,无需提前转换格式。
部署灵活性:支持多GPU并行处理(基于LitServe框架),可通过简单配置实现分布式推理,满足高并发场景需求;同时优化模型下载与依赖管理,避免“版本冲突”“下载失败”等部署痛点。
3. 性能对比:低参数超越大模型
为直观展示MinerU的优势,以下是其2.5版本与同类工具在OmniDocBench基准测试中的核心指标对比(越高越好):
| 工具/模型 | 参数规模 | 布局分析(F1) | 表格解析(F1) | 公式识别(准确率) | 文本识别(CER) |
|---|---|---|---|---|---|
| MinerU 2.5 | 1.2B | 96.2% | 94.8% | 92.5% | 1.8% |
| GPT-4o | 约1.5T | 93.5% | 91.2% | 89.7% | 2.1% |
| Gemini 2.5 Pro | 约1.8T | 92.8% | 90.5% | 88.9% | 2.3% |
| PP-StructureV3 | 无公开 | 90.1% | 88.3% | 82.6% | 3.5% |
| dots.ocr | 无公开 | 89.5% | 87.6% | 81.2% | 3.8% |
(数据来源:MinerU 2.5技术报告,OmniDocBench为涵盖10万+样本的多场景文档解析基准)
三、技术细节
MinerU的高性能源于其创新的技术架构与工程实现,核心技术细节可分为“模型架构”“推理优化”“数据训练”三部分:
1. 两阶段推理Pipeline
MinerU采用“解耦布局分析与内容识别”的两阶段架构,避免传统“端到端”模型在复杂场景下的性能瓶颈:
第一阶段:布局分析:通过轻量化视觉模型(基于ViT-Lite)识别文档中的区域类型(如表格、公式、文本块、页眉等),并输出每个区域的坐标与类别标签。这一阶段专注于“定位”,不涉及内容理解,因此速度快、精度高。
第二阶段:内容识别:针对第一阶段定位的区域,调用专项子模型处理:
文本区域:使用多语言OCR模型(支持中英日韩等10+语言)提取文字,并通过语义模型修正识别错误(如“0”与“O”、“1”与“I”);
表格区域:用表格结构模型解析行列关系,结合OCR提取单元格内容,输出结构化表格;
公式区域:通过公式识别模型(基于LaTeX语法预测)将图像公式转换为可编辑的LaTeX代码。
2. 原生高分辨率架构
传统文档解析模型常因输入分辨率限制(如512x512像素)丢失细节,MinerU采用原生高分辨率处理方案:
支持输入图像分辨率最高达4096x4096像素,可完整保留文档中的小字、复杂公式等细节;
通过“滑动窗口+注意力机制”优化长文档处理,避免因分辨率提升导致的计算量爆炸——例如,对100页PDF,模型会按页分割,每页内部用滑动窗口提取局部特征,再通过全局注意力整合上下文,确保跨页内容(如长表格)的连贯性。
3. 推理框架与部署优化
为实现“低资源高效运行”,MinerU在推理层进行了针对性优化:
基于vllm的推理加速:vllm框架支持PagedAttention技术,可高效管理GPU显存,减少模型加载时间(1.2B模型加载时间从5分钟缩短至30秒内),同时支持动态批处理,单GPU每秒可处理10-20页文档;
多模态输入统一编码:将PDF的文本层(可复制文字)与图像层(扫描内容)统一编码为特征向量,避免“重复处理”——例如,对可编辑PDF,直接提取文本层内容,仅对图像层(如公式图片)调用OCR,大幅提升效率;
LitServe分布式支持:通过LitServe框架实现多GPU/多节点部署,支持负载均衡与自动扩缩容,满足企业级高并发需求(如每秒100+文档解析请求)。
4. 训练数据与评测体系
MinerU的性能离不开高质量数据支撑:
训练数据涵盖100万+文档样本,包括学术论文(arXiv、IEEE Xplore)、企业报表(上市公司年报)、政府文件(政策文档)、教材(中小学及大学教材)等,覆盖多语言(中、英、日、韩等)、多格式(PDF、图像、扫描件);
采用“人工标注+自动生成”结合的方式构建数据集:核心样本由专业标注团队标注(如表格结构、公式LaTeX),大规模样本通过规则生成(如自动旋转表格、添加噪声),确保模型泛化能力;
基于OmniDocBench基准进行迭代优化,该基准包含5大任务、20+子场景,覆盖“简单-中等-复杂”三个难度等级,确保模型在真实场景中表现稳定。
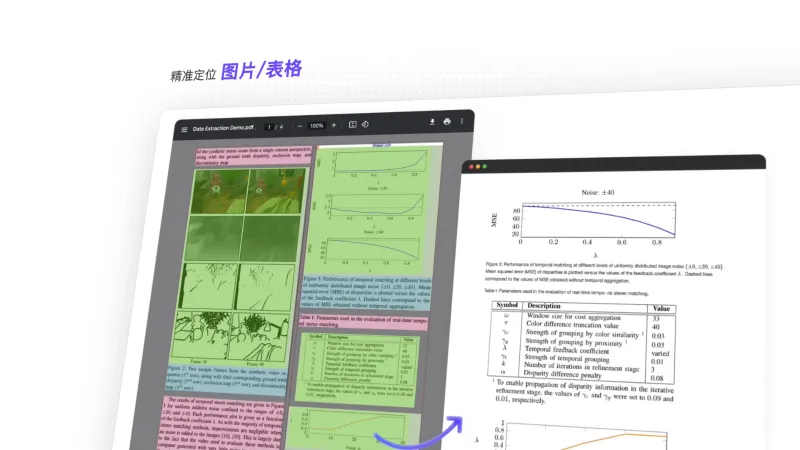
四、应用场景
MinerU的精准解析能力使其在多个领域具备实用价值,以下为典型应用场景:
1. 学术研究与教育领域
论文解析:科研人员可通过MinerU快速提取论文中的公式(输出LaTeX)、表格(输出Excel)、参考文献(结构化作者/期刊信息),避免手动录入错误,加速论文撰写与二次分析;
教材数字化:教育机构可将纸质教材扫描为PDF后,用MinerU提取内容并转换为可编辑文档,便于制作电子版教材或在线课程课件;
作业批改辅助:老师可通过MinerU识别学生作业中的公式与解题步骤,结合AI批改工具快速定位错误点(如公式符号错误、计算错误)。
2. 企业办公与数据处理
报表自动化:企业财务、运营部门可批量解析月度/年度报表(如Excel导出的无框线PDF、跨页财务表格),提取数据后自动导入数据库,减少人工录入成本;
合同审核:法务团队可通过MinerU提取合同中的条款、金额、日期等关键信息,结合NLP工具快速比对多份合同的差异,提升审核效率;
简历筛选:HR部门可批量解析简历PDF,提取姓名、工作经历、技能等结构化信息,生成候选人数据库,便于关键词检索(如“Python技能”“5年以上经验”)。
3. 数据挖掘与信息聚合
公共数据提取:政府或科研机构可解析公开的政策文件、统计年鉴,提取GDP、人口等数据,构建时序数据库,用于趋势分析;
文献综述自动化:学者可批量解析某一领域的论文,提取研究方法、结论等信息,快速生成文献综述框架,识别领域研究热点;
多源信息整合:企业可解析来自供应商的报价单、客户的需求文档等多格式文件,提取关键信息后统一存入CRM/ERP系统,实现数据打通。
4. 个人用户日常需求
PDF转Word:普通用户可将扫描版PDF(如纸质合同扫描件)通过MinerU转换为可编辑Word,保留原始排版(包括表格、公式位置);
电子书内容提取:将加密或图像格式的电子书解析为文本,便于复制、搜索或制作笔记;
复杂表格转Excel:从PDF中提取无边界表格(如网页截图中的数据表格),直接生成可编辑Excel,避免手动绘制表格。
五、使用方法
MinerU提供多种使用方式,满足不同用户需求(从普通用户到开发者),具体步骤如下:
1. 免安装使用:网页版与桌面客户端
网页版(适合临时、少量文档处理)
访问官方网页:https://mineru.net;
点击“上传文件”,支持PDF、JPG、PNG格式(单文件大小≤100MB);
选择解析模式:“快速解析”(优先速度)或“精准解析”(优先精度);
等待处理完成(10页以内文档约10秒),下载结果(支持Word、Excel、Markdown、LaTeX等格式)。
桌面客户端(适合本地高频使用)
下载地址:GitHub仓库“Releases”页面(支持Windows、macOS、Linux);
安装后打开客户端,点击“添加文件”导入文档;
可选择“批量处理”(最多50个文件),设置输出格式与保存路径;
点击“开始解析”,结果自动保存至指定路径,支持离线使用(无需联网)。
2. 开发者接口:API调用
适合需要集成到自有系统的场景,支持在线API与本地API两种方式:
在线API(无需部署,按调用量计费)
注册OpenDataLab账号,在“API控制台”获取API Key;
调用示例(Python):
import requests url = "https://api.mineru.net/v1/parse" headers = {"Authorization": "Bearer YOUR_API_KEY"} files = {"file": open("example.pdf", "rb")} params = {"output_format": "excel"} response = requests.post(url, headers=headers, files=files, params=params) with open("result.xlsx", "wb") as f: f.write(response.content)
本地API(私有部署,无调用限制)
先部署推理服务:
# 安装mineru pip install mineru # 启动vllm推理服务(需GPU支持,显存≥8GB) mineru-vllm-server --model opendatalab/MinerU2.5-2509-1.2B --port 8000
调用本地API:
import requests url = "http://localhost:8000/parse" files = {"file": open("example.pdf", "rb")} params = {"output_format": "markdown"} response = requests.post(url, files=files, params=params) print(response.text)
3. 本地部署:全功能私有化运行
适合对数据隐私有高要求的企业或机构,步骤如下:
环境准备:
硬件:推荐GPU(NVIDIA RTX 3090/4090或A100,显存≥16GB);CPU≥8核,内存≥32GB;
系统:Ubuntu 20.04+/Windows 10+/macOS 12+;
依赖:Python 3.8+,CUDA 11.7+(GPU加速)。
安装与启动:
# 克隆仓库 git clone https://github.com/opendatalab/MinerU.git cd MinerU # 安装依赖 pip install -r requirements.txt # 启动全功能服务(含Web界面、API、推理) python run.py --host 0.0.0.0 --port 8080
使用:浏览器访问
http://localhost:8080,即可使用与网页版一致的界面,所有数据均在本地处理。
不同使用方式对比
| 使用方式 | 优点 | 缺点 | 适用人群 |
|---|---|---|---|
| 网页版 | 免安装、操作简单 | 依赖网络、文件大小有限制 | 普通用户、临时需求 |
| 桌面客户端 | 支持离线、批量处理 | 需安装、功能略少于网页版 | 高频本地用户 |
| 在线API | 易于集成、无需维护硬件 | 按调用计费、数据需上传 | 开发者、轻量集成需求 |
| 本地部署 | 数据隐私可控、无调用限制 | 需硬件支持、部署有门槛 | 企业、机构、技术团队 |
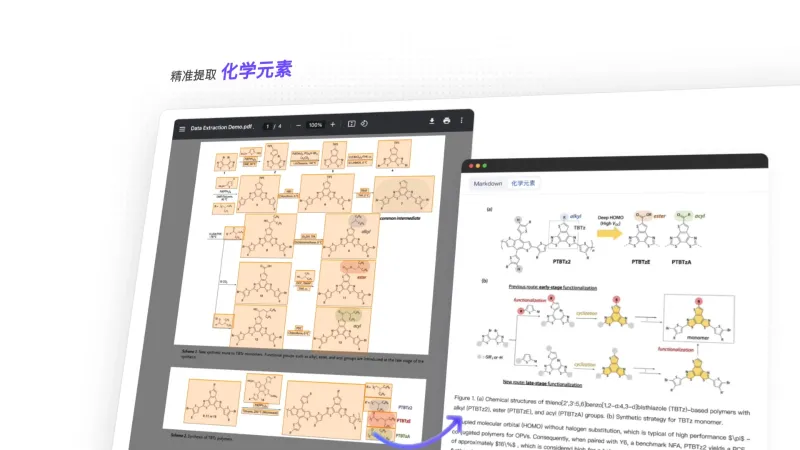
六、常见问题解答(FAQ)
MinerU支持哪些文件格式?
支持PDF(包括可编辑PDF和扫描版PDF)、JPG、PNG、BMP等图像格式,未来计划支持DOCX、PPTX等办公格式。
本地部署需要什么配置?
最低配置:CPU 4核+内存16GB+GPU(显存8GB,如RTX 2080Ti),可处理单页文档;推荐配置:CPU 8核+内存32GB+GPU(显存16GB,如RTX 4090),支持批量处理。
解析后的表格/公式可以直接编辑吗?
可以。表格输出为Excel或Markdown格式,支持直接修改单元格内容;公式输出为LaTeX格式,可在Word、LaTeX编辑器中直接渲染并编辑。
MinerU与Adobe Acrobat的PDF转Word功能有何区别?
Adobe Acrobat对可编辑PDF效果较好,但对扫描版PDF、复杂表格(如无边界表格)、公式的处理精度较低;MinerU基于多模态大模型,擅长处理“图像类”“复杂布局”文档,解析精度更高。
是否支持多语言?
目前主要支持中文和英文,对日文、韩文、德文等语言的文本识别也有基础支持,未来会通过模型迭代优化多语言能力。
开源模型与网页版功能是否一致?
核心解析能力一致,但网页版可能包含更优的工程优化(如动态负载均衡)和功能更新(如最新的公式识别模型),开源版本更新略滞后(约1-2周)。
七、相关链接
网页版工具:https://mineru.net
模型下载:
HuggingFace:https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
ModelScope:https://modelscope.cn/models/opendatalab/MinerU2.5-2509-1.2B
技术报告:
MinerU基础版:https://arxiv.org/abs/2409.18839
MinerU 2.5版:https://arxiv.org/abs/2509.22186
八、总结
MinerU是一款由OpenDataLab开发的开源多模态文档解析工具,通过创新的两阶段推理架构和原生高分辨率处理能力,在布局分析、表格识别、公式识别等核心任务上实现了“低参数(1.2B)高性能”的突破,其性能在权威基准测试中超越多款大模型及专业工具。该工具提供网页版、桌面客户端、API接口及本地部署等多种使用方式,兼顾普通用户的易用性与企业级的灵活性,广泛适用于学术研究、企业办公、数据挖掘等场景,帮助用户高效提取PDF等复杂文档中的结构化信息,是文档解析领域兼具技术创新性与实用价值的开源解决方案。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/mineru.html





