Mistral 3:Mistral AI 开源的多模态模型家族,支持从 3B 到 675B 参数全场景部署
一、Mistral 3是什么
Mistral 3是欧洲AI企业Mistral AI推出的全规模开源多模态AI模型家族,于2025年12月2日正式发布,旨在打破“闭源模型性能垄断”与“开源模型场景局限”,为开发者与企业提供从“边缘设备到云端集群”的一站式智能解决方案。该家族以“开放、高效、多能”为核心定位,全线采用Apache 2.0开源协议——开发者可免费使用、修改模型代码,甚至将基于其开发的商业产品直接推向市场,无需支付授权费用,彻底消除商用门槛。
从参数规模看,Mistral 3形成清晰的“梯队布局”:
轻量边缘层:Ministral 3系列(3B/8B/14B参数),主打低资源消耗,适配PC、笔记本、Jetson边缘设备;
云端旗舰层:Mistral Large 3(675B总参数,41B激活参数),采用混合专家架构(MoE),面向企业级复杂任务如长文档解析、多模态推理。
截至发布后24小时,Mistral 3全系列模型已在Hugging Face平台上线,同时支持通过NVIDIA NIM、IBM watsonx、Amazon Bedrock、Azure Foundry等主流服务商部署,累计下载量突破10万次,成为2025年末开源AI领域的“现象级项目”。

二、功能特色
Mistral 3的功能优势集中体现在“多模态融合”“全场景适配”“高性能低消耗”三大维度,具体特色如下:
1. 原生多模态能力,跨模态理解更精准
所有Mistral 3模型均具备文本+图像的原生处理能力(非简单模型拼接),通过“统一嵌入空间”技术,将文本token、图像patch映射到同一语义维度,实现跨模态信息的深度融合。例如:
开发者可输入“扫描版合同+文本提问”,模型能同时解析合同中的表格、签章与文字内容,精准回答“付款期限”“违约责任”等问题;
边缘设备部署的Ministral 3-8B模型,可实时接收摄像头画面,识别场景中的物体(如“工业设备故障部件”“农作物病虫害”)并生成文字报告。
此外,Mistral Large 3还支持“长文档+多图联合推理”,配合256K token的超大上下文窗口,可一次性处理300页PDF文档+50张图表,在法律合同分析、学术论文综述等场景中效率远超同类开源模型。
2. 全语言覆盖,打破跨文化沟通壁垒
Mistral 3在多语言支持上实现突破,原生覆盖40余种全球语言,包括英语、中文、法语、西班牙语等主流语言,以及印地语、越南语、加泰罗尼亚语、阿拉伯语等小众语言。在权威多语言评测集MT-Bench上,其非英语任务准确率比同级开源模型(如Qwen 14B)提升15%-20%,尤其在“小语种复杂句式理解”(如阿拉伯语法律文本、日语技术文档)上表现突出。
例如,用Ministral 3-14B Instruct模型处理“日语产品说明书翻译成越南语”任务,不仅能准确转换专业术语(如电子设备中的“端子”“回路”),还能保留原文档的格式结构,无需额外格式修复。
3. 性能与效率平衡,全硬件适配无压力
Mistral 3通过“架构优化+硬件协同”,实现“高性能”与“低消耗”的双重目标:
边缘模型(Ministral 3系列):在RTX 5090显卡上,14B模型推理速度可达385 token/秒;3B模型甚至支持在32GB内存的MacBook、Jetson Thor设备上离线运行,响应延迟低至35ms,满足语音交互、实时检测等低延迟场景需求;
云端模型(Mistral Large 3):借助NVIDIA TensorRT-LLM框架与NVFP4量化技术,在GB200 NVL72系统上每秒可处理500万+ token,同时将单次推理成本降低90%,即便在8×A100/H100节点上也能高效部署。
4. 多变体设计,场景适配更灵活
无论是基础预训练、指令交互还是复杂推理,Mistral 3都提供针对性变体,具体如下表所示:
| 模型变体 | 核心功能 | 适用场景 | 代表模型 |
|---|---|---|---|
| Base(基础版) | 未经指令微调的预训练模型,保留原始语言理解能力 | 专业领域微调(如医疗、金融行业定制模型) | Mistral 3-8B-Base |
| Instruct(指令版) | 经人类反馈强化学习(RLHF)训练,支持多轮对话、指令跟随 | 智能客服、聊天机器人、Copilot工具 | Mistral 3-14B-Instruct |
| Reasoning(推理版) | 强化数学、逻辑、代码能力,支持思维链(Chain-of-Thought)提示 | 数学计算、代码生成与调试、复杂问题分析 | Mistral 3-14B-Reasoning |
以推理变体为例,Ministral 3-14B-Reasoning在AIME '25数学竞赛中准确率达85%,代码生成能力比Qwen 14B提升17%,可独立完成“Python数据可视化脚本编写”“C++工业控制程序调试”等任务。
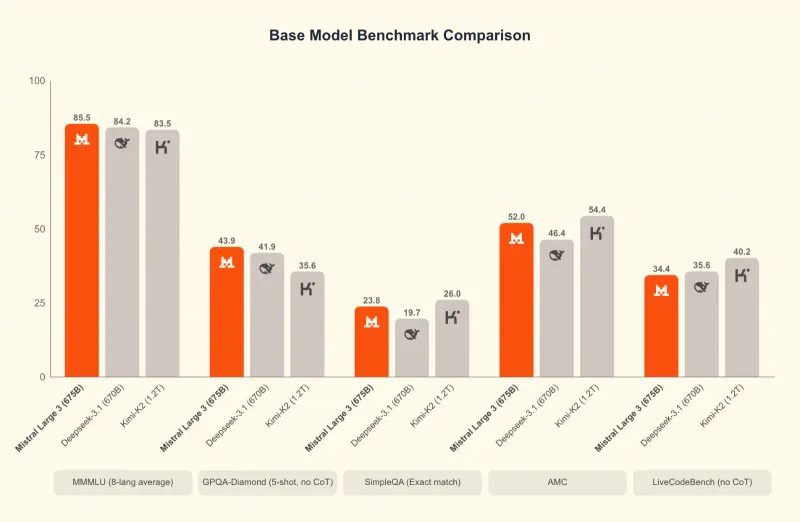
三、技术细节
Mistral 3的技术创新集中在架构设计、训练优化、部署适配三大层面,以下为核心技术解析:
1. 架构设计:从“密集型”到“稀疏型”的全覆盖
Mistral 3针对不同场景采用差异化架构,平衡性能与资源消耗:
Ministral 3系列(3B/8B/14B):采用密集型Transformer架构,优化注意力机制:
引入Grouped Query Attention(GQA):将注意力头分组,在“推理速度”与“效果保真度”间取优,比传统Multi-Head Attention推理效率提升30%;
集成Sliding Window Attention(滑动窗口注意力):处理长文本时仅关注局部窗口内容,降低计算复杂度,支持32K token上下文窗口(约24万字文本)。
Mistral Large 3(675B参数):采用混合专家架构(MoE),这是Mistral AI自Mixtral系列后的再次升级:
模型包含8个“专家模块”,每轮推理仅激活2个(激活参数41B),计算量仅为同参数密集模型的6%,大幅降低算力消耗;
引入“动态路由器”:通过注意力权重分析输入内容,智能选择最适配的专家模块(如文本任务激活“语言专家”,图像任务激活“视觉专家”),避免专家过载;
支持Wide Expert Parallelism(宽专家并行):将专家模块分布在多GPU上,解决MoE架构的通信瓶颈,在GB200 NVL72系统上实现专家协同效率提升50%。
2. 训练优化:数据与效率双管齐下
高质量训练数据工程:
数据规模:全系列模型训练数据总量达12T token,涵盖多语言文本(英语45%、中文15%、法语12%、其他28%)、GitHub高质量代码、arXiv学术文献、清洗后的网页内容;
数据过滤:采用“质量评分系统”自动剔除低质内容(如重复文本、错误信息),同时通过“知识蒸馏”从GPT-4、Claude等闭源模型提取专业知识,提升模型准确性。
训练效率优化:
混合精度训练:动态切换FP16/BF16精度,在保证效果的同时降低内存占用;
ZeRO优化器:实现分布式训练中的梯度、参数、优化器状态分片,支持3000块NVIDIA H200 GPU集群训练,将Large 3的训练周期压缩至45天;
专家负载均衡损失:针对MoE架构,通过损失函数调整专家激活频率,避免部分专家过度使用(激活率差异控制在10%以内)。
3. 部署适配:多硬件+多框架兼容
为降低部署门槛,Mistral 3与NVIDIA、Red Hat等企业深度合作,实现“全硬件覆盖+多框架支持”:
硬件适配范围:
边缘设备:Jetson Thor/Xavier、RTX PC/笔记本、32GB内存MacBook;
数据中心:DGX Spark、8×A100/H100节点、GB200 NVL72超级计算系统;
框架与格式支持:
推理框架:vLLM(全系列支持)、sglang(Large 3支持)、TensorRT-LLM(Large 3支持)、llama.cpp(Ministral 3系列支持)、Ollama(Ministral 3系列支持);
权重格式:Base变体提供BF16格式,Instruct变体提供FP8/Q4_K_M格式,Reasoning变体提供NVFP4/FP8格式,开发者可根据硬件性能选择(如边缘设备优先选Q4_K_M量化格式,内存占用降低60%)。
下表为Mistral 3核心模型的技术参数对比:
| 模型名称 | 总参数 | 激活参数 | 上下文窗口 | 多模态支持 | 推荐部署硬件 | 推理速度(GPU) |
|---|---|---|---|---|---|---|
| Ministral 3-3B | 3B | 3B | 32K | 文本+图像 | Jetson Thor、MacBook | 80 token/秒(RTX 4060) |
| Ministral 3-8B | 8B | 8B | 32K | 文本+图像 | RTX 3060+、DGX Spark | 150 token/秒(RTX 4090) |
| Ministral 3-14B | 14B | 14B | 32K | 文本+图像 | RTX 4060+、8×A10 | 85 token/秒(RTX 4090) |
| Mistral Large 3 | 675B | 41B | 256K | 文本+图像 | 8×A100/H100、GB200 NVL72 | 500万 token/秒(GB200 NVL72) |
四、应用场景
Mistral 3凭借“全规模覆盖+多能力支持”,可适配从个人开发到企业级应用的多样化场景,以下为典型场景示例:
1. 边缘设备场景:低资源下的实时智能
工业边缘检测:在Jetson Thor设备上部署Ministral 3-8B模型,实时接收生产线摄像头画面,识别设备故障部件(如齿轮磨损、线路松动),生成文字告警与维修建议,响应延迟<50ms;
移动终端交互:在32GB内存的MacBook上离线运行Ministral 3-3B-Instruct模型,实现“语音转文字+多语言翻译”功能,支持英语、中文、日语实时互译,无需联网;
农业现场诊断:将Ministral 3-14B-Reasoning部署到农业无人机,通过摄像头采集作物图像,识别病虫害类型(如小麦锈病、水稻稻飞虱),计算受灾面积并生成防治方案。
2. 企业级应用场景:高效处理复杂任务
法律合同分析:在8×A100节点上部署Mistral Large 3,一次性处理300页PDF合同+10张签章扫描图,自动提取“合同主体”“付款金额”“违约责任”等关键信息,生成结构化表格,效率比人工提升50倍;
金融风险控制:基于Ministral 3-14B-Base微调金融领域模型,分析企业财报文本与财报图表,识别“营收异常波动”“负债比例过高”等风险点,生成风险评估报告;
客服智能升级:用Ministral 3-8B-Instruct搭建多语言智能客服,支持40余种语言的多轮对话,可理解客户的“模糊需求”(如“我的订单还没到”),自动查询物流信息并给出解决方案。
3. 开发者工具场景:低门槛创新开发
代码辅助工具:基于Ministral 3-14B-Reasoning开发VS Code插件,支持Python、Java、C++等语言的代码生成、调试与注释添加,例如输入“编写Python数据可视化脚本,绘制折线图展示月度销售额”,插件可直接生成完整代码;
多模态内容创作:用Ministral 3-8B-Instruct开发内容生成工具,输入“生成一篇介绍AI模型的博客,配3张示意图描述”,模型可同时生成博客文本与示意图的文字描述(便于设计师快速作图);
学术研究助手:在PC上部署Ministral 3-14B模型,上传10篇AI领域学术论文,模型可总结“研究热点”“方法对比”“未来方向”,辅助撰写文献综述。
五、使用方法
Mistral 3支持多种部署方式,以下为“初学者友好型”使用指南,涵盖Hugging Face下载与NVIDIA NIM快速部署两种常用方法:
1. 从Hugging Face下载并本地运行(以Ministral 3-8B-Instruct为例)
前提条件
硬件:至少8GB VRAM(如RTX 3060)、16GB RAM;
软件:Python 3.10+、PyTorch 2.1+、transformers库、accelerate库。
步骤
安装依赖:
pip install torch transformers accelerate sentencepiece pillow
下载模型并加载:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig from PIL import Image # 配置4位量化(降低内存占用) bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16 ) # 加载模型与Tokenizer(模型名称来自Hugging Face) model_name = "mistralai/Ministral-3-8B-Instruct-2512" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=bnb_config, device_map="auto" # 自动分配GPU/CPU资源 ) # 处理文本+图像输入(示例:提问图像内容) image = Image.open("industrial_device.jpg") # 加载图像 prompt = "描述这张图片中的设备是否有故障,若有请指出故障位置:" # 生成模型输入 inputs = tokenizer( prompt, images=image, return_tensors="pt", padding=True ).to(model.device) # 推理生成 outputs = model.generate( **inputs, max_new_tokens=512, temperature=0.7, top_p=0.9 ) # 输出结果 print(tokenizer.decode(outputs[0], skip_special_tokens=True))
2. 用NVIDIA NIM快速部署(企业级场景)
NVIDIA NIM将Mistral 3打包为“即插即用”容器,支持几分钟内启动高性能端点,步骤如下:
安装NVIDIA NIM CLI:
curl -fsSL https://nvidia.github.io/nim-cli/install.sh | bash
登录NIM账号:
nim login
部署Ministral 3-14B-Reasoning:
nim run mistralai/mistral-3-14b-reasoning:latest \ --port 8080 \ --gpu-memory 16GB \ --quantization nvfp4 # 使用NVFP4量化
发送推理请求(通过API):
curl http://localhost:8080/v1/completions \ -H "Content-Type: application/json" \ -d '{ "prompt": "计算1+2*3-4/2的结果,并用步骤解释", "max_tokens": 200, "temperature": 0.1 }'
3. 模型微调(以Base变体为例)
若需针对特定领域微调(如医疗),可使用Hugging Face的transformers库与peft库实现高效微调:
from transformers import TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
# 配置LoRA微调(低秩适应,降低显存占用)
lora_config = LoraConfig(
r=8, # 秩
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 加载Base模型
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Ministral-3-8B-Base-2512")
base_model = get_peft_model(base_model, lora_config)
# 配置训练参数
training_args = TrainingArguments(
output_dir="./mistral-3-8b-medical-finetune",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
fp16=True # 混合精度训练
)
# 启动训练(需准备医疗领域数据集,格式为JSONL)
trainer = Trainer(
model=base_model,
args=training_args,
train_dataset=medical_dataset, # 自定义医疗数据集
tokenizer=tokenizer
)
trainer.train()
# 保存微调后的模型
base_model.save_pretrained("./mistral-3-8b-medical")
六、常见问题解答(FAQ)
1. Mistral 3的Apache 2.0协议具体意味着什么?可以商用吗?
答:Apache 2.0是最宽松的开源协议之一,对Mistral 3而言:
允许免费商用:无论个人还是企业,均可将Mistral 3模型或基于其修改的模型用于商业产品(如智能客服系统、付费API服务),无需向Mistral AI支付授权费用;
允许修改与二次分发:可修改模型代码、权重,甚至将修改后的模型重新发布(需保留原协议声明与版权信息);
无“贡献义务”:无需将修改后的代码或数据反馈给官方,自由度极高。
唯一限制是:若修改模型后重新分发,需在分发文档中明确标注“基于Mistral 3修改”,并包含原协议全文。
2. 没有高性能GPU,能运行Mistral 3吗?
答:可以。Mistral 3的Ministral 3系列针对低资源场景优化:
3B参数模型:最低需6GB RAM+4GB VRAM(如MX550显卡),可在普通笔记本上通过llama.cpp框架以4位量化格式运行,支持基础问答、文本生成;
CPU运行:若无GPU,可通过
transformers库的CPU推理模式运行3B模型,推理速度约10-15 token/秒(适合简单任务,如文本摘要);云端免费试用:Hugging Face Spaces提供Mistral 3的在线Demo,无需本地部署即可体验14B模型的多模态能力。
3. Mistral 3的多模态能力支持音频或视频吗?
答:当前Mistral 3全系列模型仅支持文本与图像输入,暂不支持音频、视频处理。若需实现“音频+文本”交互(如语音助手),可搭配开源音频模型(如Whisper)使用:先用Whisper将语音转文字,再将文字输入Mistral 3生成回答,最后用TTS模型将回答转为语音。
Mistral AI官方表示,未来将在后续版本中加入原生音频支持,但当前版本暂无相关计划。
4. 如何判断该选择Ministral 3的哪个变体(Base/Instruct/Reasoning)?
答:根据使用场景选择:
若需自定义训练(如训练医疗、金融领域专属模型):选Base变体,其保留原始预训练能力,适合作为微调基础;
若需直接用于对话或指令交互(如智能客服、聊天机器人):选Instruct变体,其经RLHF训练,能更好理解自然语言指令,支持多轮对话;
若需处理数学计算、代码生成、逻辑分析(如数学题解答、编程辅助):选Reasoning变体,其强化了推理能力,支持思维链提示。
例如:开发“金融客服机器人”,优先选Ministral 3-8B-Instruct;训练“医疗文献分析模型”,优先选Ministral 3-14B-Base。
5. Mistral 3与其他开源模型(如Llama 3、Qwen)相比,优势在哪里?
答:核心优势体现在三点:
全规模覆盖:从3B到675B参数,覆盖边缘到云端,无需为不同场景切换模型家族;
协议更宽松:Apache 2.0协议支持无限制商用,而Llama 3的商用需申请授权,Qwen部分模型采用非商业许可;
硬件适配更好:与NVIDIA深度合作,优化了从Jetson到GB200的全硬件部署,推理效率比同类模型高20%-50%(如Ministral 3-14B在RTX 4090上的推理速度比Qwen 14B快30%)。
七、相关链接
Mistral 3官方代码库:https://github.com/mistralai/mistral-3
Hugging Face模型库:https://huggingface.co/collections/mistralai/ministral-3
Mistral AI官网:https://mistral.ai/
八、总结
Mistral 3是Mistral AI推出的全规模开源多模态AI模型家族,以Apache 2.0协议为基础,通过“3B-675B参数梯队”覆盖从边缘设备到云端集群的全场景需求,所有模型均具备文本+图像的原生处理能力,支持40余种语言,在性能、效率与商用自由度上实现突破。其技术创新集中在混合专家架构(MoE)、NVFP4量化、全硬件适配等层面,可满足工业检测、法律分析、代码辅助等多样化需求,同时通过Hugging Face、NVIDIA NIM等平台降低部署门槛,让个人开发者与企业都能高效利用开源AI能力。作为2025年末开源领域的重要成果,Mistral 3不仅打破了闭源模型的性能垄断,更推动了“开源AI工业化应用”的进程,为全球AI生态的开放与普惠提供了新方向。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/mistral-3.html





