Ovis-Image:阿里开源的7B 参数轻量级AI文生图模型
一、Ovis-Image是什么
Ovis-Image是由阿里巴巴国际数字商务集团AIDC-AI团队基于Ovis-U1框架开发的一款轻量级开源文本到图像生成模型,核心参数量仅7B,却能在文本渲染任务上实现媲美20B级开源模型及GPT-4o等闭源模型的效果。
该模型通过创新的架构设计、文本聚焦的训练范式和高效的资源适配方案,攻克了传统文生图模型文本模糊、排版错乱的痛点,可在单块高端消费级GPU上部署,广泛适用于海报设计、UI原型制作、自媒体素材生成等场景,同时提供Diffusers库调用、本地代码部署、ComfyUI可视化操作等多种使用方式,为开发者和创作者提供了低成本、高精度的图文生成解决方案。
从参数规模来看,Ovis-Image的总参数量为10.02B,其中核心的视觉生成模块仅占7B,搭配2B级的Ovis 2.5多模态骨干网络作为文本语义理解核心,整体参数体量远小于Qwen-Image等20B以上的同类模型。但在实际性能上,该模型在LongText-Bench等专业基准测试中,英文文本渲染得分达0.922,中文得分0.964,超过GPT-4o的中文文本表现,在DPG-Bench等通用生成能力测试中也能与Seedream 3.0、Qwen-Image等模型持平,尤其在文本密集型场景中优势显著。
从定位来看,Ovis-Image并非追求“大而全”的全能型文生图模型,而是聚焦“文本渲染+布局对齐”的垂直领域,其核心使命是让普通开发者和创作者无需依赖超大规模模型和专业服务器,就能生成文字清晰、排版精准、语义一致的图文内容,实现“一次生成即可商用”的高效创作目标。
二、功能特色
Ovis-Image的功能优势集中体现在文本渲染能力、资源适配性和场景兼容性三大维度,具体如下:
高精度多语言文本渲染 Ovis-Image原生支持中英文双语文本生成,可精准还原手写体、艺术体、印刷体等多种字体风格,同时能实现文字大小、位置、排列方式的精准布局对齐。在海报、横幅、Logo、UI原型等文本密集型场景中,生成的文字不仅清晰可辨、拼写零错误,还能与图像主体的风格、色调保持统一,不会出现文本与画面割裂的情况。例如在生成武侠电影海报时,模型可同时还原“江湖侠客传”的艺术字体标题和角落的“XX影业出品”的小字标注,且两者的排版符合影视海报的行业规范。
小参数实现“越级”性能 相较于传统大参数模型“暴力堆参数量换性能”的思路,Ovis-Image通过架构优化和训练范式创新,用7B核心参数实现了媲美20B级开源模型的文本渲染效果,甚至在中文文本场景中超越GPT-4o等闭源模型。在OpenCompass多模态基准测试中,其底层的Ovis 2.5多模态骨干网络表现优于Qwen2.5-VL-7B,为文本语义与图像内容的精准对齐提供了保障。
消费级GPU可部署的高效性 模型整体架构做了极致的精简优化,摒弃了传统模型复杂的精炼器结构,直接以多模态大模型的隐藏状态作为生成条件,大幅降低了显存占用。用户仅需单块高端消费级GPU(如RTX 4090)即可完成本地部署,支持低延迟的交互式生成和批量生产服务,无需依赖专业的云端服务器或多卡集群,大幅降低了使用门槛。
多工具链适配的兼容性 Ovis-Image不仅支持Hugging Face的Diffusers库进行代码级调用,还已适配ComfyUI等可视化文生图工作流工具,同时提供完整的本地代码部署方案,覆盖了开发者、专业设计师、普通创作者等不同人群的使用习惯,且支持1024像素及以上的高分辨率生成,可满足商用素材的精度需求。

三、技术细节
Ovis-Image能实现“小参数、高性能”的核心原因,在于其创新的架构设计、文本聚焦的训练流程和高效的优化策略,具体技术细节如下:
1. 核心架构组成
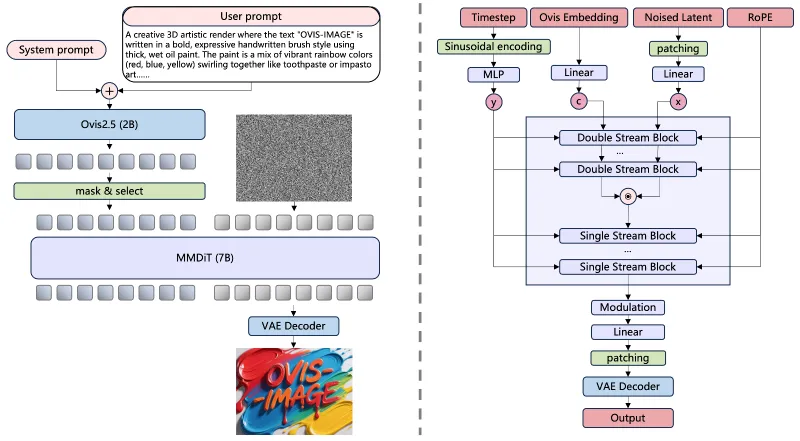
Ovis-Image的架构由三大模块精密协同构成,各模块分工明确且高度适配,具体如下表所示:
| 模块名称 | 参数量 | 核心功能 | 技术来源/创新点 |
|---|---|---|---|
| Ovis 2.5多模态骨干网络 | 2B级 | 文本语义理解、视觉-文本对齐 | 专为多模态数据训练,OpenCompass测试中优于Qwen2.5-VL-7B,提供精准语义指引 |
| 多模态扩散Transformer(MMDiT) | 7.37B | 图像生成与文本渲染核心 | 受Flux.1 Lite启发,含6个双流模块+27个单流模块,注意力头增至24个,激活函数升级为SwiGLU,提升复杂画面处理能力 |
| 变分自编码器(VAE) | - | 视觉信息压缩与解压 | 复用FLUX.1-schnell的VAE模块,训练全程冻结以保证视觉特征稳定性 |
这套架构的核心创新在于摒弃精炼器结构,直接将Ovis 2.5的最终隐藏状态作为MMDiT的生成条件,将计算资源集中在核心生成能力的构建上,而非后处理环节,实现了“架构做减法,能力做加法”的目标。
2. 文本聚焦的训练范式
Ovis-Image的训练流程分为四阶段,每个阶段均围绕“提升文本渲染精度”的目标设计,形成了完整的能力闭环:
预训练:搭建通用视觉基础 预训练阶段的MMDiT从随机初始化开始,在标准噪声预测损失的引导下学习海量异构语料的视觉规律。训练采用变分辨率机制,从256×256逐步过渡到512-1024像素,纵横比覆盖0.25-4.0,让模型适配不同尺寸的画布。训练数据不仅包含日常摄影和插图,还专门纳入设计资产、UI模型等文本密集型数据,并通过“数据切片”筛选出以文本为核心的样本,同时对中英文数据进行大规模重标注,解决了原始数据描述不准确的问题。
监督微调(SFT):适配指令式任务 该阶段模型从处理通用描述数据转向指令式监督数据,通过调低学习率、缩短训练时间表,在保留通用视觉能力的同时,学会将用户指令转化为高保真图像。训练数据的分辨率提升至1024像素,同时平衡自然图像与合成文本数据的配比,让模型既保证画面真实感,又能精准还原文本细节。
直接偏好优化(DPO):优化审美与准确性 此阶段引入人类和模型生成的偏好数据,对同一提示词生成“高质量优胜图”和“低质量失败图”,通过最小化Diffusion-DPO目标函数让模型模仿优胜图的生成轨迹。为避免优化过程中破坏已学的优质特征,模型还引入梯度缩放因子的获胜者保护机制,当失败图的梯度与优胜图冲突时,自动降低失败图梯度权重,保证优化的稳定性。
群组相对策略优化(GRPO):打磨文本渲染终极能力 这是Ovis-Image实现高精度文本生成的“杀手锏”。在该阶段,模型会针对同一文本提示生成一组候选图像,通过群组内的对比学习,强化模型对文本字体、大小、布局的精准把控能力,最终实现“文本与图像语义、排版双重对齐”的效果。
3. 高效的资源适配技术
为实现消费级GPU部署,Ovis-Image采用了**混合分片数据并行(HSDP)**技术,基于PyTorch框架在bfloat16混合精度下运行,大幅降低了显存占用和计算耗时。同时,其MMDiT模块的注意力机制经过针对性优化,在处理大分辨率图像时,不会出现显存直线飙升的情况,保证了低延迟生成的可行性。
四、应用场景
Ovis-Image的垂直化能力使其能覆盖多类人群的创作需求,具体应用场景如下:
专业设计师的高效初稿工具 对于品牌设计师、电商美工等专业从业者,Ovis-Image可快速生成海报、Banner、Logo等物料的初稿。例如生成产品宣传海报时,模型能同时还原产品主体、品牌Slogan、促销信息等元素,且文字排版符合行业规范,设计师无需再用PS单独调整文字位置和字体,可直接基于初稿进行精细化修改,大幅缩短设计周期。
自媒体创作者的素材生成利器 公众号、小红书、短视频等平台的自媒体博主,可通过Ovis-Image生成带清晰标题的封面图、图文素材。比如生成小红书美食笔记配图时,模型能在美食图片的指定位置生成“低脂健康早餐”的艺术字体标题,且标题风格与图片的清新质感保持一致,无需额外加字修图,提升内容产出效率。
职场人与学生的汇报辅助工具 职场人制作工作汇报、学生完成学术报告时,可利用模型生成定制化信息图表和数据可视化图,例如带标注的折线图、带流程说明的示意图等。生成的图表不仅数据标注清晰、文字排版工整,还能与PPT整体风格适配,让汇报内容更具专业性和说服力。
跨境从业者的双语物料生成工具 外贸商家、跨境电商从业者可通过Ovis-Image生成双语产品主图、国际会议物料,模型能精准渲染中英文对照的产品参数、品牌名称,且不会出现翻译错误或排版混乱的问题,大幅降低了跨境宣传物料的制作成本和时间成本。
五、使用方法
Ovis-Image提供了代码调用、本地部署、可视化工具操作三种使用方式,满足不同用户的需求:
通过Diffusers库快速调用 这是开发者最常用的轻量化调用方式,步骤如下:
需注意,为保证文本渲染效果,建议将采样步数设置为50,低于20步易出现文本模糊问题。
首先安装支持Ovis-Image的Diffusers库:
pip install git+https://github.com/huggingface/diffusers
然后通过
OvisImagePipeline实现图像生成,核心代码示例如下:from diffusers import OvisImagePipeline import torch pipe = OvisImagePipeline.from_pretrained("AIDC-AI/Ovis-Image-7B", torch_dtype=torch.bfloat16).to("cuda") prompt = "生成一张漫威英雄全家福海报,顶部有艺术字体标题'漫威宇宙集结',底部标注'2025年度巨献',风格为电影海报质感" image = pipe(prompt, num_inference_steps=50, guidance_scale=5.0).images[0] image.save("marvel_poster.png")本地代码完整部署 若需进行深度定制开发,可通过克隆仓库实现本地部署,步骤如下:
克隆仓库并创建专属环境:
git clone git@github.com:AIDC-AI/Ovis-Image.git conda create -n ovis-image python=3.10 -y conda activate ovis-image cd Ovis-Image
安装依赖并完成本地安装:
pip install -r requirements.txt pip install -e .
运行仓库内的测试脚本,指定模型路径、提示词等参数即可生成图像,具体参数可参考仓库README的配置说明。
ComfyUI可视化操作 对于非代码从业者,可通过ComfyUI实现可视化操作,步骤如下:
将ComfyUI更新至最新版本(官方已原生支持Ovis-Image);
下载Ovis-Image的主模型(14G的BF16版本)和专用文本编码器(5.14G),并放置到ComfyUI的模型目录;
在工作流中加载模型,设置分辨率(建议1024×1536的海报尺寸)、提示词、采样器(推荐Euler)、采样步数(50步)等参数,点击运行即可生成图像。
此外,用户还可直接在Hugging Face Spaces的Ovis-Image在线体验空间进行浏览器端试用,无需本地部署即可测试模型效果。
六、常见问题解答
Q:为什么生成的文本出现模糊或乱码?
A:主要原因是采样步数不足,Ovis-Image在处理文本时对采样步数要求较高,建议将步数设置为50步及以上,20步及以下易出现文本笔画粘连、排版错乱的问题;同时可适当调高guidance_scale至5.0,强化模型对文本指令的遵循度。
Q:本地部署时出现显存不足的提示怎么办?
A:可尝试开启bfloat16混合精度推理,同时关闭不必要的后台程序;若使用的是笔记本端GPU,可适当降低生成图像的分辨率(如从1024×1536降至768×1024),也可采用模型量化方案进一步降低显存占用。
Q:ComfyUI中无法加载Ovis-Image的文本编码器怎么办?
A:需确认下载的编码器为Ovis-Image专用版本,而非其他模型的编码器;同时检查ComfyUI的版本是否为支持Ovis-Image的最新版,若版本过低可通过官方仓库更新后重试。
Q:生成的图像中文本与提示词语义不符如何解决?
A:可优化提示词的描述精度,建议在提示词中明确文本的位置(如“顶部居中”“右下角”)、字体风格(如“宋体”“艺术体”)和大小比例,也可借助Gemini 3.0等大模型生成结构化提示词,提升模型对文本指令的理解准确度。
七、相关链接
八、总结
Ovis-Image是一款针对性解决文生图领域文本渲染痛点的轻量化开源模型,其以7B核心参数实现了“小体量、高性能”的突破,通过Ovis 2.5多模态骨干网络与MMDiT扩散模块的协同架构,结合四阶段文本聚焦训练范式,既保证了文本渲染的高精度和排版对齐的准确性,又实现了消费级GPU可部署的高效性。该模型提供了多工具链的使用方式,覆盖了开发者、设计师、自媒体创作者等多类人群的需求,在海报设计、UI原型、汇报图表、跨境物料等场景中具备极高的实用价值,同时开源的模型权重和代码为行业提供了可借鉴的文本图像生成技术方案,填补了轻量级开源模型在文本渲染领域的能力空白。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/ovis-image.html





