Qwen3.6-27B:阿里云开源稠密多模态大模型,旗舰级智能体编码与长文本推理引擎
一、Qwen3.6-27B是什么
Qwen3.6-27B是阿里云通义千问(Qwen)团队自研的新一代稠密(Dense)多模态大语言模型,于2026年4月22日正式发布并全面开源,采用Apache 2.0宽松开源协议,支持免费商用与二次开发。
核心基础信息
参数规模:270亿(27B)稠密参数,无MoE(混合专家)路由机制,所有参数参与推理,计算效率更高、部署更简单。
模型架构:基于Transformer的Gated DeltaNet+Gated Attention混合架构,兼顾长文本推理效率与显存优化。
上下文窗口:原生支持262,144 tokens(262K),可通过YaRN扩展至1,048,576 tokens(101万),一次性处理完整代码库、长篇文档或多轮对话无压力。
模态能力:原生多模态统一模型,单一Checkpoint同时支持文本、图像、视频、文档输入,无需额外视觉编码器,图文视频理解无缝衔接。
核心定位:旗舰级智能体编码模型,主打“以27B稠密参数,超越397B MoE旗舰性能”,在真实工程级编程任务中达到行业顶级水平。
核心突破
作为通义千问3.6系列的核心成员,Qwen3.6-27B打破了“大参数=强性能”的行业固有认知,以1/15于前代旗舰(Qwen3.5-397B-A17B)的参数量,在所有主流智能体编程基准上实现全面超越,同时保持稠密架构的简洁性与低成本部署优势,成为开源社区“性能密度”新标杆。

二、功能特色
Qwen3.6-27B集旗舰级编码、强推理能力、原生多模态、双模式智能切换、轻量化部署、全链路生态支持于一体,核心特色可分为六大维度:
1. 旗舰级智能体编码,性能碾压同规模与超大模型
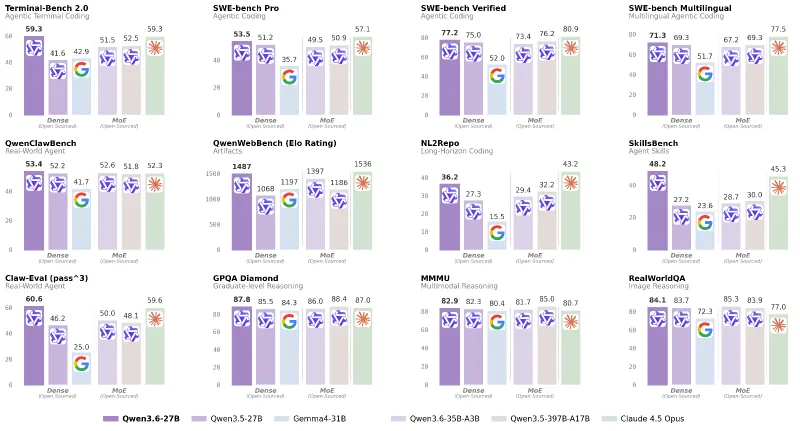
真实工程任务领先:在SWE-bench Verified(真实代码库修复)达77.2%,超越前代397B MoE模型(76.2%),仅比闭源顶级模型Claude Opus 4.6低3.7个百分点。
编码技能断层突破:SkillsBench(综合编程技能)达48.2%,较397B模型(30.0%)提升77%,实现性能翻倍。
终端与多语种编码强劲:Terminal-Bench 2.0(终端命令与脚本生成)达59.3%,与Claude 4.5持平;SWE-bench Multilingual(多语种代码)达71.3%,多语言开发场景适配性极强。
前端生成接近顶级闭源:QwenWebBench(前端代码生成)Elo评分达1487,可直接生成工业级可运行网页与交互应用。
2. 顶级文本推理与知识能力,媲美数倍参数模型
通用推理卓越:GPQA Diamond(科学推理)达87.8、C-Eval(中文能力)达91.4、MMLU-Redux(多语言知识)达93.5,在常识、数学、科学、人文等领域推理精准。
奥数级数学能力:AIME26(美国数学邀请赛)达94.1、IMOAnswerBench(奥数竞赛)达80.8,可解决复杂数学证明与高难度竞赛题。
长文本理解无压力:262K原生上下文支持,可一次性解析百万字文档、完整代码仓库或超长技术手册,长文本摘要、逻辑梳理、信息提取能力突出。
3. 原生多模态全链路理解,图文视频一体化处理
图像理解精准:MMMU(多模态科学推理)达82.9、RealWorldQA(真实场景问答)达84.1,支持图像描述、OCR文字提取、图表解析、空间推理。
视频理解连贯:VideoMME(视频多模态理解)达87.7、VideoMMMU(视频科学推理)达84.4,可处理视频内容摘要、动作识别、场景解读、时序逻辑分析。
文档与视觉智能体增强:支持PDF/扫描文档OCR解析、复杂版式文档理解、安卓界面交互(AndroidWorld达70.3)、网页视觉元素识别,适配办公自动化、文档智能处理、GUI自动化测试等场景。
4. 思考/非思考双模式,智能切换适配全场景
思考模式(Thinking):启用深度推理链,适合复杂编程、数学证明、多步骤推理、长文本分析等任务,输出严谨、逻辑清晰、细节完整。
非思考模式(Non-Thinking):快速响应、低延迟,适合日常对话、简单问答、短文本生成、轻量工具调用等场景,速度提升30%-50%。
思维保留机制(Preserve Thinking):多轮对话中自动保留历史思考链,任务连贯性大幅提升,特别适合多轮代码调试、迭代开发、复杂问题分步解决等智能体场景。
5. 稠密架构+深度量化,低成本部署,消费级硬件可运行
无MoE复杂度:稠密架构设计,无需复杂路由配置,推理稳定、调试简单、维护成本低,单卡即可部署。
多格式量化支持:提供BF16、FP8、INT4等多种量化版本,最低24GB显存即可流畅运行INT4量化版,普通消费级显卡(如RTX 4090、AMD Pro W7900)可直接部署,打破“27B模型必须服务器级硬件”的壁垒。
推理速度优异:FP8量化版单卡输出速度达90 token/s,满足实时对话、代码生成、多模态交互等低延迟需求。
6. 全链路生态支持,无缝对接主流工具与平台
在线体验:Qwen Studio官方平台直接交互,无需部署,开箱即用。
开源权重下载:Hugging Face、ModelScope双平台开放下载,支持本地私有化部署。
API服务:阿里云Model Studio提供API调用,兼容OpenAI/Anthropic协议,快速集成至现有应用。
编码助手无缝对接:原生支持OpenClaw、Claude Code、Qwen Code等主流AI编码工具,终端编程、代码仓库管理、自动化开发流程一键打通。
三、应用场景
Qwen3.6-27B凭借旗舰级编码、强推理、原生多模态、低成本部署四大核心优势,覆盖从个人开发者到企业级应用、从纯文本到多模态的全场景需求,典型应用场景如下:
1. AI编程助手与智能体开发(核心场景)
代码生成与补全:支持Python、Java、C++、Go、JavaScript等20+主流编程语言,生成工业级可运行代码,适配IDE插件、终端助手、自动化脚本生成。
代码仓库级智能开发:理解完整代码库结构,支持跨文件编辑、函数重构、Bug修复、版本迭代,适配开源项目维护、企业级系统开发、微服务架构设计。
终端智能体:对接OpenClaw/Qwen Code,实现终端命令自动生成、服务器运维自动化、脚本批量处理、容器化部署管理。
前端全链路开发:生成HTML/CSS/JavaScript代码,支持响应式网页、交互应用、数据可视化图表、3D网页元素开发,适配Web开发、小程序开发、H5应用制作。
2. 企业级内容创作与知识管理
长文本内容生成:撰写技术文档、产品手册、行业报告、学术论文、小说创作,支持百万字级长文本一次性生成,逻辑连贯、结构清晰。
多语言内容创作:支持201种语言互译与内容生成,适配跨境电商文案、多语言产品说明、国际市场报告、跨文化内容创作。
企业知识库问答:基于企业文档、知识库、产品资料构建智能问答系统,支持精准信息检索、复杂问题解答、知识图谱构建,适配客服机器人、内部知识助手、培训辅助工具。
文档智能处理:PDF/扫描文档OCR解析、内容摘要、关键信息提取、版式还原、多文档对比分析,适配办公自动化、档案数字化、合同审核、财务报表解析。
3. 多模态智能交互与视觉应用
图像理解与创作:图像描述、细节解读、图表解析、OCR文字提取、图像内容生成(如根据文本生成设计图、海报文案),适配设计辅助、内容创作、社交媒体运营。
视频内容分析:视频摘要、动作识别、场景解读、时序逻辑分析、关键帧提取、视频内容问答,适配短视频运营、教育视频解析、监控视频智能分析、影视内容创作辅助。
视觉智能体与GUI自动化:安卓/iOS界面交互、网页元素识别、自动化测试脚本生成、UI设计校验,适配APP自动化测试、GUI智能操作、无障碍辅助工具。
4. 教育、科研与个人助手
智能教育助手:学科知识问答、作业辅导、数学解题、编程教学、语言学习辅助,适配K12教育、高等教育、职业培训、成人学习。
科研辅助工具:学术文献摘要、论文润色、实验设计、数据分析代码生成、科研问题推理,适配自然科学、工程技术、人文社科等领域科研工作。
个人全能助手:日常对话、日程管理、邮件撰写、文案创作、信息检索、轻量工具调用,适配个人生活、工作、学习全场景智能辅助。
四、使用方法
Qwen3.6-27B提供在线体验、API调用、本地部署、编码工具集成四种主流使用方式,覆盖从快速试用到生产级部署的全流程,操作简单、门槛友好:
1. 在线体验(零部署,快速试用)
直接访问Qwen Studio官方平台(https://chat.qwen.ai),注册登录后选择“Qwen3.6-27B”模型,即可开始对话交互,支持文本、图像输入,体验思考/非思考双模式功能。
2. API调用(快速集成,生产级使用)
(1)准备工作
注册阿里云账号,开通Model Studio服务,获取API Key(DASHSCOPE_API_KEY)。
安装依赖:
pip install openai
(2)API调用代码(兼容OpenAI协议)
from openai import OpenAI
import os
# 配置API信息
api_key=os.environ.get("DASHSCOPE_API_KEY")
base_url = "https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
model_name = "qwen3.6-27b"
# 初始化客户端
client=OpenAI(api_key=api_key, base_url=base_url)
# 对话请求(启用思考模式)
messages = [{"role": "user", "content": "用Python写一个快速排序算法,并解释原理"}]
completion=client.chat.completions.create(
model=model_name,
messages=messages,
extra_body={"enable_thinking": True}, # 启用思考模式
stream=True # 流式输出
)
# 打印输出
for chunk in completion:
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="")
elif chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")3. 本地部署(私有化,自定义配置)
(1)环境要求
硬件:最低24GB显存(INT4量化版),推荐48GB+显存(FP8/BF16版),支持单卡/多卡部署。
软件:Python 3.9+、PyTorch 2.0+、transformers 4.40+、vLLM(推理加速,可选)。
(2)权重下载
从Hugging Face(https://huggingface.co/Qwen/Qwen3.6-27B)或ModelScope(https://modelscope.cn/models/Qwen/Qwen3.6-27B)下载对应量化版本权重。
(3)本地推理代码(基础版)
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载模型与分词器
model_name_or_path = "Qwen/Qwen3.6-27B" # 本地权重路径
tokenizer=AutoTokenizer.from_pretrained(model_name_or_path)
model=AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=True # 加载INT4量化版,降低显存占用
)
# 输入提示词
prompt = "用JavaScript写一个TodoList应用,包含增删改查功能"
inputs=tokenizer(prompt, return_tensors="pt").to("cuda")
# 生成输出
outputs=model.generate(
**inputs,
max_new_tokens=4096,
temperature=0.7,
top_p=0.95
)
# 打印结果
print(tokenizer.decode(outputs[0], skip_special_tokens=True))4. 编码工具集成(终端智能体,开发全流程)
以OpenClaw(开源AI编码智能体)为例,快速集成Qwen3.6-27B:
(1)安装OpenClaw
# macOS/Linux curl -fsSL https://molt.bot/install.sh | bash
(2)配置API Key
export DASHSCOPE_API_KEY="你的API Key"
(3)启动OpenClaw并关联模型
# 启动Web界面 openclaw dashboard # 或启动终端界面 openclaw tui
首次使用时,编辑~/.openclaw/openclaw.json,配置模型信息,关联Qwen3.6-27B,即可实现终端级智能编码、代码仓库管理、自动化开发。
五、竞品对比
选取当前开源社区主流同级别/相近定位模型:Llama 4.1 70B(Meta,稠密大模型)、DeepSeek-R1 33B(深度求索,编程优化模型),从核心参数、性能、能力、部署、生态五大维度对比,突出Qwen3.6-27B的优势:
表:Qwen3.6-27B vs Llama 4.1 70B vs DeepSeek-R1 33B
| 对比维度 | Qwen3.6-27B(通义千问) | Llama 4.1 70B(Meta) | DeepSeek-R1 33B(深度求索) |
|---|---|---|---|
| 参数架构 | 27B 稠密(Dense),无MoE | 70B 稠密(Dense),无MoE | 33B 稠密(Dense),编程优化 |
| 开源协议 | Apache 2.0(免费商用) | Meta商业许可(商用受限) | Apache 2.0(免费商用) |
| 上下文窗口 | 262K(原生)→101万(扩展) | 128K(原生) | 128K(原生) |
| 原生多模态 | ✅ 文本/图像/视频/文档 | ❌ 仅文本(需额外视觉模块) | ❌ 仅文本(纯编程) |
| 智能体编码(SWE-bench Verified) | 77.2% | 65.8% | 70.1% |
| 综合推理(GPQA Diamond) | 87.8% | 82.3% | 85.1% |
| 中文能力(C-Eval) | 91.4% | 78.5% | 88.2% |
| 最低部署显存 | 24GB(INT4量化) | 40GB(INT4量化) | 30GB(INT4量化) |
| 推理速度(FP8,单卡) | 90 token/s | 60 token/s | 75 token/s |
| 生态完善度 | ✅ 全链路生态(API/本地/编码工具) | ✅ 社区生态成熟,工具丰富 | ⚠️ 编程生态强,多模态生态弱 |
| 核心优势 | 性能密度最高、多模态一体化、中文强、部署友好 | 生态成熟、通用推理稳定 | 编程能力强、推理速度快 |
| 核心劣势 | 社区生态起步晚于Llama | 商用受限、无原生多模态、显存需求高 | 无多模态、中文能力弱、长上下文短 |
核心对比结论
性能密度碾压:Qwen3.6-27B以27B参数,在智能体编码、综合推理、中文能力上全面超越70B的Llama 4.1和33B的DeepSeek-R1,是当前开源社区性能密度最高的大模型。
多模态唯一原生:竞品均为纯文本模型,需额外集成视觉模块,而Qwen3.6-27B单一Checkpoint原生支持图文视频,多模态理解更高效、部署更简单。
部署门槛最低:24GB显存即可运行,远低于竞品,消费级显卡可直接部署,私有化成本更低。
中文能力断层领先:C-Eval达91.4%,远超竞品,中文场景适配性最佳,适合国内企业与开发者。
六、常见问题解答(FAQ)
1. Qwen3.6-27B是否完全开源?商用是否免费?
答:完全开源,采用Apache 2.0宽松开源协议,允许免费商用、二次开发、模型微调与权重分发,无版权费用,仅需保留原始版权声明即可。
2. Qwen3.6-27B和前代Qwen3.5-397B-A17B相比,优势在哪里?
答:核心优势有三点:① 参数更小、性能更强:27B稠密参数,在所有智能体编程基准上超越397B MoE模型,性能密度提升15倍+;② 部署更简单:稠密架构无MoE路由复杂度,推理稳定、调试方便、显存需求从100GB+降至24GB;③ 成本更低:训练与推理成本大幅降低,个人开发者与小微企业可轻松部署。
3. 普通消费级电脑(如RTX 4090,24GB显存)能否运行Qwen3.6-27B?
答:可以。提供INT4量化版本,最低24GB显存即可流畅运行,RTX 4090(24GB)可直接部署,支持文本生成、代码生成、图像理解等核心功能,推理速度可达30-50 token/s。
4. Qwen3.6-27B支持哪些编程语言?能否生成工业级可运行代码?
答:支持Python、Java、C++、Go、JavaScript、TypeScript、Rust、PHP等20+主流编程语言,针对真实工程场景优化,可直接生成可编译、可运行、符合工业规范的代码,支持跨文件编辑、函数重构、Bug修复、前端全链路开发。
5. Qwen3.6-27B的思考模式和非思考模式有什么区别?如何选择?
答:思考模式启用深度推理链,逻辑更严谨、细节更完整、准确率更高,适合复杂编程、数学证明、多步骤推理、长文本分析;非思考模式响应更快、延迟更低、算力消耗更少,适合日常对话、简单问答、短文本生成、轻量工具调用。可根据任务复杂度动态切换,API调用时通过enable_thinking参数控制。
6. Qwen3.6-27B能否进行多模态输入(图文结合)?支持哪些图像/视频格式?
答:支持原生多模态输入,单一Checkpoint无需额外视觉编码器,可同时处理文本+图像/视频。图像支持JPG、PNG、GIF、WebP等主流格式;视频支持MP4、AVI、MOV等格式,可处理视频内容摘要、动作识别、场景解读、时序逻辑分析。
7. 如何对Qwen3.6-27B进行微调?支持哪些微调方式?
答:支持全参数微调、LoRA微调、QLoRA微调三种主流微调方式,适配不同算力需求:全参数微调需80GB+显存,适合大规模数据训练;LoRA微调需24GB+显存,高效低成本;QLoRA微调需16GB+显存,消费级显卡可完成。官方提供微调脚本与文档,支持自定义数据集微调,适配行业场景、垂直领域优化。
8. Qwen3.6-27B的API调用是否稳定?有哪些地区节点?
答:API服务由阿里云Model Studio提供,高可用、低延迟、稳定可靠,支持弹性扩容与负载均衡。目前提供北京、新加坡、美国弗吉尼亚三大节点,可根据用户地域选择最优节点,支持OpenAI/Anthropic双协议兼容,快速集成至现有应用。
七、相关链接
官方博客(发布详情):https://qwen.ai/blog?id=qwen3.6-27b
Qwen Studio(在线体验):https://chat.qwen.ai
Hugging Face(权重下载):https://huggingface.co/Qwen/Qwen3.6-27B
ModelScope(权重下载):https://modelscope.cn/models/Qwen/Qwen3.6-27B
阿里云Model Studio(API服务):https://modelstudio.console.alibabacloud.com
官方GitHub(代码与工具):https://github.com/QwenLM/Qwen
八、总结
Qwen3.6-27B是阿里云通义千问团队推出的270亿参数稠密多模态旗舰大模型,以“小参数、强性能、易部署、全能力”为核心,在智能体编程领域实现里程碑式突破,全面超越前代397B MoE旗舰模型,同时具备原生多模态理解、262K超长上下文、思考/非思考双模式切换、深度量化低成本部署等核心能力,支持在线体验、API调用、本地私有化部署、主流编码工具集成等全链路使用方式,适配AI编程助手、企业内容创作、多模态智能交互、教育科研、个人全能助手等全场景需求。相较于Llama 4.1 70B、DeepSeek-R1 33B等竞品,Qwen3.6-27B在性能密度、多模态一体化、中文能力、部署门槛四大维度均具备显著优势,Apache 2.0宽松开源协议更使其成为个人开发者、小微企业、国内企业级应用的首选开源大模型,为AI技术普惠化与国产化落地提供了高性能、低成本、易落地的核心支撑。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/qwen3-6-27b.html





