Rapid-MLX:Apple Silicon 专属AI推理引擎,高速本地大模型运行与OpenAI API兼容
一、Rapid-MLX 是什么
Rapid-MLX 是一款基于苹果官方 MLX 机器学习框架二次封装优化的开源高性能本地大语言模型(LLM)推理服务引擎,专为Apple Silicon 全系列芯片(M1~M4)Mac 设备深度定制开发。该项目定位为生产级本地 AI 推理解决方案,核心作用是充分释放苹果统一内存架构与 Metal 计算内核的性能优势,解决传统本地大模型工具在 Mac 设备上推理速度慢、首 token 延迟高、工具调用不稳定等痛点。
Rapid-MLX 并非全新的底层架构,而是 MLX 框架的增强型服务层与运行时封装工具,在保留 MLX 原生高性能的基础上,补充了标准化 API 接口、缓存优化、模型适配、异常修复等工程化能力,可直接替代云端 OpenAI API,实现零成本、无网络依赖的本地 AI 推理,是目前 Apple 生态下本地大模型部署、开发、日常使用的优选工具之一。
二、功能特色
Rapid-MLX 围绕高性能、高兼容、易集成、强实用性四大核心方向打造功能体系,区别于原生 MLX 及同类工具,核心特色如下:
极致加速的本地推理能力
依托 MLX 底层与自研优化算法,推理速度远超主流跨平台本地模型工具,实测整体推理效率较 llama.cpp、传统 Ollama 提升 2~4.2 倍;搭配专属缓存技术,大幅降低对话场景下的响应延迟,长时间多轮对话依旧保持高速输出。全兼容 OpenAI 标准 API
完整实现 OpenAI/v1系列接口规范,原生适配 Cursor、Claude Code、Aider、LangChain、PydanticAI 等主流 AI 编辑器、开发框架与应用。开发者无需修改业务代码,即可一键将云端 API 切换为 Rapid-MLX 本地推理服务,迁移成本趋近于零。完善的工具调用与模型适配
内置 17 种专业工具解析器,全面适配 Qwen、DeepSeek、Gemma、Llama 等主流开源大模型;针对量化模型输出错乱、格式异常等常见问题做自动修复,保障代码生成、函数调用、指令解析等高级功能稳定运行。低延迟响应与智能缓存
集成 DeltaNet 状态快照与 KV 缓存双技术方案,缓存复用场景下首 token 响应延迟(TTFT)低至 0.08 秒,彻底解决本地模型“加载慢、等待久”的问题,人机交互体验接近云端服务。轻量化部署与低资源占用
优化内存调度逻辑,完美适配 Apple 统一内存架构,CPU、GPU 内存无需额外数据拷贝,降低硬件资源损耗;低配 16GB Mac 可流畅运行 7B~14B 量化模型,32GB 及以上机型可稳定承载 30B+ 大参数模型。纯本地离线运行
全程不依赖公网、不上传用户数据,所有推理、对话、文件处理均在本地设备完成,兼顾数据隐私安全与离线使用需求,适合办公、涉密开发、无网络环境等场景。

三、技术细节
Rapid-MLX 的性能优势源于底层架构、核心算法、硬件适配三大模块的深度优化,以下拆解核心技术原理与实现细节,通俗易懂讲解底层逻辑:
3.1 底层基础框架:Apple MLX
Rapid-MLX 以苹果官方 MLX 机器学习阵列框架 为底层基座,MLX 是苹果专为 Apple Silicon 芯片打造的原生框架,借鉴 NumPy、PyTorch 等主流框架设计,核心亮点为统一内存架构。传统跨平台工具需要在 CPU、GPU 之间反复拷贝模型数据,造成性能损耗,而 MLX 让 CPU、GPU 共享同一块物理内存,数据零拷贝,这也是 Rapid-MLX 天生适配 Mac 并提速的核心基础。
3.2 核心加速技术
KV 缓存优化:KV 缓存是大模型多轮对话的核心技术,Rapid-MLX 对原生 KV 缓存做扩容、复用、清理三重优化,多轮对话中重复加载模型上下文的开销大幅降低,持续对话越久,速度优势越明显。
DeltaNet 状态快照:首创会话状态快照机制,将用户对话上下文、模型运行状态快速保存与恢复,首次加载模型后,二次唤醒、切换会话无需重新初始化模型,直接实现毫秒级响应。
Metal 全链路硬件加速:深度调用 Mac Metal 图形计算接口,将模型推理、矩阵运算等密集型任务全部分配至 GPU 执行,充分挖掘 Apple Silicon 芯片的并行计算能力,区别于部分工具仅部分启用 GPU 加速的模式。
3.3 接口与协议层设计
Rapid-MLX 在 MLX 推理内核之上封装了标准化 HTTP API 服务层,严格遵循 OpenAI 接口协议,支持文本生成、对话补全、流式输出(Stream)、模型列表查询、参数配置等全接口能力。接口层采用轻量化网络架构,无冗余依赖,本地环回访问延迟可忽略不计。
3.4 模型兼容与量化适配
支持 MLX 标准模型格式(SafeTensors/NPZ),兼容 Hugging Face 平台所有适配 MLX 的开源模型;同时针对 4bit、8bit、Q4_K_M 等主流量化格式做专项适配,自动识别模型量化类型,无需用户手动配置参数,兼顾模型体积与推理精度。
3.5 运行环境依赖
仅支持 macOS + Apple Silicon(M1/M2/M3/M4 全系),不兼容 Intel 芯片 Mac、Windows、Linux 系统;运行依赖 Python 基础环境与 MLX 核心库,依赖包精简,无大型冗余组件,部署体积小。
四、应用场景
Rapid-MLX 凭借高性能、离线、API 兼容三大特性,覆盖个人、开发者、小型团队等多类使用场景,具体分类如下:
AI 代码开发与辅助
对接 Cursor、Claude Code、Aider 等 AI 代码编辑器,本地实现代码补全、bug 排查、项目逻辑梳理、脚本生成,告别云端 API 限流、收费、网络波动问题,适合程序员、全栈开发者日常编码。本地智能对话与办公助手
部署通用对话大模型,实现离线问答、文案撰写、文档总结、会议纪要整理、翻译等办公需求,保护企业内部文档、个人隐私数据不对外泄露。AI 应用二次开发与测试
基于 LangChain、PydanticAI 等框架开发私有 AI 应用、智能机器人、知识库问答系统,使用 Rapid-MLX 作为本地推理后端,降低开发成本,方便本地调试与功能验证。学生与 AI 技术学习
计算机、人工智能相关专业学习者,可在个人 Mac 上低成本运行开源大模型,学习 LLM 推理、API 对接、量化模型使用等技术,无需租用云端算力。涉密/内网离线场景
政企单位、保密工作室等无外网环境,或禁止数据外传的场景,搭建离线本地 AI 服务,满足内部智能办公、数据处理需求。长文本与批量处理
依托高速推理能力,批量处理长文档、小说、数据集、日志文件,完成文本拆分、摘要、分类、改写等批量任务。
五、使用方法
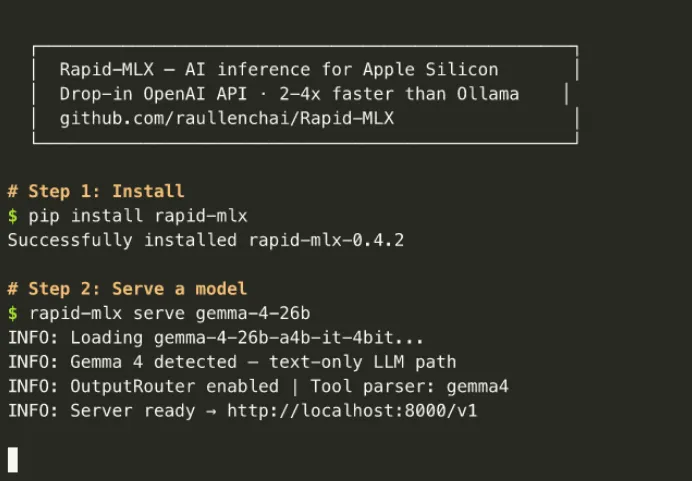
Rapid-MLX 基于命令行部署、启动与管理,整体流程简洁,分为环境准备、项目拉取、依赖安装、模型配置、服务启动、接口调用六大步骤,以下提供完整可执行流程与代码示例。
注意:全程操作基于 macOS 终端,需提前安装 Git 与 Python 3.9 及以上版本。
5.1 前置环境准备
检查 Python 版本,终端执行命令:
python3 --version
若未安装 Python,可通过官网或 Homebrew 安装推荐版本(3.9~3.12)。
5.2 拉取项目源码
通过 Git 克隆 Rapid-MLX 开源仓库,终端执行:
git clone https://github.com/raullenchai/Rapid-MLX.git cd Rapid-MLX
5.3 安装项目依赖
安装 MLX 核心库及项目所需依赖包:
pip3 install mlx mlx-lm transformers huggingface_hub -i https://pypi.tuna.tsinghua.edu.cn/simple
使用国内镜像源可大幅提升下载速度,避免依赖安装失败。
5.4 下载适配模型
Rapid-MLX 支持 Hugging Face 上所有 MLX 格式模型,以主流 Qwen 系列模型为例,两种下载方式:
命令行下载(推荐):
huggingface-cli download mlx-community/Qwen3.5-4B-Instruct-4bit --local-dir ./models/qwen-4b
手动下载:前往 Hugging Face 搜索
mlx-community仓库,下载模型文件后放入项目models文件夹。
5.5 启动本地推理服务
进入项目目录,执行启动命令,加载指定模型并开启 OpenAI 兼容 API 服务:
python3 rapid_mlx_server.py --model ./models/qwen-4b --port 8000
--model:指定本地模型存放路径;--port:指定 API 服务端口,默认 8000,可自定义修改。
5.6 接口调用测试
服务启动成功后,本地地址 http://127.0.0.1:8000/v1 即为标准 OpenAI 接口地址,可通过 curl、Postman 或 AI 工具对接。
终端 curl 测试示例:
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-4b",
"messages": [{"role": "user", "content": "介绍一下Rapid-MLX"}],
"stream": false
}'AI 编辑器对接:在 Cursor、Claude Code 等工具中,将 API 地址改为
http://127.0.0.1:8000/v1,API Key 随意填写(本地服务无需密钥),即可完成对接。
5.7 停止服务
终端按下 Ctrl + C 即可关闭本地推理服务。
六、竞品对比
选取 Mac 平台最主流的两款本地大模型工具 llama.cpp、Ollama 与 Rapid-MLX 进行全方位对比,从底层架构、推理性能、API 兼容性、硬件适配、生态、使用门槛等维度区分差异,方便用户按需选择。
| 对比维度 | Rapid-MLX | llama.cpp | Ollama |
|---|---|---|---|
| 底层架构 | 基于 Apple MLX 框架,Apple Silicon 原生优化 | 纯 C/C++ 跨平台推理引擎,通用底层 | 基于 llama.cpp 封装,新版部分集成 MLX |
| 主力适配硬件 | 仅 Apple Silicon(M1~M4 Mac) | 全平台(Mac/Windows/Linux/嵌入式设备) | 全平台,跨平台体验均衡 |
| 推理速度(Mac) | 最优,较 llama.cpp 快 2~4.2 倍,TTFT 低至 0.08s | 中等,传统主流方案,速度一般 | 新版略有提升,整体弱于 Rapid-MLX |
| OpenAI API 兼容 | 原生完整支持,无缝迁移 | 支持基础接口,功能不全 | 原生全接口支持,生态最完善 |
| 工具调用能力 | 内置17种解析器,自动修复模型异常,稳定性强 | 基础工具调用,无异常修复能力 | 工具调用常规,依赖模型本身能力 |
| 模型格式 | SafeTensors/NPZ(MLX 专用) | GGUF(社区通用格式) | GGUF,模型资源最丰富 |
| 内存优化 | 适配苹果统一内存,零数据拷贝,占用低 | 通用内存调度,Mac 上有数据拷贝损耗 | 内存调度均衡,介于两者之间 |
| 使用门槛 | 中等,需简单命令行操作 | 偏高,需手动编译、配置参数 | 极低,一行命令完成部署运行 |
| 核心优势 | Mac 设备极致性能、低延迟、离线安全 | 跨平台、兼容性极强、底层可控 | 上手最简单、生态庞大、模型库丰富 |
| 适用人群 | 追求 Mac 极致性能、代码开发、隐私优先用户 | 资深开发者、多设备部署、底层研究 | 新手用户、通用场景、跨平台团队 |
综合结论:纯 Apple Silicon Mac 用户,追求推理速度与本地开发,优先选择 Rapid-MLX;需要多系统部署、追求通用性选择 llama.cpp;纯新手、追求极简使用与丰富生态选择 Ollama。
七、常见问题解答
Q1:Rapid-MLX 可以在 Intel 芯片 Mac、Windows 或 Linux 上使用吗?
A:不可以。Rapid-MLX 深度依赖苹果 MLX 框架与 Apple Silicon 芯片的统一内存、Metal 计算能力,仅支持搭载 M1、M2、M3、M4 系列芯片的 macOS 设备,Intel 芯片电脑、Windows、Linux 系统均无法部署运行。
Q2:运行 Rapid-MLX 最低需要多大内存?不同模型对应内存要求是多少?
A:基础运行环境最低要求 16GB 统一内存。16GB 内存可流畅运行 4B~14B 量化模型;32GB 及以上内存可稳定运行 30B 及更大参数模型;内存不足会出现模型加载失败、推理卡顿、自动退出等问题,建议根据模型参数量匹配设备内存。
Q3:为什么启动服务后,AI 编辑器无法对接 Rapid-MLX 的 API?
A:首先检查服务端口是否被占用,默认 8000 端口冲突时可更换端口重启服务;其次确认 API 地址填写正确,必须使用本地回环地址 http://127.0.0.1:端口/v1;最后检查模型路径是否配置正确,模型文件损坏或缺失也会导致接口无响应。本地服务无需填写真实 API Key,随意字符即可通过校验。
Q4:Rapid-MLX 支持哪些格式的模型?去哪里下载可用模型?
A:仅支持 MLX 标准的 SafeTensors、NPZ 格式模型,不兼容 GGUF 等 llama.cpp 系列格式。推荐前往 Hugging Face 平台,搜索 mlx-community 官方仓库,该仓库收录了大量经过适配、测试可用的主流开源模型,可直接下载使用。
Q5:使用过程中出现模型输出乱码、格式错乱该如何解决?
A:Rapid-MLX 内置自动修复功能,轻度异常会自动处理;若频繁出现乱码,首先确认下载的是适配 MLX 的量化模型,非原生模型极易出现输出异常;其次更换模型版本,优先选择社区高星、高适配度的模型;最后重启服务重新加载模型即可。
Q6:Rapid-MLX 联网使用吗?用户对话数据会上传吗?
A:模型下载阶段需要联网,模型部署完成后,全程纯离线运行。所有对话、文本处理、代码生成等数据均保存在本地设备,不会向任何服务器上传用户数据,具备极高的数据隐私性。
Q7:相比原生 mlx-lm,Rapid-MLX 的优势体现在哪里?
A:原生 mlx-lm 仅提供基础推理能力,无标准化 API、缓存优化、工具解析等工程化功能;Rapid-MLX 在 mlx-lm 基础上封装了 OpenAI 全接口、KV 缓存、DeltaNet 状态快照、工具调用解析器、模型异常修复等实用功能,更偏向落地使用,而非单纯的技术测试。
八、相关链接
GitHub仓库地址:https://github.com/raullenchai/Rapid-MLX
九、总结
Rapid-MLX 是一款面向 Apple Silicon Mac 用户、基于苹果 MLX 框架优化的开源本地大模型推理服务引擎,它充分发挥了苹果芯片统一内存与 Metal 计算的硬件优势,在推理速度、响应延迟上大幅领先 llama.cpp、传统 Ollama 等同类工具,同时完整兼容 OpenAI 标准 API,实现了低成本、无缝对接各类主流 AI 开发工具与应用框架。该项目兼顾高性能、离线安全、部署便捷三大核心特点,内置的工具解析与模型异常修复能力解决了量化模型落地的常见问题,适配从个人编码辅助、离线办公到 AI 应用开发等多元化场景,是 Apple 生态下追求极致本地 AI 推理体验用户的优质选择,也是连接苹果原生 MLX 框架与实际生产应用的重要中间层工具。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/rapid-mlx.html