RynnBrain:阿里巴巴达摩院推出的开源具身智能基础模型
一、RynnBrain是什么
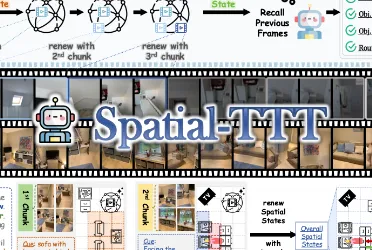
RynnBrain是阿里巴巴达摩院研发并开源的具身基础模型(Embodied Foundation Model),是全球首个聚焦移动操作、具备强时空记忆与物理空间推理能力的机器人大脑模型,于2026年2月正式开源代码、模型权重与全套工具链。
它以“扎根物理现实”为核心设计理念,统一理解、定位、推理、规划四大能力,解决传统机器人“转头就忘、空间幻觉、任务中断无法续接、精细操作难”等行业痛点,让机器人具备类人的场景记忆、空间感知与逻辑推理,实现从“被动执行指令”到“主动理解环境、自主规划任务”的升级。
RynnBrain基于通义千问Qwen3-VL系列底座训练,提供Dense密集架构(2B/8B)与MoE混合专家架构(30B-A3B),并推出物理推理(CoP)、任务规划(Plan)、视觉语言导航(Nav)三大专项模型,形成覆盖基础能力与垂直场景的完整模型体系,是面向家用服务、工业制造、医疗护理、商业服务等领域的通用具身智能底座。
二、功能特色
1. 全方位自我中心理解
以机器人第一视角为核心,擅长细粒度视频解析、场景认知、目标计数、视频内OCR等基础能力,可精准识别室内外环境中的物体、文字、属性与空间关系,回答“桌上有几个杯子”“柜子上的标签写了什么”等具身问答。
2. 多维度时空定位
具备强大的情景记忆时空定位能力,可在历史视觉序列中回溯并锁定:
物体位置与边界框
目标区域坐标点集
运动轨迹与路径
可操作点位(抓取位姿)
支持任务中断后恢复、跨视角空间匹配、动态目标追踪,彻底解决机器人“空间失忆”问题。
3. 物理空间交错推理
区别于纯文本思维链,采用文本推理+空间锚定交替执行的策略,每一步推理都绑定物理位置,大幅降低空间幻觉。例如执行“把香蕉放到桌子左下角”时,先识别物体→定位区域→绑定动作→输出可执行空间指令,让推理全程落地真实环境。
4. 物理感知精准规划
将物体功能属性(可抓取、可放置、可按压)与空间位置融合进任务规划,为下游VLA(视觉-语言-动作)模型输出细粒度、可直接执行的步骤指令,支持复杂长周期任务拆解、异常恢复、多任务优先级调度。
5. 轻量高效与高泛化
30B MoE模型仅激活约3B参数,推理速度快、显存占用低,性能超越72B密集型具身模型
通用视觉能力保留Qwen3-VL水准,同时在具身专项上大幅提升
少量数据微调即可适配家用、工业、医疗等不同场景
6. 全栈开源与开箱即用
开源全系列7个模型、推理代码、训练代码、11个Jupyter教程、专属评测基准RynnBrain-Bench,支持Hugging Face/ModelScope一键加载,兼容Transformers标准接口,降低二次开发成本。

三、技术细节
1. 模型体系与规格
RynnBrain采用统一编码器-解码器架构,同时支持Dense与MoE结构,将全视觉输入(图片/多图/视频)+文本指令转化为空间轨迹、物理指向、动作规划、坐标序列等多模态输出。
| 模型名称 | 底座 | 类型 | 核心用途 |
|---|---|---|---|
| RynnBrain-2B | Qwen3-VL-2B | Dense | 轻量级具身理解 |
| RynnBrain-8B | Qwen3-VL-8B | Dense | 通用具身理解与定位 |
| RynnBrain-30B-A3B | Qwen3-VL-30B | MoE | 高性能复杂规划与推理 |
| RynnBrain-CoP-8B | RynnBrain-8B | 微调 | 物理空间点链推理 |
| RynnBrain-Plan-8B | RynnBrain-8B | 微调 | 机器人任务规划 |
| RynnBrain-Plan-30B | RynnBrain-30B | 微调 | 超复杂长周期任务 |
| RynnBrain-Nav-8B | RynnBrain-8B | 微调 | 视觉-语言自主导航 |
2. 核心技术架构
(1)统一时空表示
将图像与视频作为统一输入模态,学习时间因果关系与运动动态,让机器人理解“从哪来、到哪去、经过什么”。
(2)物理坐标量化输出
用离散坐标Token表示空间位置,把连续物理控制转化为离散生成任务,模型可直接输出:
物体边界框
区域点集
运动轨迹
夹爪抓取位姿
实现语言指令到空间动作的精准映射。
(3)文本-空间交错推理
推理流程:文本理解 → 空间定位 → 文本续推 → 再空间锚定,循环执行直到任务完成,确保每一步逻辑都有物理位置支撑,杜绝“无中生有”的空间幻觉。
(4)训练工程优化
在线负载均衡:解决长序列样本拖尾问题,训练加速2倍
按样本损失归约:保证分布式训练稳定性
ZeRO/梯度检查点/专家并行:降低显存占用,提升吞吐
兼容Hugging Face Transformers,开箱即用
3. 训练数据与范式
采用两千万级多模态数据训练,覆盖:
通用视频-文本数据
自我中心(Ego)视频与具身问答
物体/空间/计数/定位标注数据
导航与操作规划数据
采用“预训练+专项微调”范式,基础模型学通用能力,专项模型用小数据对齐场景,兼顾泛化性与专业性。
4. 评测基准 RynnBrain-Bench
针对具身细粒度时空能力空白,推出四维评测体系:
物体认知
空间认知
空间定位
具身点预测
覆盖2000+细粒度场景,填补行业测评缺口。
5. 性能表现
16项具身开源Benchmark刷新SOTA
超越谷歌Gemini Robotics ER 1.5、英伟达Cosmos Reason 2
8项域外泛化评测领先同类具身模型
30B MoE仅激活3B参数,超越72B密集模型
四、应用场景
1. 家用服务机器人
物品查找、递取、整理
多步骤家务(倒水、端菜、收纳)
老人/儿童陪伴与安全监护
任务中断后自动续接(如中途避障、被打扰后恢复)
2. 工业制造机器人
产线装配、零件检测、物料搬运
复杂工序规划与异常恢复
动态环境避障与路径优化
人机协同作业
3. 医疗护理机器人
手术室器械传递、流程衔接
病房送药、监测、辅助行动
精准操作与安全空间约束
4. 商业服务机器人
商场/酒店导引、问答、配送
连续对话与场景记忆
顾客离开后返回可继续服务
5. 特种与公共服务
巡检机器人(机房、电力、管道)
救援机器人环境理解与路径规划
仓储物流拣选、分拣、上架

五、使用方法
1. 环境安装
最低依赖:
pip install transformers==4.57.1
推荐完整环境:
pip install torch torchvision transformers accelerate sentencepiece
2. 模型快速调用
基础文本+图像生成:
from transformers import AutoModelForImageTextToText, AutoProcessor # 替换为具体模型名 model_name = "Alibaba-DAMO-Academy/RynnBrain-8B" model = AutoModelForImageTextToText.from_pretrained(model_name) processor = AutoProcessor.from_pretrained(model_name) # 输入图片 + 指令 image = ... # 读取图片 prompt = "在图中定位杯子,并给出抓取位置" inputs = processor(images=image, text=prompt, return_tensors="pt") outputs = model.generate(**inputs, max_new_tokens=512) print(processor.decode(outputs[0], skip_special_tokens=True))
3. 仓库目录与使用
RynnBrain/ ├── demo.py # 快速演示脚本 ├── cookbooks/ # 11个官方教程Notebook ├── planning/ # 任务规划模块 ├── navigation/ # 视觉语言导航模块 ├── reasoning/ # 物理空间推理模块 └── rynnbrain-bench/ # 评测基准
4. 官方教程(Cookbooks)
空间理解
物体理解与计数
视频OCR
物体定位
区域定位
可操作点定位
轨迹定位
夹爪位姿预测
时空交错推理
操作规划
视觉语言导航
5. 模型微调
支持LoRA/全参数微调,面向规划、导航、推理等任务,仅需数百条样本即可达到SOTA效果,官方提供训练脚本与数据格式说明。

六、常见问题解答
Q1:RynnBrain和普通视觉语言模型(VLM)有什么区别?
A:普通VLM聚焦数字世界图文理解,RynnBrain专为物理世界机器人设计,具备时空记忆、空间坐标输出、物理交错推理、任务规划等具生专属能力,输出可直接驱动机器人执行动作,而非仅文本回答。
Q2:RynnBrain支持哪些机器人平台?
A:理论支持所有具备视觉输入与动作控制的机器人,包括轮式、四足、人形、机械臂等。只需将相机画面输入模型,把模型输出的坐标/轨迹/步骤解析为机器人控制指令即可。
Q3:30B-A3B MoE模型的推理成本高吗?
A:不高。它是稀疏激活模型,实际推理仅用约3B参数,速度与8B密集模型接近,显存占用更低,适合端侧与边缘设备部署。
Q4:是否支持视频输入?最长支持多少帧?
A:支持图片、多图、视频输入,官方教程提供视频处理示例,默认支持长序列上下文,最大可到16384 token,满足长视频时空理解需求。
Q5:没有机器人硬件可以使用RynnBrain吗?
A:可以。可在仿真环境(如AI2THOR、Habitat)中测试导航、规划、推理能力,官方Notebook提供纯视觉环境下的定位、计数、OCR等功能演示。
Q6:RynnBrain的开源协议是什么?
A:采用Apache 2.0开源协议,允许商业使用、修改、分发,自由度高。
Q7:如何解决机器人空间幻觉问题?
A:通过“文本-空间交错推理”,每一步推理都绑定真实位置坐标,并用物理空间约束输出,从模型架构层面降低幻觉。
Q8:微调一个行业专用模型需要多少数据?
A:官方实验显示,导航/规划/推理任务仅需数百条标注数据即可微调达到SOTA效果,数据成本极低。
Q9:支持Windows/macOS/Linux吗?
A:全平台支持,只要安装PyTorch与Transformers即可运行,Linux推荐用于训练与部署。
Q10:RynnBrain可以实时控制机器人吗?
A:可以。模型推理速度快,配合轻量化推理引擎(如SGLang、vLLM)可满足实时感知、规划与控制需求。
七、相关链接
GitHub开源仓库:https://github.com/alibaba-damo-academy/RynnBrain
项目官方主页:https://alibaba-damo-academy.github.io/RynnBrain.github.io/
Hugging Face模型集合:https://huggingface.co/collections/Alibaba-DAMO-Academy/rynnbrain
ModelScope模型集合:https://www.modelscope.cn/collections/DAMO_Academy/RynnBrain
Hugging Face在线Demo:https://huggingface.co/spaces/Alibaba-DAMO-Academy/RynnBrain
官方教程:https://github.com/alibaba-damo-academy/RynnBrain/tree/main/cookbooks
八、总结
RynnBrain是阿里巴巴达摩院面向具身智能推出的开源基础模型,以物理现实为核心锚点,整合时空记忆、物理空间交错推理、物理感知任务规划等关键能力,解决传统机器人空间失忆、环境理解弱、任务执行僵化、幻觉严重等行业痛点,提供2B/8B密集架构与30B MoE稀疏架构及规划、导航、物理推理专项模型,在16项具身评测上达SOTA水平,超越国际主流同类模型。项目全栈开源代码、权重、教程与评测基准,兼容标准大模型生态,轻量化高效能,少量数据即可微调适配家用、工业、医疗、商业等场景,为机器人提供通用、可靠、可落地的“大脑”,降低具身智能技术门槛,推动机器人从机械执行工具向具备场景理解、记忆、推理与规划能力的自主智能体进化,是当前具身智能领域最具实用性与前瞻性的开源底座之一。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/rynnbrain.html