STARFlow-V:苹果开源的归一化流架构端到端视频生成模型
STARFlow-V是什么
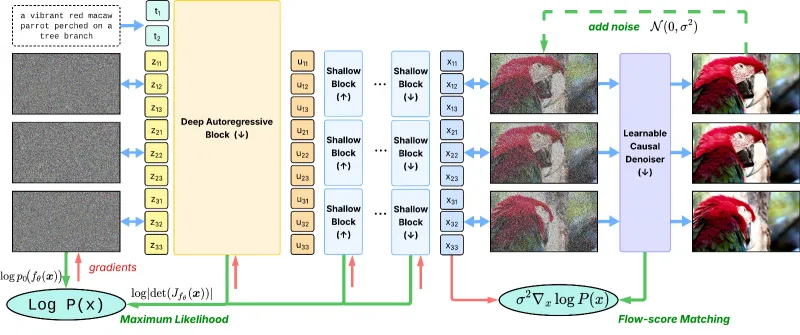
STARFlow-V是苹果团队研发的首款基于归一化流的因果视频生成模型,打破了视频生成领域扩散模型的技术垄断。该模型采用全局-局部架构实现时空特征解耦,结合流分数匹配去噪和视频感知雅可比迭代技术,既实现了端到端训练、精确似然估计的技术突破,又具备原生支持文本到视频、图像到视频、视频到视频等多任务的能力。模型基于70M文本-视频对与400M文本-图像对完成训练,7B参数规模可生成480p/16fps的高质量视频,同时支持10-30s长视频分段创作,在视觉质量与生成效率上媲美主流扩散模型,为多场景视频内容创作提供了全新技术方案。
从技术定位来看,STARFlow-V并非对现有扩散模型的简单补充,而是重构了视频生成的技术范式:它以归一化流为基础,在时空潜空间完成特征建模,既保留了扩散模型的高视觉保真度,又新增了端到端训练、精确似然估计、原生多任务支持等独有的技术优势。从训练数据与规模来看,该模型依托70M文本-视频配对数据和400M文本-图像配对数据完成预训练,最终形成7B参数规模的模型,可稳定输出480p分辨率、16fps帧率的视频内容,单段基础视频时长为5s,同时支持扩展至10-30s的长视频创作。
STARFlow-V的发布填补了归一化流在高质量视频生成领域的空白,其技术论文已提交至arXiv(预印本即将公开),相关代码也已规划开源,为学术界和工业界提供了全新的视频生成技术基准。

功能特色
STARFlow-V的功能特色围绕“技术创新性”“多任务适配性”“生成高效性”三大核心维度展开,具体可分为以下6个方面,其核心能力与传统扩散模型的对比如表1所示:
表1 STARFlow-V与传统扩散视频模型核心能力对比
| 能力维度 | STARFlow-V | 传统扩散视频模型 |
|---|---|---|
| 训练方式 | 端到端训练,流程一体化 | 分阶段训练(先预训练再微调),流程割裂 |
| 似然估计 | 支持精确似然计算,可量化生成质量 | 无精确似然估计能力,仅能主观评估 |
| 多任务支持 | 无需改架构,原生支持T2V/I2V/V2V | 需针对性修改模型结构或额外微调 |
| 误差控制 | 全局-局部架构缓解时序误差累积 | 自回归生成易出现误差复合问题 |
| 采样效率 | 视频感知雅可比迭代实现并行采样 | 多步去噪采样,整体效率较低 |
| 长视频创作 | 分段自回归生成,支持10-30s内容 | 长视频易出现时序断裂,适配性差 |
首创归一化流视频生成范式 STARFlow-V是首个证明归一化流可实现高质量视频生成的模型,其生成的视频在视觉保真度、时序一致性上可媲美NOVA、WAN-Causal等主流自回归扩散模型,同时解决了扩散模型无法进行精确似然估计的痛点,可通过量化指标评估生成内容与真实数据的分布契合度。
端到端一体化训练 不同于扩散模型“先训练去噪器、再设计采样器”的分阶段流程,STARFlow-V采用端到端训练模式,将特征建模、时序推理、细节优化等模块整合为统一架构,通过最大似然与流分数匹配的联合目标完成训练,大幅简化了模型的训练流程与部署成本。
原生多任务适配能力 依托归一化流的可逆结构,STARFlow-V无需修改任何架构,即可原生支持三大核心任务:
文本到视频(T2V):输入自然语言描述,直接生成符合场景、风格、动作要求的视频,涵盖动物行为、自然景观、人文活动等数十类场景;
图像到视频(I2V):基于单张输入图像,拓展出时序一致的动态视频,实现静态图像的“动起来”;
视频到视频(V2V):对已有视频进行内容编辑,包括添加物体(如给画面加手、加马)、内容转换(如橙子转柠檬)、图像修复、画面扩边等,同时保持原有视频的时序逻辑。
高效长视频创作 针对传统模型长视频生成易断裂的问题,STARFlow-V采用分段自回归生成策略:将长视频拆分为5s基础片段,把前一片段的尾部内容重新编码为下一片段的前缀,依托归一化流的可逆性实现片段间的无缝衔接,可稳定生成10s、15s甚至30s的长视频,如30s的金 doodle 玩玩具、纸灯笼夜市场景等。
轻量因果去噪优化 模型内置基于流分数匹配的轻量因果去噪器,该去噪器与主模型联合训练,可在不破坏因果时序的前提下,对生成的视频进行单步细节优化,大幅提升视频的帧间一致性,减少画面抖动、物体形变等问题。
并行化高效采样 通过视频感知雅可比迭代技术,STARFlow-V将传统的逐帧自回归生成转化为块级并行更新,同时结合相邻帧的时序信息完成初始化,在保障生成质量的前提下,显著提升采样效率,降低了视频生成的时间成本。
技术细节
STARFlow-V的技术架构围绕“全局-局部时空建模”“流分数匹配去噪”“视频感知雅可比迭代”三大核心模块构建,其整体流程为:文本/图像/视频输入→潜空间编码→全局时序推理→局部细节优化→去噪器精炼→视频解码输出,具体技术原理如下:
1. 全局-局部架构:解耦时空特征,缓解误差累积
传统自回归视频模型直接在高维像素空间逐帧生成,易出现误差随时间放大的问题。STARFlow-V创新采用全局-局部双层架构,在压缩的时空潜空间完成特征建模,实现时序推理与细节建模的解耦:
全局层:深层自回归Transformer块 该模块负责长程时序依赖捕捉,在低维潜空间对视频序列进行自回归处理。它严格遵循因果约束,即当前帧的特征仅依赖于之前帧的信息,避免未来信息泄露;同时通过Transformer的注意力机制,建模帧与帧之间的动作关联、场景逻辑,比如“柯基从坐立到伸懒腰”的动作连贯性、“海浪从远处到拍岸”的空间递进关系。
局部层:浅层流块 该模块负责单帧内的细节建模,每个浅层流块独立处理单帧潜特征,不参与跨帧的时序推理。其核心作用是还原帧内的纹理、色彩、物体细节,比如熊猫毛发的质感、火焰的明暗变化,从而在保障时序一致性的同时,提升单帧的视觉丰富度。
这种架构将时序误差限制在低维全局潜空间,避免了像素空间的误差复合,大幅提升了视频的整体生成质量。
2. 流分数匹配:联合训练,优化生成一致性
为解决归一化流在复杂数据建模上的精度短板,STARFlow-V提出流分数匹配(Flow-Score Matching) 训练框架,将归一化流的最大似然目标与去噪器的分数匹配目标结合,实现主模型与去噪器的联合训练:
最大似然目标:用于优化归一化流的可逆映射能力,让模型学习真实视频数据的分布,保障生成内容的基础合理性;
流分数匹配目标:用于训练轻量因果去噪器,该去噪器可预测模型自身分布的“分数”(即对数概率的梯度),从而在生成过程中对潜特征进行单步精炼,修正时序抖动、物体形变等问题,同时严格遵循因果约束,不引入未来帧的信息。
相较于传统模型的独立去噪模块,该框架下的去噪器与主模型深度协同,既提升了视频一致性,又未增加额外的训练与部署负担。
3. 视频感知雅可比迭代:并行采样,提升生成效率
传统自回归模型需逐帧生成视频,效率极低。STARFlow-V将视频生成的流逆过程转化为非线性系统求解问题,提出视频感知雅可比迭代技术,实现潜变量的块级并行更新:
并行化更新:将视频序列划分为多个潜变量块,通过雅可比迭代实现多块同时更新,替代传统的逐帧生成,大幅缩短采样时间;
视频感知初始化:在迭代开始前,利用相邻帧的时序信息初始化当前块的潜变量,让初始状态更贴合视频的时序逻辑,减少迭代次数;
流水线执行:将全局Transformer块与局部浅层流块的计算流程进行流水线调度,实现不同模块的并行处理,进一步提升整体生成效率。
4. 模型训练数据与规模
STARFlow-V的训练数据与参数配置决定了其生成能力的上限,具体信息如下:
训练数据:模型训练集包含70M高质量文本-视频配对数据和400M文本-图像配对数据,覆盖动物、自然、人文、科幻等多类场景,保障了模型对不同内容的理解与生成能力;
参数规模:最终模型为7B参数规模,在保障生成质量的同时,兼顾了部署的可行性;
生成规格:基础生成规格为480p分辨率、16fps帧率、5s时长,长视频可通过分段生成拓展至10-30s。
应用场景
STARFlow-V凭借其多任务适配、高质量生成、高效采样的特性,可覆盖学术研究与商业创作两大领域的多个场景,具体如下:
1. 学术研究场景
视频生成技术研究:作为首个归一化流视频生成模型,STARFlow-V为学术界提供了全新的技术基准,可用于对比归一化流与扩散模型的技术优劣,探索更高效的视频生成范式;
时空因果建模研究:其全局-局部架构与因果去噪器,为时序数据的因果推理研究提供了参考,可拓展至行为预测、时序逻辑分析等领域;
似然估计量化研究:模型的精确似然估计能力,可用于构建视频生成质量的量化评估体系,解决传统模型仅能主观评估的痛点。
2. 商业内容创作场景
创意短视频生产:自媒体、营销从业者可通过文本到视频功能,快速生成产品宣传、科普讲解、剧情短片等内容。例如,输入“柯基戴霓虹墨镜在阳光码头的无人机环绕镜头”,即可生成符合营销调性的短视频,无需专业拍摄团队;
静态素材动态化:设计师、广告商可利用图像到视频功能,将海报、插画等静态素材转化为动态视频,比如把景区宣传海报拓展为“树叶飘落、湖水波动”的动态宣传片,提升素材的复用价值;
视频快速编辑:影视后期、短视频创作者可通过视频到视频功能,实现视频的快速修改,如给美食视频添加“蒸汽升腾”的特效、将画面中的橙子替换为柠檬、对残缺画面进行修复,大幅降低后期制作成本;
长视频内容创作:影视编剧、动画创作者可利用其长视频生成能力,快速制作剧情样片、动画分镜,比如生成30s的“机器人打太极”科幻短片,验证创意可行性。
3. 其他拓展场景
虚拟数字人动作生成:结合图像到视频功能,可为虚拟数字人生成连贯的肢体动作,用于直播、虚拟交互等场景;
教育内容可视化:教师可输入知识点描述,生成动态视频,如“行星公转”“化学反应过程”等,提升教学的直观性;
游戏场景动态生成:游戏开发者可快速生成游戏内的动态场景,如“风吹过的森林”“雨夜的街头”,丰富游戏的场景库。
常见问题解答
1. STARFlow-V与扩散视频模型的核心区别是什么?
答:两者的核心区别在于技术底座与能力特性:STARFlow-V基于归一化流构建,支持端到端训练、精确似然估计,且无需改架构即可适配多任务,同时通过雅可比迭代实现高效采样;而扩散模型基于去噪扩散过程,需分阶段训练,无精确似然估计能力,多任务适配需额外微调,且采样需多步去噪,效率较低。在生成质量上,两者视觉效果相当,但STARFlow-V的时序一致性更优。
2. STARFlow-V为何能支持多任务而无需修改架构?
答:核心原因是其归一化流的可逆结构:归一化流可实现数据在像素空间与潜空间的双向可逆映射,对于不同任务,仅需调整输入到潜空间的编码方式即可:文本任务通过文本编码器生成潜空间初始状态,图像任务通过图像编码器转化为潜特征,视频任务则通过逆向映射将原视频转为潜特征后再编辑,因此无需改动模型的核心架构。
3. STARFlow-V长视频生成的分段策略有什么优势?
答:其分段自回归策略的优势在于两点:一是时序衔接性,通过前一段尾部潜特征作为下一段前缀,依托归一化流的可逆性保障片段间的逻辑连贯,避免长视频的帧断裂;二是资源可控性,将长视频拆分为5s片段,可降低单次生成的显存占用,让普通GPU也能支持长视频创作。
4. STARFlow-V的生成短板是什么?如何规避?
答:模型目前的短板是复杂运动与物理交互场景生成效果欠佳,如狗甩水、滑板豚跳、物体碰撞等场景,易出现动作失真、逻辑错误。这一问题源于训练资源受限、训练数据质量不足,且未进行监督微调(SFT)或强化学习(RL)后优化。若需规避,可针对特定场景补充高质量训练数据,或在生成后通过专业后期工具进行细节修正。
5. STARFlow-V的部署门槛高吗?
答:模型为7B参数规模,部署门槛低于大尺寸扩散模型:在硬件层面,高性能GPU(如A100)可实现实时生成,普通GPU(如RTX 3090)可通过模型量化实现离线生成;在软件层面,官方将提供完整的依赖包与部署脚本,同时支持PyTorch框架的常规优化手段,便于开发者快速部署。
相关链接
总结
STARFlow-V是苹果团队推出的首款基于归一化流的因果视频生成模型,它以全局-局部架构实现时空特征解耦,结合流分数匹配去噪与视频感知雅可比迭代技术,既实现了端到端训练、精确似然估计的技术突破,又具备原生支持文本到视频、图像到视频、视频到视频的多任务能力,同时可通过分段策略完成10-30s长视频创作。该模型基于70M文本-视频对与400M文本-图像对完成训练,7B参数规模可稳定输出480p/16fps的高质量视频,其生成质量媲美主流扩散模型,且采样效率更高,虽在复杂物理交互场景存在短板,但整体为视频生成领域提供了全新的技术范式,无论是学术研究还是商业内容创作,都具备极高的应用价值与参考意义。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/starflow-v.html





