Vidi2:字节跳动开源的多模态视频理解与生成模型
Vidi2是什么?
Vidi2是字节跳动智能创作与编辑团队研发的开源大型多模态视频理解与生成模型,作为初代Vidi的迭代升级版本,新增细粒度时空定位(STG)和视频问答(Video QA)核心能力,可通过文本查询精准识别视频时间戳与目标物体边界框,同时在时间检索任务中保持行业领先性能。该模型依托VUE-STG(时空定位)和VUE-TR-V2(时间检索)两大优化基准数据集,在关键任务上显著优于Gemini 3 Pro、GPT-5等闭源模型,且在视频QA任务中与同规模开源模型表现相当。
作为面向下一代视频创作的核心技术工具,Vidi2的核心定位是“打通视频理解与生成的全链路”——其实现了从“片段检索”到“精准定位+深度理解”的跨越。其本质是一款以“文本-视频多模态融合”为核心的开源工具,旨在通过AI技术降低复杂视频处理的门槛,为开发者、视频创作者、企业用户提供高效、可扩展的视频智能处理解决方案。
Vidi2的研发背景源于互联网视频生态的快速发展:视频已成为全球主流的沟通与创作媒介,市场对“规模化、高质量视频生产”的需求日益迫切。传统视频编辑依赖人工操作,效率低下且精准度不足;现有视频AI工具多局限于单一功能(如单纯检索或简单剪辑),缺乏对“时空信息+语义理解”的深度融合能力。Vidi2的出现正是为了解决这一痛点,通过端到端的多模态推理,让机器能像人类一样“看懂”视频的内容、结构与细节,并支持直接用于复杂编辑场景。
功能特色
Vidi2的功能特色围绕“更精准的理解、更全面的能力、更实用的落地”三大核心展开,相比同类模型,其优势集中在以下4个方面:
1. 核心能力突破:细粒度时空定位(STG)
这是Vidi2最关键的新增功能,也是其区别于初代Vidi及其他视频模型的核心亮点。传统时空定位工具往往只能识别视频片段的时间戳(“何时”),而Vidi2实现了“时间戳+边界框”的双重精准定位(“何时+何地”):
输入:自然语言文本查询(如“穿棕色西装在室内打鼓的男人”“星空下站在暖光小屋外的男孩”);
输出:匹配查询的视频片段时间范围(精确到秒级),以及片段内目标物体的像素级边界框(Bounding Box)。
这种“端到端”的时空定位能力无需额外预处理或后处理,直接打通了“文本描述→视频精准片段+目标物体”的链路,为复杂编辑场景提供了核心技术支撑。
2. 能力全面拓展:新增视频问答(Video QA)
Vidi2首次将视频问答能力纳入核心功能,支持基于视频内容的多模态推理:用户可针对视频提出具体问题(如“视频中主角使用的工具是什么?”“第3分钟出现的物体在第几秒消失?”),模型能结合视频的视觉、音频信息及文本查询,给出准确答案。这一功能让Vidi2从“被动检索”升级为“主动理解”,不仅能找到视频片段,还能解读片段内的关键信息。
3. 性能行业领先:基准测试表现突出
Vidi2在两大核心基准测试中展现出卓越性能,全面超越主流闭源模型并比肩开源模型:
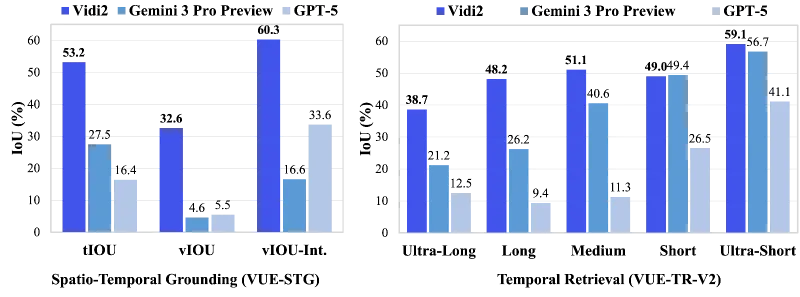
时间检索任务(VUE-TR-V2基准):显著优于Gemini 3 Pro(Preview)、GPT-5等顶尖闭源系统,能从超短(<1分钟)到超长(>60分钟)的全时长视频中精准检索匹配片段;
时空定位任务(VUE-STG基准):在多片段评估中以vIoU/tIoU/vIoU-Intersection指标超越同类模型,人工标注的高精准数据进一步保障了结果可靠性;
视频QA任务:与同规模热门开源模型表现相当,在通用视频理解场景中具备强竞争力。
4. 适配实用场景:支持全时长视频与多样化查询
Vidi2及配套基准数据集充分考虑了实际应用场景的复杂性,具备两大适配优势:
视频时长覆盖广:支持从10秒(超短)到60分钟以上(超长)的全时长视频处理,满足短视频剪辑、长视频内容提取等不同需求;
查询形式多样化:支持关键词、短语、完整句子三种格式,兼容视觉、音频、“视觉+音频”三种模态,贴合用户日常搜索习惯(如“快速剪辑”用关键词,“精准定位”用句子)。

技术细节
Vidi2的核心技术优势源于“模型架构优化”与“基准数据集创新”的双重支撑,以下从关键技术方向、数据集设计、评估体系三方面展开说明:
1. 核心技术方向:多模态融合与端到端推理
Vidi2采用“视觉-音频-文本”三模态融合架构,核心技术亮点包括:
跨模态对齐:通过预训练阶段的大规模数据学习,实现文本语义与视频时空信息(帧画面、时间序列)、音频信息(语音、环境音)的精准对齐,确保文本查询与视频内容的匹配度;
端到端时空定位:摒弃传统“先检索时间片段,再检测物体”的两阶段方案,设计统一的多模态编码器,直接输出时间戳与边界框,减少误差累积,提升处理效率;
长上下文建模:针对超长视频(>30分钟)的处理需求,优化模型的上下文窗口机制,支持长序列视频帧与文本查询的高效匹配,避免长视频信息丢失。
2. 基准数据集:VUE-STG与VUE-TR-V2的创新设计
为解决现有视频基准数据集“时长短、查询不贴近用户、标注精度低”的问题,Vidi2团队专门推出VUE-STG(时空定位基准)并升级VUE-TR-V2(时间检索基准),两大数据集的核心参数如下表所示:
表1:Vidi2配套基准数据集核心参数汇总
| 基准名称 | 任务类型 | 视频数量 | 查询数量 | 视频总时长 | 时长覆盖范围 | 核心特色 |
|---|---|---|---|---|---|---|
| VUE-STG | 时空定位(STG) | 982个 | 1600个 | 204.79小时 | 超短(<1min)-中(30min) | 人工高精度标注边界框;支持长上下文推理 |
| VUE-TR-V2 | 时间检索(TR) | 847个 | 1600个 | 310.72小时 | 超短(<1min)-超长(>60min) | 视频时长分布均衡;查询贴近用户实际使用场景 |
(1)VUE-STG的四大核心改进
相比现有时空定位数据集,VUE-STG的创新点的在于:
时长覆盖:支持10s-30min的长视频,满足长上下文推理评估;
查询格式:以名词短语为主,既简洁又保留句子级表达力,贴合用户实际查询习惯;
标注质量:所有时间范围和边界框均为人工标注,避免自动标注的误差;
评估指标:采用vIoU(视频交并比)/tIoU(时间交并比)/vIoU-Intersection组合方案,专门适配多片段时空定位场景的评估需求。
(2)VUE-TR-V2的升级亮点
作为初代VUE-TR基准的升级版本,VUE-TR-V2主要优化:
视频时长分布:新增“长视频(30-60min)”和“超长视频(>60min)”类别,解决原有数据集时长偏短的问题;
查询设计:增加更多“用户风格”查询,减少学术化表述,提升评估的实用性;
模态覆盖:支持视觉、音频、“视觉+音频”三种查询模态,适配更丰富的使用场景(如仅通过音频检索“包含雨声的片段”)。
3. 评估体系:精准衡量模型性能
Vidi2采用的评估指标兼顾“准确性”与“实用性”:
时空定位评估:vIoU(衡量视频片段与标注的重叠度)、tIoU(衡量时间范围的匹配度)、vIoU-Intersection(针对多片段场景的交叉评估);
时间检索评估:以检索准确率为核心,结合不同时长视频的检索效率,全面衡量模型在全时长范围内的表现;
视频QA评估:采用标准答案匹配度评分,确保模型回答的准确性与相关性。
应用场景
Vidi2的核心能力直接对应实际视频处理需求,可广泛应用于内容创作、媒体传播、教育、广告、企业办公等多个领域,以下是具体场景及应用方式:
1. 视频智能编辑工具集成
适用人群:短视频创作者、专业视频剪辑师、自媒体人;
应用方式:将Vidi2的时空定位能力集成到视频编辑软件(如剪映、Premiere)中,用户通过文本描述即可快速定位目标片段与物体——例如,剪辑电影混剪时,输入“主角在雨中奔跑的片段”,工具自动提取对应时间范围并框选主角,无需手动逐帧查找;
核心价值:将视频剪辑的“找片段”环节效率提升10倍以上,降低专业剪辑门槛,让非专业用户也能快速制作高精度视频。
2. 长视频内容检索与提取
适用人群:教育工作者、企业培训师、新闻编辑;
应用方式:针对长视频(如课程录像、会议回放、新闻直播),通过文本查询快速提取关键片段——例如,教育工作者输入“讲解牛顿第二定律的片段”,自动从1小时课程视频中提取对应5分钟内容;新闻编辑输入“包含政策解读的片段”,从2小时直播中精准截取目标内容;
核心价值:解决长视频“找信息难”的痛点,提升内容复用效率,降低二次创作成本。
3. 自动多视角切换与智能构图
适用人群:直播运营、赛事转播团队、Vlog创作者;
应用方式:基于Vidi2的时空定位能力,自动识别视频中的关键目标(如主播、运动员、演讲者),实现多视角自动切换——例如,赛事转播中,输入“聚焦1号运动员的进攻片段”,系统自动从多角度拍摄素材中选择最佳视角并切换;Vlog剪辑中,输入“突出主角的片段”,自动对视频进行构图优化,确保主角始终在画面中心;
核心价值:减少人工切换视角的工作量,提升直播/视频的观看体验,让内容更具专业性。
4. 视频内容审核与合规检查
适用人群:平台审核人员、企业合规专员;
应用方式:通过文本查询定位视频中的违规内容或敏感物体——例如,平台审核输入“包含烟草的片段”,自动检索视频中所有相关画面并标记时间戳与边界框;企业合规检查输入“展示竞品Logo的片段”,快速定位需要替换或打码的内容;
核心价值:将人工审核的“逐帧排查”转化为“精准定位”,提升审核效率,降低漏检风险。
5. 视频问答与智能交互
适用人群:教育平台、视频客服、智能终端开发者;
应用方式:在视频播放页面嵌入Vidi2的QA能力,用户可随时针对视频内容提问——例如,教育平台中,学生观看实验视频时提问“实验中使用的试剂是什么?”,系统自动给出答案;视频客服中,用户提问“如何操作该功能?”,系统定位视频中对应操作片段并解答;
核心价值:提升视频内容的交互性与实用性,让视频从“单向播放”变为“双向答疑”。
常见问题解答(FAQ)
1. Vidi2与初代Vidi模型有什么核心区别?
答:初代Vidi聚焦“视频理解与编辑”,核心能力是多模态时间检索;Vidi2在继承该能力的基础上,新增两大核心功能——细粒度时空定位(STG,支持时间戳+边界框输出)和视频问答(Video QA),同时推出VUE-STG基准数据集并升级VUE-TR-V2,性能全面超越初代模型及同类竞品。
2. Vidi2支持哪些格式的视频文件?
答:Vidi2基于FFmpeg实现视频解码,支持主流视频格式,包括MP4、AVI、MOV、MKV、FLV等。若遇到格式不支持的问题,建议通过FFmpeg将视频转换为MP4格式后再进行处理。
3. VUE-STG数据集的标注质量如何保障?
答:VUE-STG的所有时间范围和边界框均采用“人工标注+交叉校验”的方式生成,标注人员经过专业培训,确保每个标注结果的精准度;同时,数据集提供详细的标注规范与示例,避免标注歧义,为模型训练与评估提供可靠数据支撑。
4. Vidi2的处理速度如何?是否支持实时处理?
答:处理速度与硬件配置、视频时长、查询复杂度相关:在16GB GPU配置下,处理1分钟短视频的时空定位任务约需2-5秒,处理1小时长视频约需30-60秒;目前暂不支持实时流视频处理,主要面向离线视频编辑、内容检索等场景,后续开源版本可能优化速度性能。
5. 如何评估Vidi2在我的场景中的性能?
答:推荐两种评估方式:①使用官方提供的VUE-STG/VUE-TR-V2基准数据集,通过vIoU/tIoU等指标进行量化评估;②针对自定义场景,准备标注有时间戳、边界框或问答答案的测试集,使用模型的评估接口进行针对性测试,官方文档提供了评估脚本的使用指南。
6. 遇到模型推理错误或结果不准确怎么办?
答:首先检查视频格式、路径是否正确,以及硬件配置是否满足要求;若问题仍存在,可通过以下方式解决:①参考官方文档的“故障排查”章节;②在GitHub仓库的Issues板块提交问题(需附上视频样本、查询文本、错误日志);③加入官方社区(如Discord、Slack)寻求技术支持。
7. Vidi2支持多语言查询吗?
答:目前Vidi2的预训练模型主要支持英文和中文查询,其他语言的支持需通过额外的多语言微调实现(参考官方文档的微调指南)。
相关链接
Vidi2论文:
总结
Vidi2是字节跳动推出的开源大型多模态视频理解与生成模型,作为初代Vidi的升级版本,其核心价值在于通过细粒度时空定位、视频问答、全时长时间检索三大核心能力,打通了“文本描述→视频精准理解→智能编辑”的全链路,依托VUE-STG与VUE-TR-V2两大优化基准数据集,在关键任务上显著超越Gemini 3 Pro、GPT-5等闭源模型,且与同规模开源模型表现相当;该模型适配短视频剪辑、长视频检索、多视角切换、内容审核等多个实用场景,提供简洁易用的API接口与完整的开源工具链,既降低了专业视频处理的技术门槛,又为开发者提供了灵活的二次开发空间,是一款兼具“性能领先性”与“落地实用性”的视频AI工具,将有力推动视频创作与处理领域的智能化升级。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/vidi2.html





