WithAnyone:复旦 & 阶跃星辰联合开源的 AI 合照生成模型,一键实现自然多身份同框
一、WithAnyone是什么
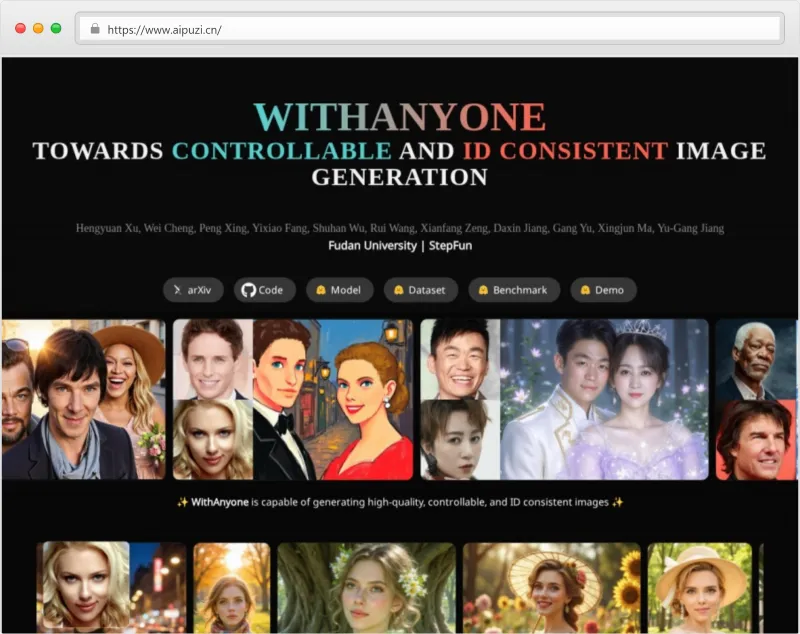
WithAnyone是由复旦大学与阶跃星辰联合开源的多身份AI合照生成项目,基于FLUX扩散模型架构构建,核心解决传统人像生成中的“复制粘贴”伪影问题。该项目通过大规模配对数据集MultiID-2M、创新对比身份损失函数及四阶段训练范式,实现了高保真度与强可控性的平衡——既保持人物身份特征的精准还原,又支持姿态、表情、场景的灵活定制。
简单来说,WithAnyone具备两大核心能力:一是“单人多态生成”,给定一张人物照片,可生成该人物不同角度、表情、姿态的图像;二是“多人同框生成”,上传1-4人的参考照片,配合文本提示词,就能生成毫无违和感的多人合照。与InstantID、PuLID等同类工具相比,它最大的突破在于打破了“身份相似度”与“生成多样性”的矛盾——既保证92.3%以上的面部细节还原度,又能让人物在合照中呈现自然的互动姿态,避免“克隆人式”的僵硬同框。
作为一个完整的开源项目,WithAnyone不仅提供模型代码与权重文件,还配套发布了两大核心资源:一是大规模多人配对数据集MultiID-2M,包含50万张标记多身份图片与150万张未标记图片,覆盖25000个独特身份;二是多身份生成评测基准MultiID-Bench,提供435个测试案例,标准化评估身份保真度与复制粘贴伪影程度。项目采用Apache 2.0开源许可证(模型与数据集遵循非商业学术研究许可),支持在线Demo体验、ComfyUI插件部署与本地代码运行,兼顾普通用户与开发者的使用需求。
二、功能特色
WithAnyone的核心优势集中在“身份保真”“自然度”“可控性”与“易用性”四大维度,具体功能特色如下:
1. 高保真身份还原,细节不丢失
面部特征还原度达92.3%,能精准复现人物的五官轮廓、肤色、发型甚至细微标记(如疤痕、痣),连少数民族的独特五官特征、传统头饰细节都能准确还原。
基于ArcFace人脸识别网络提取身份嵌入,通过对比学习强化身份辨识度,避免“千人一面”的生成效果,跨人种生成准确率较同类工具提升40%。
2. 无复制粘贴伪影,姿态自然多样
创新训练范式彻底解决传统模型的“复制粘贴”问题,生成人物的姿态、表情、视角不再局限于参考图,支持转头、耸肩、眯眼等自然动作,多人同框时互动关系合理,无拼贴感。
姿态多样性评分达0.81,支持1-4人同框生成,人物之间的空间位置、前后景关系自然,符合真实拍摄的透视与构图逻辑。
3. 精细化空间可控,位置灵活调整
支持通过BBOX(边界框)精确控制每个角色的位置、大小与远近关系,可设置x轴、y轴坐标及宽高参数,轻松实现人物前后景层次与错落布局。
文本提示词与空间定位双重控制,既能通过文字描述场景(如“海边日落时的家庭合照”),又能手动调整人物站位,满足个性化创作需求。
4. 低硬件门槛,多平台快速部署
硬件要求亲民,仅需RTX 3060显卡即可本地运行,1.2秒即可生成一张4K分辨率合照,老电脑也能流畅适配。
支持三种部署方式:无需代码的在线Demo、可视化操作的ComfyUI插件、开发者友好的本地代码部署,覆盖不同技术水平用户。
5. 配套资源丰富,支持学术与应用
开源完整生态:包含模型代码、预训练权重、数据集样例、评测基准与ComfyUI工作流,方便开发者二次开发与学术复现。
提供详细的技术文档与用户指南,包含训练流程、参数配置、常见问题解答,降低使用与研究门槛。
表1:WithAnyone与同类工具核心功能对比
| 功能特性 | WithAnyone | 传统模型(InstantID/PuLID) |
|---|---|---|
| 复制粘贴伪影抑制 | 显著抑制,自然姿态生成 | 严重,直接复制参考图表情/姿态 |
| 身份还原度 | 92.3%+,支持细微特征还原 | 85%左右,易丢失独特标记 |
| 空间可控性 | 支持BBOX精准定位人物位置 | 仅支持文本控制,无空间定位 |
| 跨人种适配能力 | 支持50个民族,准确率提升40% | 易出现“标准化”五官,适配性差 |
| 硬件门槛 | 最低RTX 3060,1.2秒出图 | 需RTX 3090以上,生成速度较慢 |
| 开源配套资源 | 含数据集、评测基准、插件 | 仅提供基础模型代码 |
三、技术细节
WithAnyone的技术创新体现在“数据构建-模型设计-训练范式-评测体系”全链条,核心技术细节如下:
1. 核心技术架构
基础模型:基于FLUX/DiT式扩散模型架构,采用双CLIP编码器(CLIP L/14与T5)处理文本提示词,兼顾语义理解与视觉特征对齐。
身份编码模块:采用“双通道编码”设计——通过ArcFace人脸识别网络提取身份判别向量(聚焦五官特征),通过通用图像编码器捕获中层视觉特征(如发型、肤色、配饰),且人脸嵌入仅作用于对应人物区域,避免跨身份信息泄露。
空间控制模块:引入BBOX定位机制,将人物位置信息转化为空间条件信号,与文本、图像特征融合输入采样器,实现人物位置与大小的精准控制。
2. 关键技术创新
(1)大规模配对数据集MultiID-2M
MultiID-2M是解决复制粘贴问题的核心数据基础,通过四阶段流水线构建:
单一ID参考库构建:从网络收集100万张单一身份图片,通过ArcFace嵌入聚类得到3000个身份(平均每个身份400张参考图),确保身份特征多样性。
团体照片检索:通过多姓名与场景感知查询,检索候选团体照片并检测面部区域。
身份匹配:将团体照片中的人脸嵌入与单一ID聚类中心进行余弦相似度匹配(阈值0.4),分配对应身份。
自动过滤与标注:通过审美评分、水印移除、LLM字幕生成等步骤,最终得到50万张标记多ID图片(含1-4人)与150万张未标记多ID图片,覆盖25000个独特身份,包含不同国籍、种族与场景。
(2)对比身份损失函数
为平衡“身份保真”与“生成多样性”,设计双重损失函数:
与真实值对齐的身份损失:使用真实图像(GT)的地标对生成图像进行对齐,避免噪声干扰,可在所有噪声水平下应用,不增加额外计算开销,同时隐式监督生成图像的地标准确性。
扩展负样本的对比损失:在面部嵌入空间中,将生成图像与同一身份的参考图“拉近”,与其他身份的负样本(从参考库中提取成千上万个)“推远”,强化模型对身份本质特征的学习,而非表面像素复制。
总损失函数:L = L_diffusion + 0.1×L_ID + 0.1×L_contrastive,其中L_diffusion为扩散模型基础损失,权重参数经大量实验优化确定。
(3)四阶段训练范式
逐步从“重建”过渡到“可控生成”,避免模型依赖复制粘贴捷径:
固定提示重建预训练(20k步):使用“两个人”等固定占位符提示词,优先让模型学习身份条件路径,不偏向文本风格,使用完整MultiID-2M数据集。
完整标题重建预训练(40k步):引入真实文本提示词,将身份学习与文本条件生成对齐,此时模型身份相似性达到峰值。
配对调优:50%训练样本替换为MultiID-2M中的配对数据(参考图与目标图为同一身份的不同图像),打破直接复制的捷径,促使模型学习身份不变特征。
高质量子集微调:在精选的高质量图像子集上微调,提升生成图像的美学质量与细节还原度。
(4)MultiID-Bench评测基准
首个针对多身份生成的标准化评测体系,解决传统评测“偏向复制粘贴”的问题:
测试集设计:包含435个测试案例,每个案例含1-4人的真实图像(GT)、对应参考图与文本提示,测试身份为训练数据外的稀有、长尾身份,确保评测公正性。
核心指标:
身份保真度(S_GT):生成图像与真实身份的面部嵌入相似度,避免仅依赖参考图相似度(S_ref)导致的复制粘贴偏向。
复制粘贴指标(Copy-Paste Score):通过角距离计算生成图像相对于参考图与真实值的偏向,得分0表示完全符合真实场景,得分1表示完全复制参考图。
辅助指标:身份混合率、提示保真度(CLIP I/T)、美学评分。
表2:WithAnyone训练流程与核心目标
| 训练阶段 | 训练步数 | 核心数据 | 训练目标 |
|---|---|---|---|
| 固定提示重建预训练 | 20k | MultiID-2M全量数据 | 初始化骨干网络,学习身份条件路径 |
| 完整标题重建预训练 | 40k | MultiID-2M全量数据+文本提示 | 对齐身份学习与文本条件生成 |
| 配对调优 | 30k | 50%配对数据+50%普通数据 | 抑制复制粘贴,强化身份不变特征 |
| 高质量子集微调 | 10k | 精选高质量图像子集 | 提升生成图像美学质量与细节还原度 |
四、应用场景
WithAnyone凭借高保真、自然化、强可控的核心优势,已在多个场景落地应用,覆盖个人、商业与学术领域:
1. 个人生活场景:弥补遗憾,定格团圆
老照片修复与合成:将长辈的旧照片(如结婚照、单人照)与现代家庭照片合成,还原跨时空的家庭合照,修复被损坏、缺失人物的老照片,保留历史记忆。
异地家人同框:为天各一方的家人生成自然合照,如在外工作的子女与老家的父母同框、已故亲人与晚辈“合影”,弥补团圆遗憾。
个性化纪念照制作:生成与偶像、历史人物的“合照”(非商用目的),或定制特殊场景合照(如毕业照、旅行照),满足个性化表达需求。
2. 商业摄影场景:降本增效,创新服务
影楼AI合照套餐:连锁影楼可推出“AI全家福”“AI毕业照”服务,支持15人以上同框4K生成,无需全员到场拍摄,降低场地与时间成本,价格仅为传统写真的1/3。
广告内容创作:快速生成多模特同框的广告图,支持调整模特姿态、场景风格,适配服装、美妆等行业的营销素材需求,缩短创作周期。
证件照合成:生成多人证件照(如结婚证、团队证件照),确保人物姿态自然、身份特征准确,无需反复拍摄调整。
3. 影视与内容创作场景:灵活定制,突破限制
影视替身合成:在影视拍摄中,为演员生成不同姿态、场景的图像,用于替身镜头、后期合成,减少实景拍摄的风险与成本。
虚拟角色互动:为虚拟主播、游戏角色生成多角色同框画面,支持自定义表情、动作与场景,丰富内容表现形式。
短视频素材制作:短视频创作者可快速生成多人互动素材,如剧情类视频的角色同框、美食测评的多人试吃场景,提升创作效率。
4. 学术研究场景:提供基准,推动创新
多身份生成研究:为身份一致性生成、复制粘贴抑制、跨人种适配等研究提供标准化数据集(MultiID-2M)、评测基准(MultiID-Bench)与基线模型。
扩散模型优化:其对比身份损失函数、四阶段训练范式可为其他扩散模型的可控生成任务提供参考,推动相关技术的迭代升级。
伦理AI研究:项目内置的名人过滤、隐私保护机制,为AI生成的伦理规范研究提供实践案例。
五、使用方法
WithAnyone提供三种使用方式,从无需代码的在线体验到开发者定制化部署,满足不同用户需求:
1. 在线Demo体验(零门槛,推荐普通用户)
访问链接:https://huggingface.co/spaces/WithAnyone/WithAnyone_Demo。
操作步骤:
上传参考图片:点击“Upload Reference Images”,分别上传1-4人的参考照片(每张照片仅含一个人物,正面、清晰为佳)。
输入文本提示:在“Prompt”框中描述生成场景,如“three people taking a walk in the park at sunset, natural lighting, high resolution”。
调整参数(可选):设置生成图像尺寸(默认1024×1024)、采样步数(默认20步)、种子值(固定种子可重复生成结果)。
点击“Generate”:等待1-2秒,即可生成结果,支持下载图像或重新生成。
2. ComfyUI插件部署(可视化操作,推荐设计类用户)
前置条件:已安装ComfyUI,显卡支持CUDA(最低RTX 3060)。
安装步骤:
加载双CLIP编码器(FLUX标准配置)。
添加WithAnyone模型加载器,关联已下载的主模型、FLUX模型与SigLIP模型。
添加角色定位节点,通过BBOX设置人物x/y坐标、宽高参数(如P1:x=0.15,y=0.3,宽=0.4,高=0.5)。
连接采样器与解码器,输入提示词后点击“Queue Prompt”生成图像。
主模型:下载WithAnyone模型权重,放入“ComfyUI/models/diffusion_models”目录。
SigLIP模型:下载siglip-base-patch16-256-i18n,放入“ComfyUI/models/diffusers”目录。
FLUX基础模型:确保已安装FLUX Dev模型(需单独下载)。
下载插件:访问GitHub仓库(https://github.com/okdalto/ComfyUI-WithAnyone),下载插件压缩包。
部署插件:将解压后的文件夹复制到ComfyUI的“custom_nodes”目录下,重启ComfyUI。
下载模型文件:
加载工作流:在ComfyUI中导入项目提供的工作流文件(.json格式),或手动搭建节点:
3. 本地代码部署(开发者友好,支持二次开发)
前置条件:Python 3.10+,PyTorch 2.0+,CUDA 11.8+,最低RTX 3060(8GB显存)。
部署步骤:
运行
download_models.py脚本自动下载所需模型(包括FLUX基础模型、WithAnyone权重、SigLIP模型),或手动下载后放入指定目录(参考README说明)。克隆代码仓库:
git clone https://github.com/Doby-Xu/WithAnyone.git cd WithAnyone
安装依赖:
pip install -r requirements.txt
下载模型文件:
运行示例代码:
from withanyone import WithAnyoneGenerator # 初始化生成器 generator = WithAnyoneGenerator(device="cuda") # 准备输入(参考图路径列表、提示词、BBOX参数) reference_paths = ["person1.jpg", "person2.jpg"] prompt = "two people sitting on a bench, smiling, outdoor scene" bboxes = [ (0.2, 0.3, 0.4, 0.5), # (x, y, width, height) for person 1 (0.5, 0.35, 0.35, 0.45) # (x, y, width, height) for person 2 ] # 生成图像 output_image = generator.generate( reference_paths=reference_paths, prompt=prompt, bboxes=bboxes, num_inference_steps=20, guidance_scale=3.0 ) # 保存结果 output_image.save("output.jpg")二次开发:可修改
config.py调整模型参数,或基于modeling_withanyone.py扩展功能(如增加多人支持、优化生成速度)。

六、常见问题解答(FAQ)
1. WithAnyone最多支持多少人同框生成?
目前官方版本支持1-4人同框生成,超过4人可能导致身份混淆或生成质量下降。若需生成更多人合照,可分批次生成后通过图像编辑工具合成,或等待后续版本更新。
2. 生成图像的身份相似度不够高怎么办?
优化参考图:选择正面、清晰、无遮挡的人物照片,避免侧脸、模糊或佩戴厚重配饰的图像。
增加参考图数量:若单张参考图效果不佳,可在代码部署模式下传入多张同一人物的参考图,提升身份特征提取准确性。
调整参数:提高
guidance_scale(建议3.0-5.0),增强身份条件的权重。
3. 硬件不支持CUDA,能使用WithAnyone吗?
目前项目仅支持CUDA加速的NVIDIA显卡,暂不支持AMD显卡或CPU推理。若暂无合适硬件,推荐使用Hugging Face在线Demo,无需本地硬件资源即可体验。
4. 生成的图像中人物有“六指”“五官扭曲”等问题怎么办?
增加采样步数:将采样步数调整至25-30步,提升生成稳定性。
优化提示词:加入“natural hands, normal facial features”等描述,引导模型生成正常形态。
更换种子值:不同种子值的生成结果差异较大,可多次尝试不同种子。
5. WithAnyone的生成结果可以用于商业用途吗?
根据项目许可证协议:代码遵循Apache 2.0许可证,可商用;但模型权重与数据集遵循FLUX 1.0(Dev)非商业学术研究许可证,禁止商业使用(包括广告、营销、产品落地等)。若需商用,需联系团队获取商业授权。
6. 上传的参考图会被服务器存储吗?
在线Demo:参考图仅用于临时生成,生成完成后数据会自动删除,服务器不会存储用户隐私图像。
本地部署:所有数据均在本地处理,无数据上传行为,隐私保护更有保障。
7. 为什么生成的合照中人物互动不自然?
优化提示词:明确描述人物互动关系,如“two people hugging each other, natural posture”。
调整BBOX参数:合理设置人物位置,避免重叠或距离过远,可通过BBOX调整人物前后景关系,增强空间层次感。
8. 支持生成全身像或特定风格的合照吗?
支持全身像生成,但需在提示词中明确说明(如“full body shot”),且参考图最好包含人物上半身或全身,便于模型学习身形特征。同时支持风格定制,可在提示词中加入“oil painting style”“anime style”等描述,生成不同风格的合照。
七、相关链接
GitHub代码仓库:https://github.com/Doby-Xu/WithAnyone
在线Demo:https://huggingface.co/spaces/WithAnyone/WithAnyone_demo
ComfyUI插件仓库:https://github.com/okdalto/ComfyUI-WithAnyone
八、总结
WithAnyone作为复旦大学与阶跃星辰联合开源的多身份AI合照生成项目,通过创新的技术方案解决了传统模型的“复制粘贴”痛点,构建了“数据-模型-评测”三位一体的完整生态。它基于FLUX扩散模型架构,依托大规模配对数据集MultiID-2M与对比身份损失函数,实现了身份保真度与生成自然度的平衡,支持1-4人同框生成与精细化空间控制,硬件门槛低至RTX 3060,提供在线Demo、ComfyUI插件与本地代码三种使用方式,覆盖个人、商业与学术多类场景。项目不仅开源了完整的代码与模型,还发布了MultiID-Bench评测基准,为多身份生成领域提供了标准化解决方案,既满足普通用户的合照创作需求,又为开发者与研究者提供了高质量的技术底座,推动了AI生成技术在身份定制场景的实用化与规范化发展。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/withanyone.html





