通俗易懂讲CV:让AI看照片也能理解内容的技术揭秘
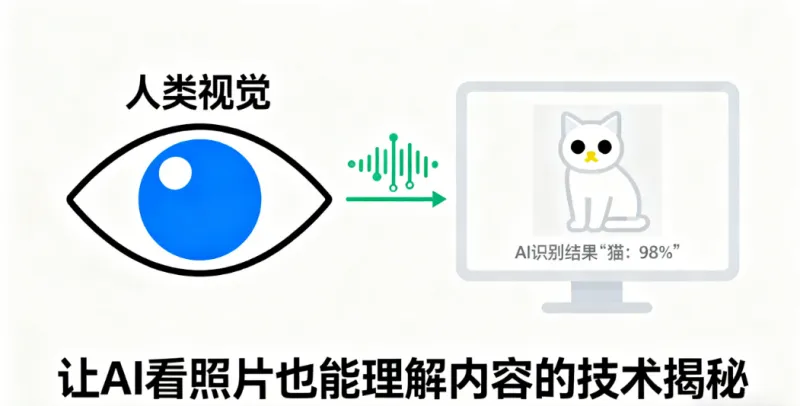
打开手机拍照,屏幕上自动框出人脸并标注“人像模式”;刷脸支付时,摄像头扫一眼就确认“是本人”;自动驾驶汽车能避开行人、识别红绿灯……这些我们习以为常的功能,背后都藏着同一种核心技术——计算机视觉(Computer Vision,简称CV)。
很多人会好奇:AI没有眼睛,怎么“看”懂照片里的内容?其实,CV的本质不是让机器“看见”,而是让机器“理解”——把图像转化成计算机能处理的数字,再通过算法提取关键信息,最终判断出“这是什么、在哪里、在做什么”。接下来,我们就一步步拆解这项技术,用最通俗的语言揭开AI“看懂世界”的秘密。
一、先搞懂:CV到底要解决什么问题?
在讲技术前,我们得先明确CV的核心目标——模拟人类视觉系统,让计算机能从图像/视频中获取和人类一样的信息。比如我们看一张“猫坐在沙发上”的照片,能瞬间知道“主体是猫”“背景是沙发”“猫的动作是坐着”;CV要做的,就是让计算机也能得出同样的结论。
不过,计算机的“看”和人类的“看”差别很大。我们可以用一张表格直观对比两者的核心差异:
| 对比维度 | 人类视觉(我们的眼睛+大脑) | AI视觉(CV技术) |
|---|---|---|
| 信息输入 | 眼睛接收光线,转化为神经信号 | 摄像头/传感器接收图像,转化为像素数字矩阵 |
| 处理方式 | 大脑自动整合“形状、颜色、纹理”,凭经验判断 | 算法分步处理:先“清理”图像,再提取特征,最后匹配识别 |
| 学习过程 | 小时候看一次猫,就记住“有毛、尖耳朵、会叫” | 需要数万张带标签的猫照片,反复训练调整参数 |
| 容错能力 | 即使猫被挡住一半,也能认出是猫 | 遮挡超过30%,就可能误判为“狗”或“毛绒玩具” |
简单来说:人类看东西是“整体感知+经验判断”,AI看东西是“数字拆解+数据匹配”。CV技术的所有突破,本质都是让“数字拆解”的过程更接近人类的“整体感知”。
二、第一步:AI怎么把“照片”变成“数字”?
我们看到的照片是彩色的图像,但计算机只认识0和1——所以CV的第一步,必须把“图像”转化为“数字”,这个过程叫图像数字化。
1. 像素:AI世界里的“最小视觉单位”
你把手机照片放大到极限,会看到无数个小方格——这就是像素(Pixel),也是AI能识别的最小“视觉单元”。一张1920×1080的照片,意思是“横向有1920个像素,纵向有1080个像素”,总像素数超过200万(1920×1080≈207万)。
每个像素的核心信息是“颜色”,而颜色会被转化为数字。我们最熟悉的颜色标准是RGB模型:任何颜色都可以由“红色(Red)、绿色(Green)、蓝色(Blue)”三种基础色混合而成,每种颜色的强度用0-255的数字表示(0是最暗,255是最亮)。
比如:
纯红色像素:数字是(255, 0, 0)(红色满格,绿、蓝为0)
纯白色像素:数字是(255, 255, 255)(三种颜色都满格)
纯黑色像素:数字是(0, 0, 0)(三种颜色都为0)
一张彩色照片,最终会变成一个“三维数字矩阵”:比如1920×1080的照片,就是“1920列×1080行×3个颜色通道”的数字集合——这就是AI“看到”的原始数据。
2. 预处理:给图像“做清洁”,方便后续识别
原始的数字矩阵里,往往藏着“干扰信息”:比如拍照时手抖导致图像模糊、光线太暗让像素颜色失真、照片边缘有杂点(噪声)……这些问题会让AI“看走眼”,所以必须先做图像预处理——就像我们看书前,先擦干净眼镜一样。
常见的预处理步骤有3个,我们用表格说清楚:
| 预处理步骤 | 核心作用 | 通俗理解(类比生活场景) |
|---|---|---|
| 去噪(Noise Reduction) | 去除图像中的“杂点”,让画面更干净 | 给照片做“磨皮”,去掉脸上的小痘痘 |
| 亮度/对比度调整 | 平衡图像明暗,让细节更清晰 | 把暗部的文字调亮,让看不清的内容变清楚 |
| 图像缩放(Resize) | 把不同尺寸的图像统一成固定大小 | 把A4纸、B5纸的文件,都复印成同样大小的纸 |
举个例子:如果我们要让AI识别身份证上的文字,原始照片可能因为光线暗,文字模糊且有杂点。经过预处理后,文字会变清晰、背景变干净——AI后续“读”文字时,准确率会从60%提升到95%以上。

三、核心突破:AI怎么“提取特征”,认出照片里的东西?
把图像变成干净的数字矩阵后,最关键的一步来了:AI怎么从这些数字里,找出“能代表物体的特征”?比如看到“尖耳朵、圆眼睛、有尾巴”,就知道是猫。
这一步的技术演进,分“传统CV”和“深度学习CV”两个阶段——后者的出现,才真正让AI“看懂”世界成为可能。
1. 传统CV:靠“人工设计”找特征,缺点很明显
在2012年之前,CV主要用“传统方法”——工程师先想好“识别某个物体需要什么特征”,再写算法去提取这些特征。比如要识别“杯子”,工程师会定义“特征”:有圆柱形轮廓、顶部是圆形开口、底部是平的。
常见的传统方法有两种:
边缘检测:用算法找出图像中“颜色变化剧烈的线条”(比如杯子的轮廓线),再根据线条形状判断物体。比如用“Canny边缘检测算法”,能把杯子的轮廓完整画出来。
特征点检测:找图像中“特别的点”(比如杯子的把手角、瓶口边缘),再通过这些点的位置关系判断物体。比如“SSIFT算法”,能在不同角度的杯子照片中,找到相同的特征点。
但传统CV的问题很突出:太依赖人工设计,对环境变化太敏感。比如:
杯子换个角度(从正面变成侧面),轮廓和特征点位置变了,AI就认不出来;
杯子上有花纹,边缘检测会把花纹当成轮廓,导致误判;
光线变暗,特征点的颜色信息变了,AI也会“认错”。
举个真实案例:2010年,某公司用传统CV做“苹果识别”,在实验室里(固定光线、固定角度)准确率能到90%,但拿到果园里(光线变化、苹果有遮挡),准确率直接跌到30%——根本没法用。
2. 深度学习CV:让AI自己“学”特征,效率翻倍
2012年,一场名为“ImageNet图像分类比赛”改变了CV的发展方向——来自多伦多大学的团队用“卷积神经网络(CNN)”模型,把图像分类准确率从传统方法的70%提升到84%,远超所有人预期。
从此,深度学习(尤其是CNN)成为CV的核心技术——它的最大优势是:不用工程师人工设计特征,AI能自己从海量数据中“学”出“什么特征代表什么物体”。
我们用“识别猫”来通俗解释CNN的工作过程——它就像“人类看东西的逻辑”:先看局部,再拼整体。
(1)CNN的核心结构:三层“过滤器”,逐步提取特征
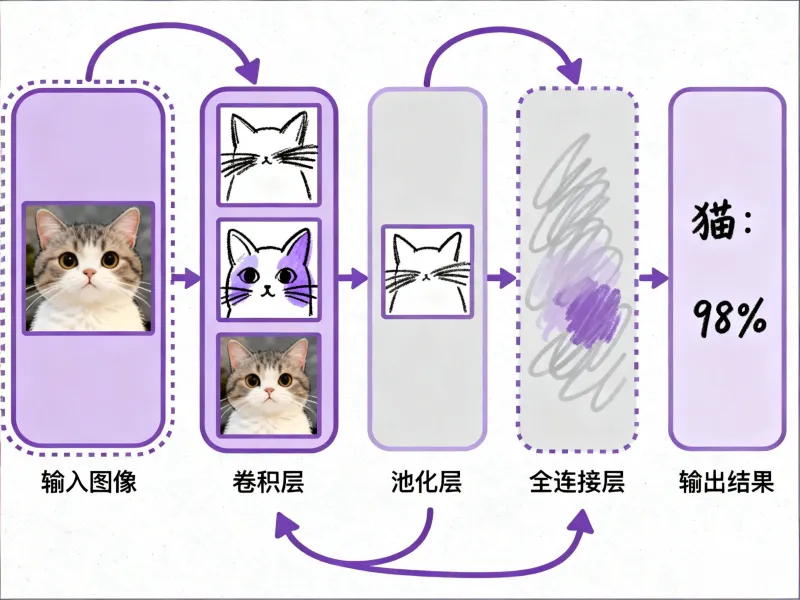
CNN的结构就像一条“流水线”,从输入图像到输出识别结果,要经过三个关键层:
卷积层(Convolutional Layer):提取“局部小特征”
卷积层就像“放大镜”,每次只看图像的一小部分(比如3×3的像素块),然后用“卷积核”(一个小数字矩阵)去“扫”整个图像,找出“边缘、纹理、颜色块”这些基础特征。
比如识别猫时,第一层卷积层会先找出“猫的胡须边缘、耳朵的尖线条、眼睛的圆形色块”——这些都是“局部小特征”,还看不出是猫。池化层(Pooling Layer):压缩信息,保留关键
卷积层提取的特征图往往很大(比如200×200像素),计算量太大。池化层的作用是“压缩”——比如用“最大池化”,把2×2的像素块里最大的数字留下,其他删掉,让特征图尺寸减半(从200×200变成100×100)。
这一步就像“总结重点”:比如猫的耳朵有很多线条,池化后只保留“最关键的尖线条”,去掉冗余信息,让AI更专注于核心特征。全连接层(Fully Connected Layer):拼合特征,判断结果
经过好几轮“卷积+池化”后,AI已经提取到了“猫的耳朵形状、眼睛位置、尾巴长度”这些中层特征。全连接层会把这些特征“拼起来”,和自己“学过的猫的特征库”对比——如果匹配度高,就输出“这是猫”,并给出置信度(比如98%)。
(2)CNN为什么能“学会”特征?靠“训练”和“数据”
AI不是天生就知道“尖耳朵是猫的特征”——它需要通过“训练”来学习,而训练的核心是“海量带标签的数据”。
举个例子:要让AI学会认猫,需要做三件事:
准备10万张带标签的猫照片:每张照片都标注“这是猫”,还要标注猫的位置(比如“猫在图像左上角”);
让AI反复“刷题”:把照片输入CNN,AI先自己预测“这是什么”,如果预测错了(比如把猫认成狗),算法会自动调整CNN的参数(比如卷积核的数字),直到下次预测更准;
验证效果:用1万张AI没见过的猫照片做“测试”,如果准确率达到95%以上,说明AI“学会认猫了”。
这里有个关键:数据越多、标签越准,AI学得越好。比如ImageNet数据集,包含1400万张照片,分2万多个类别(从猫、狗到飞机、椅子)——正是因为有这样的“大数据库”,CNN才能学会识别各种物体。
四、CV的三大核心能力:AI能“做什么”?
学会“提取特征”后,AI就能实现三大核心能力——这些能力也是我们日常生活中CV应用的基础。
1. 图像分类:判断“这是什么”
图像分类是CV最基础的能力——给定一张照片,AI判断“这是猫/狗/汽车/风景”,本质是“给图像贴标签”。
比如:
手机相册的“智能分类”:自动把照片分成“人物”“动物”“美食”;
图片搜索:在百度图片搜“向日葵”,AI会找出所有向日葵的照片;
垃圾识别:垃圾分类APP,拍一张垃圾照片,AI判断“这是可回收物/厨余垃圾”。
图像分类的“标杆模型”是AlexNet(2012年),它第一次证明了CNN在分类任务上的优势。后来的ResNet、Inception等模型,把分类准确率进一步提升到98%以上——现在AI认常见物体,已经比人类更准(人类认1000类物体的准确率约95%)。
2. 目标检测:找出“东西在哪里”
图像分类只能判断“有没有某样东西”,但目标检测能做到“找出东西的位置”——用方框(Bounding Box)标出物体,同时说明“这是什么”。
比如:
手机拍照的“人像模式”:检测出人脸的位置,对背景进行虚化;
监控摄像头的“人流统计”:检测出每个行人的位置,统计人数;
自动驾驶的“障碍物识别”:检测出前方的行人、汽车、红绿灯,标出它们的距离。
常用的目标检测算法有两种,各有优势:
| 算法名称 | 核心特点 | 优势场景 | 例子 |
|---|---|---|---|
| YOLO(You Only Look Once) | 一次扫描图像就能完成检测,速度快(每秒30帧以上) | 实时场景,需要快速响应 | 监控摄像头实时识别人车、手机实时美颜 |
| Faster R-CNN | 分两步检测(先找可能的区域,再判断类别),准确率高 | 对精度要求高的场景 | 医学影像检测病灶、卫星图像识别建筑 |
举个直观的例子:用YOLO算法处理一张街景照,0.03秒就能标出“3个行人(在中间和右侧)、2辆汽车(在左侧)、1个红绿灯(在上方)”,每个方框旁边都有类别和置信度(比如“行人:99%”)。
3. 图像分割:把照片“拆成块”
如果说目标检测是“用方框框出物体”,图像分割就是“把物体的每一个像素都标出来”——相当于把照片分成“天空、道路、行人、汽车”等不同区域,每个区域都有明确的类别标签。
图像分割主要分两种:
语义分割(Semantic Segmentation):只分“类别”,不分“个体”。比如一张有3个行人的照片,所有行人的像素都标为“行人”,不区分“行人A、行人B”;
实例分割(Instance Segmentation):既分“类别”,又分“个体”。比如3个行人的像素会分别标为“行人1、行人2、行人3”。
图像分割的典型应用是自动驾驶:AI需要知道“哪部分像素是道路”“哪部分是行人”“哪部分是绿化带”——只有这样,才能判断“该走哪条路,该避开谁”。比如特斯拉的Autopilot系统,就是用分割技术处理摄像头图像,实时生成“道路语义地图”。
五、CV的真实应用:从手机到医院,无处不在
看完技术原理,我们再看看CV在日常生活中的具体应用——这些场景你可能每天都在接触,但未必知道背后是CV在工作。
1. 刷脸支付:AI怎么“认人”?
刷脸支付的核心是“人脸识别”,属于CV的“目标检测+特征匹配”组合:
第一步:活体检测:防止用照片、视频欺骗AI。比如让你“眨一下眼睛”“点头”——AI会检测面部肌肉的运动,判断是不是真人;
第二步:人脸特征提取:找出脸上的68个关键特征点(比如眼角、鼻尖、嘴角的位置),把这些点的坐标转化为“人脸特征码”(一串数字,比如128位);
第三步:特征匹配:把你的“人脸特征码”和数据库里的特征码对比,如果相似度超过90%,就判断“是本人”,允许支付。
现在的人脸识别准确率非常高——在光线好的情况下,错误率低于0.001%,比人类认脸还准。但它也有缺点:比如化妆太浓、戴口罩,会遮挡特征点,导致识别失败。
2. 医学影像诊断:AI当“医生的眼睛”
在医院里,CV已经成为医生的“好帮手”——尤其是在医学影像(X光、CT、MRI)诊断上,AI能找出医生可能忽略的微小病灶。
比如肺癌筛查:
传统方式:医生看CT片,在几百张断层图像中找“肺部结节”(早期肺癌的信号),容易漏诊(尤其是直径小于5毫米的小结节);
CV辅助诊断:AI能自动扫描所有CT图像,用分割技术标出结节的位置、大小、形状,还能判断“良性还是恶性”——准确率能达到90%以上,比人工筛查快3倍。
目前,CV在医学影像上的应用已经覆盖肺癌、乳腺癌、糖尿病视网膜病变等多种疾病。但要注意:AI只是辅助工具,最终的诊断结果还是由医生决定——AI给出的“判断”,需要医生验证后才能用。
3. 手机拍照:AI让照片更好看
我们手机拍照的很多功能,背后都是CV在工作:
HDR模式:AI同时拍3张不同曝光的照片(欠曝、正常、过曝),然后用图像融合技术,把亮部、暗部的细节拼合成一张——比如拍逆光人像,能让人脸不黑、背景不过曝;
美颜功能:AI先检测人脸的轮廓、眼睛、嘴巴位置,再针对性调整:比如“磨皮”(平滑皮肤像素)、“瘦脸”(调整脸部轮廓的像素位置)、“大眼”(放大眼睛区域的像素);
文字识别(OCR):拍一张身份证、名片,AI能提取上面的文字(姓名、电话、地址)——比如微信的“扫一扫翻译”,就是用OCR识别图片里的英文,再翻译成中文。
4. 自动驾驶:AI的“视觉大脑”
自动驾驶汽车的“眼睛”是摄像头,而“视觉大脑”就是CV技术——没有CV,汽车就“看不见”路况。
自动驾驶中的CV主要做三件事:
识别交通元素:检测红绿灯(红/黄/绿)、车道线(实线/虚线)、交通标志(限速60、禁止左转);
判断障碍物:识别行人、自行车、其他汽车,还要判断它们的运动方向(比如“行人正在过马路”“汽车正在超车”);
规划行驶路线:根据分割后的“道路区域”,规划出“该走哪条车道,该保持多少距离”。
不过,自动驾驶中的CV不能单独工作——它需要和雷达(检测距离)、激光雷达(高精度定位)配合,才能应对复杂路况(比如雨天、夜晚)。比如在暴雨天,摄像头看不清车道线,雷达就能补全信息,让汽车不会偏离车道。

六、CV的“短板”:AI还会“看走眼”
虽然CV技术已经很成熟,但它还不是“万能的”——在很多场景下,AI会“看走眼”,这也是目前CV面临的主要挑战。
我们用表格总结CV的四大核心挑战:
| 挑战类型 | 具体表现 | 例子 |
|---|---|---|
| 环境敏感性 | 光线、天气、角度变化,会导致识别准确率下降 | 雨天摄像头模糊,AI把路灯认成红绿灯;猫换个姿势,AI认成狗 |
| 小目标识别难 | 图像中尺寸小的物体,AI容易漏检 | 监控画面中远处的行人,AI看不见;CT片中直径小于3毫米的结节,AI漏诊 |
| 遮挡问题 | 物体被遮挡超过30%,AI容易误判 | 人戴口罩,AI认不出;杯子被书本挡住一半,AI认成盒子 |
| 数据偏见 | 训练数据中某类样本太少,AI对这类物体识别差 | 训练数据中大多是白种人的照片,AI认黑种人容易出错;大多是晴天的照片,AI在雨天识别差 |
这些挑战本质上是因为:AI的“理解”是基于“数据匹配”,而不是像人类一样有“常识”。比如人类知道“猫即使被挡住,也有四条腿、有尾巴”,但AI只看“有没有见过类似的遮挡照片”——如果训练数据中没有,就会认错。
七、总结:CV不是“魔法”,而是“数字拆解+数据学习”
看到这里,你应该明白:AI“看懂”照片,不是因为它有“意识”,而是因为CV技术把“看”的过程拆解成了三步:
把图像变成数字(像素矩阵);
用CNN提取特征(从局部到整体);
用训练好的模型匹配识别(对比已知数据)。
CV的本质是“模拟人类视觉的技术”——它虽然没有人类的“常识”,但在“重复识别、快速处理、微小特征检测”上,已经远超人类。从刷脸支付到医学诊断,从手机拍照到自动驾驶,CV正在悄悄改变我们的生活。
最后要强调:CV不是“魔法”,它的每一步都基于数学(线性代数、概率统计)和计算机科学(算法、编程)——正是这些基础学科的进步,才让AI“看懂”世界成为可能。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-tutorial/simple-understand-cv-technical-secrets.html





