AgentEvolver:阿里通义开源的AI智能体自主进化框架,赋能自主任务生成与高效策略优化
一、AgentEvolver是什么
AgentEvolver是阿里巴巴通义实验室主导开发、并在ModelScope社区开源的端到端智能体自进化框架。它的核心目标是让AI智能体摆脱对人工标注数据、手动任务设计和外部奖励函数的依赖,通过内置的三大协同机制实现“自主探索环境、自主生成任务、自主总结经验、自主优化策略”的全流程进化能力。
简单来说,传统AI智能体训练需要人类像“教练”一样全程指导——手动设计训练任务、标注数据、评估结果,而AgentEvolver相当于给智能体赋予了“自我成长”的能力,让它能像人类一样“主动发现问题、从经验中学习、不断改进自己”。
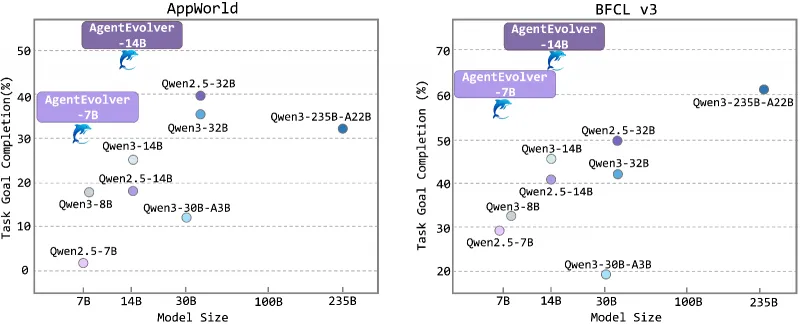
在性能表现上,AgentEvolver展现出惊人的突破:在AppWorld和BFCL v3等长程复杂任务基准测试中,14B参数量模型的任务平均完成率(avg@8)从基线的29.8%飙升至57.6%,最佳尝试(best@8)更是达到76.7%;7B参数量模型的平均完成率从15.8%跃升至45.2%,性能直接超越未优化的14B基线模型,实现了“小模型越级挑战大模型”的效果。同时,它的学习效率极高,达到基线模型90%性能时,在AppWorld任务中所需训练步数减少55.6%,BFCL任务中减少66.7%,大幅降低了训练的时间成本和算力消耗。
作为开源项目,AgentEvolver基于Python开发,采用模块化、服务化解耦设计,支持与多种LLM模型、外部环境和工具API无缝对接,开发者可轻松进行二次开发和场景适配,目前已在GitHub和ModelScope平台开放完整源码和技术文档。
二、功能特色
AgentEvolver的核心优势集中在“自主进化”和“高效实用”两大维度,具体包含以下五大功能特色:
1. 全流程自动化,告别人工依赖
传统强化学习训练需要投入大量人力进行任务设计、数据标注和奖励函数调试,而AgentEvolver通过三大核心机制构建了“环境→任务→轨迹→策略”的自动化闭环。从环境探索、任务生成,到经验复用、策略优化,全程无需人工干预,彻底解决了“人工成本高、场景适配慢”的行业痛点。
2. 高参数效率,小模型也能有强性能
AgentEvolver不依赖模型参数量的堆砌,而是通过优化训练流程提升核心能力。实验证明,搭载该框架的7B模型任务成功率(45.2%)显著超越未优化的14B基线模型(29.8%),14B模型经过优化后性能更是媲美32B级别的大模型,极大降低了对硬件算力的要求。
3. 跨域泛化能力强,适配多场景迁移
仅通过单一环境(如AppWorld)训练的智能体,在迁移到全新的BFCL任务环境时,性能衰减微乎其微。这一特性源于其三大机制的协同作用:自我提问生成多样化任务、自我导航复用通用经验、自我归因提炼核心逻辑,让智能体掌握的是“通用能力”而非“特定场景记忆”。
4. 模块化可扩展,灵活适配定制需求
框架采用服务导向的数据流架构,核心组件(Env Service、Context Manager、训练管线等)完全解耦。开发者可根据需求自定义环境适配、扩展上下文管理模板、替换优化算法,支持从简单任务到复杂长程任务的全场景部署,兼容OpenAI Gym、Ray等主流工具生态。
5. 高样本效率,训练成本大幅降低
针对传统RL“奖励稀疏、样本浪费”的问题,自我归因机制将粗粒度的最终奖励转化为细粒度的过程反馈,让每一步交互都能产生有效学习信号。同时,自我导航机制减少无效试错,使AgentEvolver在样本利用率上实现质的提升,相同性能目标下可节省50%以上的训练步数。

三、技术细节
AgentEvolver的技术创新集中在“三大核心机制”和“模块化架构”两方面,共同支撑起智能体的自主进化能力:
3.1 三大核心自进化机制
三大机制形成闭环协同,分别解决“任务从哪来”“探索怎么高效”“学习怎么精准”的核心问题:
(1)自我提问(Self-Questioning):自主生成训练任务
核心目标是解决“人工任务构建成本高”的痛点,让智能体自己“找题练”,流程分为三步:
环境探索:基于环境配置文件(如API文档、场景规则),采用“广度优先+深度优先”策略,通过高随机性LLM生成多样化交互轨迹,全面覆盖环境功能边界;
任务合成:LLM分析探索轨迹,结合用户偏好(难度、风格等),逆向生成具体任务及对应的“参考解法”,比如从“API调用轨迹”中提炼“批量提取数据并生成报表”的任务;
任务筛选:通过语义去重过滤冗余任务,再通过真实环境回放参考解法,剔除不可执行的“幻觉任务”,最终形成高质量训练集。
(2)自我导航(Self-Navigating):经验复用提升探索效率
核心目标是解决“随机探索低效”的痛点,让智能体“借鉴过往经验”,流程分为三步:
经验获取:从历史成败轨迹中提炼结构化自然语言经验(包含“适用场景+最优策略”),并向量化存储到“经验池”,形成可检索的知识库;
经验混合探索:采用“经验引导探索+无引导探索”的混合策略(默认比例1:1),新任务执行时先检索相关经验辅助决策,同时保留部分随机探索以保证多样性;
经验内化:训练时剥离提示中的经验文本,避免模型“死记硬背”,并对成功经验引导的优质轨迹给予更高优化权重,让模型真正掌握经验背后的逻辑。
(3)自我归因(Self-Attributing):细粒度优化提升样本效率
核心目标是解决“奖励稀疏、样本浪费”的痛点,让智能体“精准复盘”,流程分为两步:
步级贡献归因:任务完成后,调用LLM作为“复盘专家”,对每一步操作进行因果分析,标注“GOOD”(正向贡献)或“BAD”(负向贡献)标签;
复合奖励构建:将步级标签量化为+1/-1的“过程奖励”,结合任务最终的“结果奖励”,通过加权计算生成综合奖励信号,再通过GRPO算法优化策略,确保每一步交互都能转化为有效学习反馈。
3.2 系统架构设计
AgentEvolver采用分层解耦的架构设计,确保灵活性和扩展性,核心包含三大组件:
(1)Env Service:环境交互中枢
负责管理智能体与外部环境的连接,提供标准化接口,兼容AppWorld、BFCL等模拟环境,以及企业API、工具链等真实场景。支持高并发和实例隔离(基于Ray实现),可同时处理多智能体的并行训练,为大规模进化提供基础支撑。
(2)Context Manager:上下文与推理中枢
定义智能体的“思考逻辑”,负责管理多轮交互的上下文信息和推理模板,内置四种即插即用的上下文管理模板:基础因果模板、推理增强模板、滑动窗口模板、自主记忆管理模板,适配从简单任务到长程复杂任务的不同需求。
(3)veRL训练管线:高效优化中枢
集成数据处理、经验管理、策略优化等功能,支持GRPO等主流强化学习算法,提供灵活的超参数配置接口。通过“选择性增强”“经验剥离”等优化策略,进一步提升训练效率和模型泛化能力。
3.3 技术优势对比
| 对比维度 | 传统强化学习(RL) | AgentEvolver |
|---|---|---|
| 任务生成 | 依赖人工设计,成本高 | 自主生成,无需人工干预 |
| 探索方式 | 随机试错,低效冗余 | 经验引导+随机探索,效率提升50%+ |
| 奖励分配 | 粗粒度最终奖励,样本利用率低 | 细粒度过程+结果奖励,样本效率提升显著 |
| 参数效率 | 依赖大参数量模型,算力成本高 | 中小模型(7B/14B)可实现越级性能 |
| 泛化能力 | 场景适配性差,跨域迁移性能衰减严重 | 跨域迁移性能衰减≤4.3%,泛化性强 |
| 部署成本 | 需定制化开发,周期长 | 模块化架构,支持快速适配和二次开发 |
四、应用场景
AgentEvolver凭借“自主进化”和“高效适配”的特性,已在多个领域展现出明确的应用价值,核心场景包括:
1. 企业级工具与工作流自动化
适用于多API协同操作(如CRM+财务软件+OA集成)、跨部门流程自动化(报销审批、订单履约)、企业数据分析等场景。自我提问机制可自主探索企业系统API功能,生成适配业务的训练任务;自我导航机制复用历史成功流程(如“报表异常优先检查数据接口”);自我归因机制优化关键步骤(如“库存校验为核心步骤”),大幅降低企业定制化开发成本。
2. 游戏与虚拟环境智能体
可用于开放世界游戏自适应NPC、游戏测试自动化、策略游戏AI等场景。自我提问机制能自主生成多样化测试任务(如“验证角色技能与地形的交互”),替代人工测试用例;自我导航机制复用对战经验(如“资源匮乏时优先发展贸易”),让NPC行为更智能;自我归因机制优化长期策略(如“中期放弃防御塔为负面步骤”),提升游戏AI的对抗性和趣味性。
3. 安全关键与高可靠性系统
适用于医疗设备操作辅助、工业控制自动化(如化工厂参数调节)、航空航天系统监控等场景。自我导航机制复用经过验证的安全操作(如“手术前设备无菌校验”),减少危险试错;自我提问机制基于设备说明书生成模拟任务,快速适配新设备;自我归因机制标注关键安全步骤(如“温度超阈值紧急降温为正向步骤”),确保系统可靠性。
4. 软件开发与维护自动化
可实现自动化代码生成、软件漏洞修复、Legacy系统迁移等场景。自我提问机制从需求文档中生成开发任务(如“生成用户登录API接口代码”);自我导航机制复用过往开发经验(如“内存泄漏修复的常见方案”);自我归因机制优化代码编写步骤(如“异常处理为核心步骤”),提升开发效率和代码质量。
5. 教育领域:个性化认知伙伴
能作为学生专属学习助手,通过自我提问机制精准捕捉学习盲区(如“你困惑的是概念还是应用场景”),生成个性化训练任务;自我导航机制复用同类问题的解题经验,提供针对性指导;自我归因机制优化学习步骤(如“公式推导为关键环节”),实现“因材施教”的个性化学习体验。
6. 科研协作:自动化研究助手
可辅助研究人员进行文献分析、实验设计、假设生成等工作。自我提问机制从科研需求中生成探索任务(如“验证某算法在多场景下的有效性”);自我导航机制复用过往科研经验(如“实验数据异常的常见原因”);自我归因机制优化实验步骤(如“样本预处理为核心环节”),大幅提升科研效率。
五、使用方法
AgentEvolver提供了简洁的部署和训练流程,即使是新手也能快速上手,核心步骤如下:
5.1 环境准备
硬件要求:建议配备GPU(显存≥16GB,支持CUDA 11.7+),支持多GPU并行训练;
软件依赖:安装conda、Python 3.9+、CUDA Toolkit 11.7+;
基础安装:克隆GitHub仓库后,运行以下命令安装依赖:
git clone https://github.com/modelscope/AgentEvolver.git cd AgentEvolver bash install.sh
5.2 部署环境服务
以主流的AppWorld环境为例,执行以下命令搭建环境:
cd env_service/environments/appworld bash setup.sh
支持的环境还包括BFCL v3、自定义API环境等,具体配置可参考env_service目录下的说明文档。
5.3 配置可选组件(ReMe经验管理)
若需启用经验管理功能,运行以下命令安装ReMe组件:
bash external/reme/install_reme.sh
该组件用于构建和管理经验池,提升探索效率,无需启用可跳过此步骤。
5.4 启动训练
配置参数:复制示例配置文件并修改关键参数(API密钥、模型路径、训练超参数等):
cp example.env .env # 编辑.env文件,设置MODEL_PATH、API_KEY、TRAIN_STEPS等参数
启动训练:支持基础版(仅启用核心机制)和全功能版(启用所有优化组件)两种模式:
基础版启动:
python launcher.py --mode basic全功能版启动:
python launcher.py --mode full监控训练:训练过程中可通过TensorBoard查看损失曲线、任务成功率等指标:
tensorboard --logdir ./logs
5.5 快速验证
训练完成后,可通过示例脚本验证智能体性能:
python examples/evaluate_agent.py --model_path ./output/model --env appworld
脚本会输出任务完成率、平均步数等核心指标,方便快速评估训练效果。
5.6 训练模式选择
| 训练模式 | 功能包含 | 适用场景 | 训练成本 |
|---|---|---|---|
| 基础版 | 自我提问+自我归因 | 快速验证、简单场景部署 | 低(GPU显存≥16GB,训练步数≤10k) |
| 全功能版 | 三大机制+ReMe+Ray加速 | 复杂场景、高性能需求 | 中(GPU显存≥24GB,支持多GPU并行) |
六、常见问题解答(FAQ)
1. AgentEvolver支持哪些LLM模型?
支持Qwen系列(Qwen2.5-7B/14B/32B)、Llama系列、ChatGLM等主流开源LLM,同时兼容Anthropic API格式和OpenAI SDK接口,可通过.env文件配置模型路径或API密钥。
2. 运行AgentEvolver需要多少算力?
基础版训练(7B模型)最低要求16GB显存GPU,全功能版(14B模型+Ray加速)建议24GB以上显存或多GPU并行;训练步数根据场景调整,一般10k-50k步即可达到理想性能,单GPU训练耗时约1-3天。
3. 如何自定义训练任务偏好?
可在config/task_preference.yaml文件中配置任务难度(实体/操作数量)、风格(是否需要多步骤协作)、领域(如电商、医疗)等参数,自我提问机制会根据配置生成针对性任务。
4. 经验池的大小和更新策略如何设置?
经验池默认最大容量为10k条轨迹,可通过config/experience_pool.yaml调整;更新策略支持“先进先出”“优质留存”两种模式,建议复杂场景选择“优质留存”(保留高奖励轨迹)。
5. 与其他Agent框架(如LangChain Agent)有何区别?
LangChain Agent侧重“工具调用流程编排”,需手动设计任务和提示词;AgentEvolver核心是“自主进化”,无需人工干预即可持续优化能力,更适合长期运行的复杂场景;两者可互补使用(如LangChain负责工具对接,AgentEvolver负责能力进化)。
6. 训练过程中出现“幻觉任务”怎么办?
可在config/self_questioning.yaml中提高任务筛选的严格度,比如降低语义去重的相似度阈值(默认0.8,可调整至0.7),或增加回放验证的次数(默认1次,可调整至2-3次),减少幻觉任务比例。
七、相关链接
GitHub开源仓库:https://github.com/modelscope/AgentEvolver
ModelScope项目主页:https://modelscope.cn/models/modelscope/AgentEvolver
八、总结
AgentEvolver是阿里通义实验室开源的一款革命性AI智能体自进化框架,通过自我提问、自我导航、自我归因三大核心机制,系统性解决了传统强化学习任务稀缺、探索低效、样本利用率低的核心痛点,实现了从“被动训练”到“主动进化”的范式转变。该框架以中小参数量模型(7B/14B)为基础,即可实现超越更大模型的性能表现,同时具备高样本效率、强泛化能力和模块化扩展特性,大幅降低了智能体的训练成本和部署门槛。无论是企业级工作流自动化、游戏AI、安全关键系统,还是教育、科研等领域,AgentEvolver都能快速适配并持续优化,为开发者和企业提供了一套高效、低成本的智能体解决方案,推动AI智能体从“定制化开发”向“自主化进化”迈进。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/agentevolver.html





