Being-H:BeingBeyond 推出的开源跨体化 VLA 基础模型
一、Being-H是什么
Being-H是由BeingBeyond团队开源的以人为中心的跨体化视觉-语言-动作(VLA)基础模型,核心聚焦于解决机器人学习中“形态异构、数据稀缺、泛化能力弱”的行业痛点,通过构建统一的动作空间与人类先验驱动的学习范式,实现不同机器人形态(机械臂、移动机器人、人形机器人等)的通用控制与跨体化技能迁移。
项目历经两代迭代:Being-H0(2025年7月发布,基于大规模人类视频预训练)与Being-H0.5(2026年1月发布,规模化升级,支持多机器人平台跨体化泛化),当前核心版本为Being-H0.5,开源代码、模型权重、训练脚本与推理接口,覆盖从预训练、微调到端侧部署的全流程,是具身智能领域首个实现35000+小时多模态预训练数据、跨5类机器人平台泛化、端侧实时推理的VLA基础模型。
核心定位
技术定位:跨体化VLA基础模型,填补“视觉-语言理解”到“机器人动作执行”的鸿沟,实现“看、听、说、做”一体化的机器人智能。
应用定位:为工业协作机器人、家庭服务机器人、医疗辅助机器人等提供通用控制底座,降低机器人开发门槛,加速具身智能落地。
开源定位:提供可复现、可扩展、可部署的完整方案,支持研究者快速迭代模型,开发者快速集成到实际机器人系统。
项目背景
传统机器人学习面临三大核心瓶颈:
形态异构壁垒:不同机器人(如6轴机械臂、灵巧手、移动机器人)的动作空间、控制接口、运动学特性差异极大,单一策略难以适配多形态机器人。
数据稀缺困境:机器人交互数据获取成本高、标注难度大,小规模数据训练的模型泛化能力差,无法应对复杂真实场景。
端侧部署难题:大模型参数量大、推理速度慢,难以满足机器人实时控制的低延迟需求(通常要求≤100ms)。
Being-H针对以上痛点,以“人类先验为核心、统一动作为桥梁、跨体泛化为目标”,构建了一套完整的机器人学习解决方案,通过UniHand-2.0大规模预训练数据集、统一动作空间设计、MoF(Mixture-of-Flow)混合专家架构,实现了“一次训练,多机通用”的跨体化控制能力。

二、功能特色
Being-H0.5作为项目核心版本,具备跨体化泛化、大规模预训练、低资源微调、端侧实时部署、多场景适配五大核心功能特色,具体如下:
1. 跨体化泛化:一次训练,多机通用
核心能力:支持5类主流机器人平台(6轴机械臂、灵巧手、移动操作机器人、桌面协作机器人、人形机器人)的跨体化技能迁移,无需针对单一机器人重新训练完整模型。
技术支撑:通过统一动作空间(Unified Action Space)将异构机器人的控制指令映射为语义对齐的“动作槽”,实现不同机器人形态间的动作语义互通;结合Manifold-Preserving Gating(流形保持门控)机制,保证模型在传感器噪声、形态变化下的鲁棒性。
性能表现:在LIBERO(桌面操作)与RoboCasa(家庭厨房)两大基准任务中,跨体化泛化性能超越现有SOTA方法,其中LIBERO任务成功率达98.9%,RoboCasa任务成功率达53.9%。
2. 大规模预训练:35000+小时多模态数据,夯实通用能力
数据规模:构建UniHand-2.0数据集,涵盖35000+小时多模态数据(RGB视频、动作捕捉、VR交互、机器人演示),覆盖30种机器人形态、1000+日常操作任务(抓取、放置、组装、烹饪等),是目前全球最大规模的具身智能预训练数据集。
数据多样性:数据来源包括人类日常操作视频、专业机器人演示、VR沉浸式交互数据,覆盖不同场景(家庭、工业、实验室)、不同物体(刚性、柔性、易碎)、不同交互方式(单手、双手、工具辅助),保证模型的通用感知与动作能力。
预训练范式:采用统一序列建模+多任务预训练范式,将人类演示数据与机器人执行数据融合,让模型学习“人类先验+机器人执行”的双重知识,实现从“理解指令”到“执行动作”的端到端映射。
3. 低资源微调:仅微调2%参数,快速适配新任务
核心优势:针对新任务(如特定工业装配、家庭服务),无需从头训练模型,仅需微调2%的模型参数,即可达到90%以上的相对性能,大幅降低训练成本与时间。
适配场景:支持快速适配LIBERO、RoboCasa、Meta World等主流机器人基准,以及自定义任务(如医疗辅助、仓储物流),适配周期从“数周”缩短至“数天”。
技术支撑:基于参数高效微调(PEFT)技术,结合模型的MoF混合专家架构,冻结共享运动原语模块,仅微调特定任务的专家模块,在保证性能的同时大幅减少计算资源消耗。
4. 端侧实时部署:Orin-NX上实时推理,满足机器人控制需求
推理速度:在NVIDIA Orin-NX端侧芯片上实现实时推理(延迟≤50ms),满足机器人实时控制的低延迟要求(通常要求≤100ms),是目前全球最快的端侧VLA模型部署方案。
部署灵活性:支持本地推理、服务化部署(REST API)、机器人端直接集成三种模式,适配从研究仿真到真实机器人部署的全流程。
技术支撑:通过Universal Async Chunking(通用异步分块)机制,优化模型推理流程,适配不同机器人的控制延迟与帧率特性;结合Flash-Attention等加速技术,降低模型推理的计算与内存开销。
5. 多场景适配:覆盖工业、家庭、医疗等多领域
工业场景:适配协作机器人的装配、检测、搬运等任务,支持多机械臂协同控制,提升工业自动化的柔性与效率。
家庭场景:适配服务机器人的烹饪、清洁、物品整理等任务,理解自然语言指令(如“把苹果放在盘子里”),完成复杂家庭操作。
医疗场景:适配医疗辅助机器人的护理、康复、手术辅助等任务,实现精准、稳定的动作执行,降低医护人员工作负担。
科研场景:为机器人学习研究者提供完整的实验平台,支持模型迭代、算法验证、跨体化泛化研究等。
核心功能对比表
| 功能特色 | 核心指标 | 行业价值 |
|---|---|---|
| 跨体化泛化 | 5类机器人平台通用,LIBERO成功率98.9% | 打破机器人形态壁垒,降低多机开发成本 |
| 大规模预训练 | 35000+小时多模态数据,30种机器人形态 | 夯实模型通用能力,减少任务适配数据需求 |
| 低资源微调 | 仅微调2%参数,相对性能≥90% | 缩短任务适配周期,降低训练计算成本 |
| 端侧实时部署 | Orin-NX上延迟≤50ms,实时控制 | 满足真实机器人部署的低延迟需求 |
| 多场景适配 | 工业、家庭、医疗、科研等多领域 | 拓展具身智能应用边界,加速落地进程 |
三、技术细节
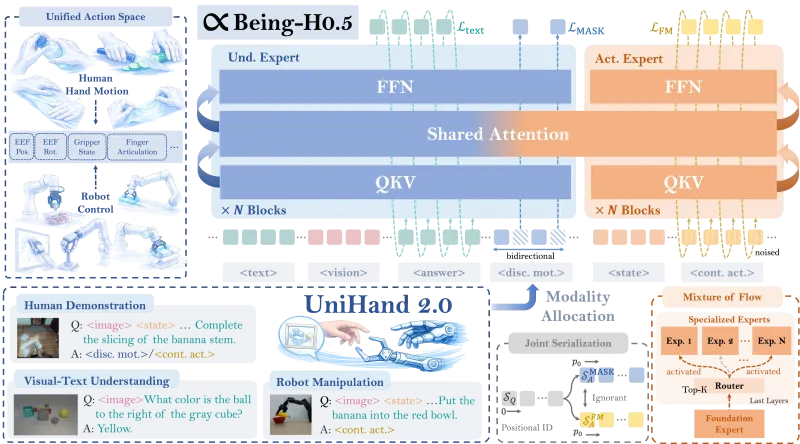
Being-H0.5的技术体系围绕“以人为中心的学习范式、统一动作空间、MoF混合专家架构、鲁棒性优化、端侧部署”五大核心模块构建,实现了跨体化泛化与高效执行的平衡,具体技术细节如下:
1. 以人为中心的学习范式:人类先验驱动的机器人学习
核心思想:将人类交互轨迹视为物理交互的“通用母语”,通过学习人类的操作先验(如抓取姿势、运动轨迹、力控策略),让机器人快速掌握通用操作技能,再通过机器人演示数据优化执行精度。
数据融合:融合三类数据——人类日常操作视频(学习通用动作语义)、动作捕捉/VR交互数据(学习精准运动轨迹)、机器人演示数据(学习机器人执行约束),构建“人类先验→机器人执行”的知识迁移路径。
序列建模:采用Transformer架构进行统一序列建模,将视觉输入(RGB图像)、语言指令(文本)、机器人状态(关节角度、末端位置)、动作指令(控制信号)编码为统一序列,实现多模态信息的端到端融合。
2. 统一动作空间(Unified Action Space):异构机器人的“通用语言”
设计理念:将不同机器人的异构控制空间(如6轴机械臂的关节空间、笛卡尔空间,灵巧手的手指关节空间)映射为语义对齐的动作槽,每个动作槽对应一个通用操作语义(如“抓取”“放置”“旋转”“移动”)。
映射机制:
语义层:定义10+核心操作语义(抓取、放置、平移、旋转、按压、切割等),每个语义对应一组标准化的动作参数(如位置、姿态、力、速度)。
形态层:针对不同机器人形态,设计形态适配器(Embodiment Adapter),将通用动作槽映射为机器人专属的控制指令(如关节角度、末端执行器命令)。
执行层:通过运动学求解器与控制器,将映射后的控制指令转化为机器人的实际运动,保证动作执行的精度与稳定性。
优势:实现“一次模型训练,多机器人适配”,无需针对每个机器人重新设计动作空间与模型架构,大幅降低跨体化开发成本。
3. MoF(Mixture-of-Flow)混合专家架构:共享与专用的平衡
架构设计:采用Mixture-of-Transformers + Mixture-of-Flow的混合架构,分为两大模块:
共享运动原语模块(Shared Motor Primitives):冻结预训练的通用运动知识(如抓取、移动的基础轨迹),所有机器人形态共享,保证模型的通用能力。
形态专用专家模块(Embodiment-Specific Experts):针对不同机器人形态,训练专属的专家网络,学习形态-specific的运动约束与控制策略,保证模型的适配能力。
门控机制:通过流形保持门控(Manifold-Preserving Gating)动态选择专家模块,保证模型在传感器噪声、形态变化、场景变化下的鲁棒性,避免过拟合与泛化能力下降。
参数量设计:核心模型Being-H05-2B参数量为2B,其中共享模块占98%,专用专家模块占2%,既保证了模型的表达能力,又实现了低资源微调。
4. 鲁棒性优化:应对真实世界的不确定性
Manifold-Preserving Gating(流形保持门控):在模型推理时,通过流形学习保持动作空间的连续性与平滑性,避免机器人运动的突变与抖动,提升执行稳定性。
Universal Async Chunking(通用异步分块):将机器人控制指令分块处理,适配不同机器人的控制延迟与帧率特性(如机械臂控制频率100Hz、移动机器人控制频率50Hz),保证跨体化控制的同步性。
数据增强:在预训练与微调阶段,采用视觉增强(随机裁剪、旋转、光照变化)、动作增强(轨迹扰动、力控噪声)、语言增强(指令改写、同义词替换)等方式,提升模型对真实世界不确定性的适应能力。
5. 端侧部署优化:实时推理与低资源消耗
模型压缩:采用量化(INT8/INT4)、剪枝、知识蒸馏等技术,将2B参数量的模型压缩至端侧芯片可运行的规模,同时保持95%以上的性能。
加速技术:集成Flash-Attention、TensorRT、ONNX Runtime等加速框架,优化模型的前向推理流程,降低计算与内存开销。
部署模式:
本地推理:直接在机器人端加载模型,实现低延迟(≤50ms)的实时控制。
服务化部署:启动REST API服务,支持多机器人并发调用,适配分布式机器人系统。
仿真部署:支持Gazebo、Isaac Sim、PyBullet等主流机器人仿真平台,快速验证模型性能。
技术架构图(文字描述)
输入层:视觉(RGB图像)+ 语言(指令文本)+ 机器人状态(关节/末端信息) ↓ 编码层:多模态Transformer编码器(统一序列建模) ↓ 核心层:MoF混合专家架构(共享运动原语 + 形态专用专家 + 流形保持门控) ↓ 解码层:统一动作空间解码器(语义动作槽 → 机器人控制指令) ↓ 执行层:形态适配器 + 运动学求解器 + 机器人控制器 ↓ 输出层:机器人实际动作(抓取、放置、移动等)
四、应用场景
Being-H0.5凭借跨体化泛化、低资源微调、端侧实时部署的核心优势,可广泛应用于工业自动化、家庭服务、医疗辅助、科研教育四大领域,具体场景如下:
1. 工业自动化场景
协作机器人装配:适配6轴协作机器人(如UR5、Franka Emika),完成汽车零部件、3C电子产品的装配、螺丝锁付、焊接等任务,支持多机械臂协同控制,提升装配效率与柔性。
仓储物流搬运:适配移动操作机器人(如AGV+机械臂),完成仓库内的货物抓取、搬运、码垛等任务,理解自然语言指令(如“把红色箱子放在3号货架”),实现无人化仓储作业。
质量检测与分拣:适配桌面协作机器人,完成产品的外观检测、缺陷分拣、分类包装等任务,结合视觉感知与动作控制,实现高精度、高速度的检测分拣。
2. 家庭服务场景
智能厨房操作:适配家庭服务机器人(如三星Bot Chef、松下Home Robot),完成食材处理(切菜、搅拌)、烹饪(煎、炒、煮)、餐具整理等任务,支持复杂多步骤指令(如“先洗番茄,再切成块,最后放进锅里炒”)。
家居清洁与整理:适配清洁机器人+机械臂的复合机器人,完成地面清洁、桌面整理、衣物折叠等任务,适应不同家庭环境(客厅、卧室、厨房)的布局变化。
老人/儿童辅助:适配陪护机器人,完成物品递送(如递水、递药)、陪伴交流、安全监护等任务,通过自然语言交互与精准动作执行,提升家庭生活的便利性与安全性。
3. 医疗辅助场景
康复机器人训练:适配上肢/下肢康复机器人,完成患者的关节活动训练、肌力训练、平衡训练等任务,根据患者的康复进度动态调整动作策略,实现个性化康复治疗。
手术辅助操作:适配手术机器人(如达芬奇机器人的辅助机械臂),完成手术器械传递、组织牵拉、创口清洁等辅助任务,保证动作的精准性与稳定性,降低手术风险。
护理机器人服务:适配护理机器人,完成患者的翻身、喂饭、口腔清洁等护理任务,减轻医护人员的工作负担,提升护理质量。
4. 科研教育场景
机器人学习研究:为研究者提供完整的VLA模型训练与推理框架,支持跨体化泛化、低资源微调、端侧部署等方向的研究,加速具身智能领域的技术迭代。
高校教学实验:为高校机器人、人工智能专业提供教学实验平台,学生可通过修改模型参数、调整训练脚本,快速实现机器人控制任务,提升实践能力。
开源社区协作:作为开源项目,吸引全球开发者参与贡献,共同优化模型性能、拓展应用场景、完善文档与工具链,推动具身智能技术的普及。
应用场景适配表
| 应用领域 | 典型机器人形态 | 核心任务 | 模型版本推荐 |
|---|---|---|---|
| 工业自动化 | 6轴协作机器人、AGV+机械臂 | 装配、搬运、检测、分拣 | Being-H05-2B(通用版) |
| 家庭服务 | 服务机器人、复合机器人 | 烹饪、清洁、整理、陪护 | Being-H05-2B_robocasa(专精版) |
| 医疗辅助 | 康复机器人、手术辅助机器人 | 康复训练、手术辅助、护理服务 | 自定义微调版(基于通用版) |
| 科研教育 | 仿真机器人、桌面机械臂 | 算法验证、教学实验、开源协作 | Being-H05-2B(预训练版) |
五、使用方法
Being-H0.5提供完整的环境搭建、模型下载、训练微调、推理部署流程,支持本地开发与云端训练,以下是详细的使用步骤:
1. 环境搭建
硬件要求
训练环境:NVIDIA A100/H100 GPU(≥40GB显存),推荐8卡并行训练;CPU≥16核,内存≥128GB,硬盘≥1TB(用于存储数据集与模型权重)。
推理环境:
端侧:NVIDIA Orin-NX/Orin AGX(≥16GB显存),支持实时推理;
云端:NVIDIA T4/A10 GPU(≥16GB显存),支持服务化部署。
系统要求:Ubuntu 20.04/22.04,Python 3.10,CUDA 11.7/11.8。
软件安装
# 1. 克隆仓库 git clone https://github.com/BeingBeyond/Being-H.git cd Being-H # 2. 创建conda环境 conda create -n beingh python=3.10 conda activate beingh # 3. 安装基础依赖 pip install -r requirements.txt # 4. 安装Flash-Attention(加速推理) pip install flash-attn --no-build-isolation # 5. 安装机器人仿真依赖(可选,用于仿真验证) pip install gymnasium==0.29.1 pybullet==3.2.6 isaacsim==4.0.0
2. 模型下载
Being-H0.5的模型权重托管在Hugging Face,提供预训练版、LIBERO专精版、RoboCasa专精版、通用版四个版本,下载方式如下:
方式1:Hugging Face Hub下载(推荐)
# 安装Hugging Face Hub pip install huggingface-hub # 下载预训练版(Being-H05-2B) huggingface-cli download BeingBeyond/Being-H05-2B --local-dir ./models/Being-H05-2B # 下载LIBERO专精版(Being-H05-2B_libero) huggingface-cli download BeingBeyond/Being-H05-2B_libero --local-dir ./models/Being-H05-2B_libero # 下载RoboCasa专精版(Being-H05-2B_robocasa) huggingface-cli download BeingBeyond/Being-H05-2B_robocasa --local-dir ./models/Being-H05-2B_robocasa # 下载通用版(Being-H05-2B_libero_robocasa) huggingface-cli download BeingBeyond/Being-H05-2B_libero_robocasa --local-dir ./models/Being-H05-2B_libero_robocasa
方式2:手动下载
访问Hugging Face合集(https://huggingface.co/collections/BeingBeyond/being-h05),选择对应模型版本,下载权重文件至`./models/`目录。
3. 训练与微调
(1)预训练(可选,仅用于研究者迭代模型)
预训练需要UniHand-2.0数据集(35000+小时),目前仅对合作研究者开放,申请方式见官方文档。预训练脚本如下:
# 启动预训练脚本(8卡A100并行) bash scripts/train-pretrain.sh \ --config configs/pretrain/beingh05-2b.yaml \ --data_path /path/to/UniHand-2.0 \ --output_dir ./output/pretrain \ --num_gpus 8
(2)微调(推荐,用于适配新任务)
以LIBERO任务微调为例,仅需微调2%参数,步骤如下:
# 1. 下载LIBERO数据集(https://github.com/Lifelong-Robot-Learning/LIBERO) # 2. 启动微调脚本 bash scripts/train-libero-all.sh \ --model_path ./models/Being-H05-2B \ --data_path /path/to/LIBERO \ --output_dir ./output/libero \ --num_gpus 4 \ --peft_ratio 0.02 # 仅微调2%参数
(3)自定义任务微调
针对自定义任务(如工业装配、医疗辅助),需准备自定义数据集(视觉+语言+动作),修改配置文件后启动微调脚本:
# 复制并修改配置文件 cp configs/finetune/custom.yaml configs/finetune/my_task.yaml # 编辑my_task.yaml,设置数据集路径、任务类型、微调参数等 vim configs/finetune/my_task.yaml # 启动自定义任务微调 bash scripts/train-custom.sh \ --config configs/finetune/my_task.yaml \ --model_path ./models/Being-H05-2B \ --output_dir ./output/my_task \ --num_gpus 2
4. 推理部署
(1)本地政策推理(快速验证)
from BeingH.inference.beingh_policy import BeingHPolicy
import cv2
import numpy as np
# 1. 加载模型(以LIBERO专精版为例)
policy = BeingHPolicy(
model_path="./models/Being-H05-2B_libero",
device="cuda:0"
)
# 2. 准备输入数据
# 视觉输入:224×224 RGB图像(支持单帧/多帧)
image = cv2.imread("test_image.jpg")
image = cv2.resize(image, (224, 224))
image = np.transpose(image, (2, 0, 1)) # 转为CHW格式
images = np.expand_dims(image, axis=0) # 增加batch维度
# 机器人状态:关节角度/末端位置(根据机器人形态调整)
robot_state = np.array([[0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]) # 6轴机械臂示例
# 任务指令:自然语言文本
instruction = "Pick up the red block and place it on the blue plate"
# 3. 推理获取动作
action = policy.predict(
images=images,
state=robot_state,
instruction=instruction
)
# 4. 输出动作(统一动作槽 → 机器人控制指令)
print("Predicted action:", action)(2)服务化部署(多机器人并发调用)
# 启动推理服务(端口8000,设备cuda:0)
python BeingH/inference/service.py \
--model_path ./models/Being-H05-2B_libero \
--port 8000 \
--device cuda:0
# 客户端调用示例(Python)
import requests
import cv2
import numpy as np
url = "http://localhost:8000/predict"
image = cv2.imread("test_image.jpg")
image = cv2.resize(image, (224, 224))
image = np.transpose(image, (2, 0, 1)).tolist()
robot_state = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
instruction = "Pick up the red block and place it on the blue plate"
data = {
"images": [image],
"state": robot_state,
"instruction": instruction
}
response = requests.post(url, json=data)
print("Predicted action:", response.json()["action"])(3)端侧部署(Orin-NX实时推理)
# 1. 在Orin-NX上配置环境(同本地环境搭建) # 2. 下载模型权重至Orin-NX # 3. 启动端侧推理脚本 python BeingH/inference/edge_inference.py \ --model_path ./models/Being-H05-2B_libero \ --device cuda:0 \ --quantize int8 # INT8量化,加速推理
5. 仿真验证
支持Isaac Sim、Gazebo、PyBullet等仿真平台,以Isaac Sim为例:
# 1. 安装Isaac Sim 4.0.0(https://developer.nvidia.com/isaac-sim) # 2. 启动Isaac Sim仿真环境 # 3. 运行仿真推理脚本 python BeingH/benchmark/isaac_sim_inference.py \ --model_path ./models/Being-H05-2B_libero \ --task libero_tabletop \ --device cuda:0
六、常见问题解答(FAQ)
1. 模型下载失败怎么办?
解决方案:
检查网络连接,确保可访问Hugging Face Hub;
使用代理(若网络受限),设置
HF_ENDPOINT环境变量:export HF_ENDPOINT=https://hf-mirror.com;手动下载模型权重,解压至
./models/目录;检查磁盘空间,确保≥50GB(模型权重+缓存)。
2. 训练/微调时出现显存不足怎么办?
解决方案:
降低batch size(修改配置文件中的
batch_size参数);启用梯度累积(修改配置文件中的
gradient_accumulation_steps参数);使用FP16/FP8混合精度训练(修改配置文件中的
precision参数);减少模型参数量(使用Being-H05-1B版本,若有);
增加GPU数量(并行训练)。
3. 推理时延迟过高,无法满足实时控制需求怎么办?
解决方案:
启用INT8/INT4量化(修改推理脚本中的
quantize参数);使用TensorRT/ONNX Runtime加速(编译模型为TensorRT引擎);
降低视觉输入分辨率(从224×224降至112×112,性能略有下降);
简化模型架构(使用轻量级专家模块);
部署在Orin AGX等更高性能的端侧芯片上。
4. 跨体化泛化性能差,无法适配新机器人形态怎么办?
解决方案:
增加新机器人形态的演示数据(≥1000条),进行低资源微调;
优化形态适配器(Embodiment Adapter),确保统一动作空间到机器人控制指令的映射准确;
启用流形保持门控(Manifold-Preserving Gating),提升模型鲁棒性;
参考官方文档中的跨体化泛化教程,调整模型参数与训练策略。
5. 如何将模型集成到真实机器人系统中?
解决方案:
确定机器人的控制接口(ROS/ROS 2、Socket、串口等);
编写形态适配器,将模型输出的统一动作槽映射为机器人专属控制指令;
集成推理脚本到机器人的控制节点,实现实时推理与动作执行;
进行真机测试,优化动作精度与稳定性(调整力控参数、运动轨迹等);
参考官方真机部署文档(即将开源),获取详细集成步骤。
6. 自定义任务需要准备哪些数据?
解决方案:
视觉数据:RGB图像(≥224×224分辨率),覆盖任务的不同阶段、不同视角、不同物体;
语言数据:自然语言指令(≥10条/任务),描述任务的目标与步骤;
动作数据:机器人的控制指令(关节角度、末端位置、力控信号等),与视觉/语言数据一一对应;
数据量:建议≥5000条样本(简单任务),≥10000条样本(复杂任务);
数据格式:参考官方数据集格式(
configs/dataset/目录下的示例),确保数据可被模型加载。

七、相关链接
Hugging Face模型合集:https://huggingface.co/collections/BeingBeyond/being-h05
官方论文(Being-H0.5):https://arxiv.org/pdf/2601.12993
官方论文(Being-H0):https://arxiv.org/pdf/2507.15597
八、总结
Being-H作为BeingBeyond团队开源的以人为中心的跨体化VLA基础模型,通过UniHand-2.0大规模预训练数据集、统一动作空间设计、MoF混合专家架构与鲁棒性优化技术,成功解决了机器人学习中形态异构、数据稀缺、泛化能力弱、端侧部署难的核心痛点,实现了5类机器人平台的跨体化泛化、35000+小时多模态数据的预训练、仅2%参数的低资源微调与Orin-NX上的实时端侧部署,在LIBERO、RoboCasa等主流基准任务中达到SOTA性能。项目开源代码、模型权重、训练脚本与推理接口,覆盖从研究到落地的全流程,可广泛应用于工业自动化、家庭服务、医疗辅助、科研教育等领域,为具身智能的发展提供了可复现、可扩展、可部署的完整解决方案,同时通过开源社区协作,持续推动机器人学习技术的迭代与普及,加速通用机器人控制的落地进程。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/being-h.html