DeepSeek-Math-V2:DeepSeek开源的可自我验证数学推理大语言模型
一、DeepSeek-Math-V2是什么
DeepSeek-Math-V2是由深度求索(deepseek-ai)团队基于DeepSeek-V3.2-Exp-Base模型打造的开源数学推理大模型,核心聚焦于可自我验证的数学推理能力构建。该模型创新性地提出自验证数学推理方法,通过生成器-验证器的闭环机制实现严谨的定理证明,在IMO 2025、CMO 2024等顶级数学竞赛中达到金牌水平,Putnam 2024竞赛斩获118/120的接近满分成绩。
该项目核心目标是构建“生成-验证”一体化的数学推理系统——不仅能输出数学问题的解题步骤和结论,还能通过内置的验证器对推理过程的严谨性、逻辑性和正确性进行自主校验,同时可通过扩展验证计算自动标记难验证的新证明,形成训练数据闭环以持续优化模型能力。

二、功能特色
DeepSeek-Math-V2的核心优势在于其“自验证”能力和顶尖的竞赛解题表现,具体可拆解为以下五大特色:
1. 独创自验证数学推理机制
传统数学推理大模型的痛点在于“能解题但难验真”,模型输出的步骤可能存在逻辑跳跃、隐含假设不明确等问题,且无法自主识别错误。DeepSeek-Math-V2创新性地设计了生成器-验证器双模块闭环:生成器负责输出完整的解题或证明步骤,验证器则基于数学公理、定理体系对每一步推理进行严谨校验,不仅能判断最终结论的正确性,还能定位推理过程中的逻辑漏洞。
更关键的是,该模型支持“扩展验证计算”功能,可自动识别并标记那些现有验证体系难以判定的新证明思路,将这类数据转化为验证器的增量训练集,实现验证能力的持续迭代,让模型的推理严谨性随数据积累不断提升。
2. 顶级数学竞赛金牌级表现
模型的实力在权威数学竞赛中得到了充分验证,其成绩远超同类型开源模型,具体表现如下表所示:
| 竞赛名称 | 模型成绩 | 竞赛等级 | 对应水平 |
|---|---|---|---|
| IMO 2025 | 金牌水平 | 国际奥林匹克数学竞赛 | 全球顶尖中学生数学水平 |
| CMO 2024 | 金牌水平 | 中国奥林匹克数学竞赛 | 国内顶尖中学生数学水平 |
| Putnam 2024 | 118/120 | 美国大学生数学竞赛 | 接近竞赛满分,处于全球前0.1%梯队 |
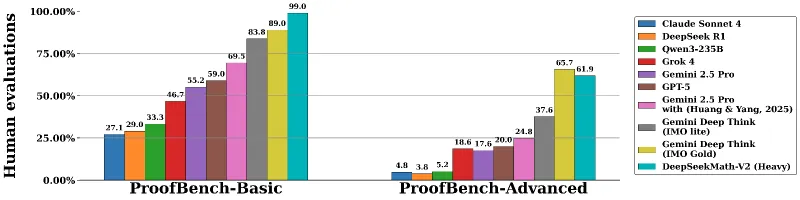
此外,在专业数学推理基准测试集IMO-ProofBench上,DeepSeek-Math-V2也取得了领先的准确率,证明其在定理证明类任务上的通用性和可靠性。
3. 全流程推理步骤可追溯
不同于部分模型仅输出“结论”或“简略步骤”的模式,DeepSeek-Math-V2要求生成器输出精细化、可追溯的完整推理链。无论是代数方程求解、几何定理证明,还是数论、组合数学等复杂领域的问题,模型都会按照数学学科的规范逻辑,从已知条件、公理引用、中间推导到最终结论,呈现完整的步骤序列,且验证器会对每个步骤的合理性进行标注,让推理过程“有据可依、有迹可查”。
4. 丰富的内置竞赛数据集
仓库内置了多套高价值数学竞赛题目数据集,涵盖CMO 2024、IMO 2025、Putnam 2024等不同级别、不同类型的竞赛真题,且配套了模型的预测输出文件。这些数据集不仅可用于模型的效果验证,还能为数学AI的学术研究提供标准化的测试基准,降低了相关领域的研究门槛。
5. 轻量化推理部署支持
尽管模型具备顶尖的数学推理能力,但项目团队对推理代码进行了针对性优化,提供了简洁的运行脚本和工具类。用户无需复杂的环境配置,即可基于官方提供的推理代码实现模型调用,且支持灵活的参数调整,兼顾了能力强度与部署便捷性。
三、技术细节
DeepSeek-Math-V2的技术架构围绕“生成器-验证器”双核心展开,其底层原理和实现逻辑可分为以下三个层面:
1. 基础模型与预训练底座
DeepSeek-Math-V2的基础模型为DeepSeek-V3.2-Exp-Base,这是深度求索团队自研的大语言模型,具备较强的通用语义理解和逻辑推理能力。在预训练阶段,模型已学习了海量的数学领域文本数据,包括教材、论文、竞赛题解等,构建了扎实的数学知识图谱和基础推理能力,为后续的专项微调奠定了基础。
2. 生成器的训练逻辑
生成器的核心任务是“输出符合数学逻辑的完整解题/证明过程”,其训练过程分为两个阶段:
有监督微调阶段:使用高质量的数学题解数据集(包括竞赛真题的标准解答)对基础模型进行微调,让模型学习规范的数学推理步骤、符号表达和逻辑范式,确保输出内容符合数学学科的书写和推导规范。
奖励模型微调阶段:以验证器作为奖励模型,对生成器的输出进行打分——不仅关注结论的正确性,更对推理步骤的严谨性、完整性、逻辑性进行多维度评估,通过强化学习让生成器不断优化输出质量,减少逻辑跳跃和步骤缺失问题。
3. 验证器的核心原理
验证器是DeepSeek-Math-V2的技术核心,其能力直接决定了模型的自验证效果,具体实现包括三个关键环节:
公理与定理库构建:验证器内置了完备的数学公理、定理、推论体系,涵盖初等数学、高等数学、数论、几何、组合数学等多个领域,形成了标准化的“逻辑校验基准”。
步骤级校验机制:对于生成器输出的每一步推理,验证器会逐一匹配公理/定理库,判断该步骤是否符合已有数学体系的逻辑,同时识别是否存在隐含假设、条件遗漏等问题,例如在几何证明中是否默认了未给出的图形性质,在代数推导中是否忽略了变量的取值范围。
难验证证明的自动标记与迭代:当遇到全新的证明思路或复杂的跨领域推理时,验证器会通过“扩展验证计算”模块,结合外部数学工具和知识库进行辅助判断,对无法确定的证明进行标记,并将这类数据纳入验证器的增量训练集,通过持续学习提升验证能力的覆盖范围和准确性。
4. 生成-验证循环的协同机制
生成器与验证器并非独立运行,而是形成了闭环协同:生成器输出推理过程后,验证器进行全流程校验并反馈问题;生成器根据验证器的反馈,对推理步骤进行修正和补充,直到验证器确认推理过程无逻辑漏洞、结论正确。这一循环机制让模型具备了“自主纠错”的能力,大幅提升了推理结果的可靠性。
四、应用场景
DeepSeek-Math-V2的技术能力和开源属性使其可适配多个领域的应用需求,核心应用场景包括以下五类:
1. 学术研究领域
数学推理AI的基准测试:仓库内置的IMO、CMO、Putnam等竞赛数据集,可作为数学大模型的权威测试基准,研究人员可基于这些数据评估不同模型的推理能力,推动数学AI技术的迭代。
定理证明自动化研究:模型的自验证机制为“机器自动定理证明”提供了新的技术思路,研究人员可基于其开源代码,探索更高效的生成-验证协同方案,攻克更复杂的数学猜想证明难题。
2. 教育领域
智能教辅工具开发:可集成到在线教育平台,为学生提供步骤级的解题指导和推理过程校验。例如学生提交自己的解题步骤后,模型可自动识别逻辑错误并给出修正建议,同时输出规范的解答过程,帮助学生理解数学推理的核心逻辑。
竞赛培训辅助系统:针对奥数、大学生数学竞赛等场景,模型可模拟竞赛真题的解题思路,为选手提供多样化的解法参考,同时验证选手自主解题步骤的严谨性,提升竞赛训练的效率和针对性。
3. 工业与科研计算领域
工程数学问题辅助求解:在物理、工程、金融等领域,存在大量复杂的数学建模和求解任务,例如金融衍生品定价的偏微分方程、工程结构的力学方程等。模型可辅助技术人员梳理推理逻辑,验证计算步骤的正确性,降低人工推导的失误率。
数学类AI工具开发:开发者可基于DeepSeek-Math-V2的开源权重和代码,快速搭建垂直领域的数学AI工具,如专业的几何证明助手、数论问题求解器等,缩短工具的研发周期。
4. 大模型能力增强插件
可作为通用大语言模型的“数学推理增强插件”,为通用LLM补充专业的数学推理和验证能力。例如,当通用模型遇到复杂数学问题时,可调用DeepSeek-Math-V2的接口,获取严谨的解题步骤和验证结果,提升通用模型在数学领域的服务能力。
5. 数学知识图谱完善
模型在训练和推理过程中积累的大量精细化推理数据,可用于完善数学知识图谱的逻辑关联。例如,通过挖掘不同定理之间的推导关系,补充知识图谱中的“逻辑链路”,让知识体系更具关联性和可解释性。
五、使用方法
DeepSeek-Math-V2的使用分为模型获取、环境配置、推理运行三个核心步骤,整体流程简洁且易操作,具体如下:
1. 模型权重获取
模型的核心权重文件托管在HuggingFace平台,用户可通过以下两种方式获取:
直接访问HuggingFace仓库:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2,根据页面指引下载模型权重(支持全量权重和量化权重,满足不同部署需求)。
通过HuggingFace的
transformers库自动加载,需提前安装对应依赖,具体代码可参考官方仓库的示例。
2. 运行环境配置
项目对运行环境有基础的依赖要求,建议的配置如下:
操作系统:Linux(推荐Ubuntu 20.04及以上版本),也可适配Windows(需配置WSL)和macOS(M系列芯片需适配环境)。
Python版本:Python 3.8~3.11(兼容性最佳)。
核心依赖库:transformers>=4.35.0、torch>=2.0.0、sentencepiece、accelerate等,可通过官方提供的
requirements.txt一键安装,命令如下:
pip install -r requirements.txt
硬件要求:若运行全量模型,建议使用至少16GB显存的GPU(如NVIDIA A10、RTX 3090及以上);若使用量化模型,可在8GB显存的GPU或CPU环境下运行(CPU环境推理速度较慢,仅建议测试使用)。
3. 推理运行步骤
官方仓库的inference目录提供了完整的推理代码,用户可通过以下步骤快速实现模型调用:
克隆仓库到本地
git clone https://github.com/deepseek-ai/DeepSeek-Math-V2.git cd DeepSeek-Math-V2
准备输入数据 可直接使用仓库
inputs目录下的竞赛数据集(如CMO2024.json),也可自定义数学问题,输入格式需符合JSON规范,示例如下:
{
"question_id": "cmo2024_01",
"question": "已知△ABC中,AB=AC,D为BC中点,E为AD上一点,且BE=BC,求∠BAC的度数。",
"difficulty": "hard"
}执行推理脚本 运行
inference目录下的run.sh脚本,或直接调用main.py主程序,命令示例如下:
cd inference python main.py --model_path "path/to/your/model" --input_file "../inputs/CMO2024.json" --output_file "../outputs/CMO2024_predict.jsonl"
查看输出结果 推理完成后,结果会保存到指定的输出文件中,输出内容包含完整的推理步骤、验证器的校验结果和最终结论,示例片段如下:
{
"question_id": "cmo2024_01",
"question": "已知△ABC中,AB=AC,D为BC中点,E为AD上一点,且BE=BC,求∠BAC的度数。",
"prediction": "解:∵AB=AC,D为BC中点,∴AD⊥BC,BD=DC=1/2BC(等腰三角形三线合一)...",
"verification_result": "推理步骤符合等腰三角形性质和三角形内角和定理,无逻辑漏洞,结论正确",
"final_answer": "∠BAC=108°"
}4. 自定义参数调整
用户可根据需求调整推理参数,核心可配置参数包括:
max_length:控制生成文本的最大长度,默认值为2048,可根据问题复杂度调整。temperature:调节生成的随机性,取值范围01,值越低输出越保守,值越高越易产生创新解法(建议数学推理任务设置为0.30.5)。verification_level:验证器的校验严格程度,可选basic(基础校验)、strict(严格校验),严格模式会对每一步进行更细致的逻辑排查。

六、常见问题解答
1. 问:模型支持哪些类型的数学问题?
答:模型支持初等数学(代数、几何、三角函数)、高等数学(微积分、线性代数)、数论、组合数学、概率论等多个领域的问题,尤其擅长竞赛类的证明题和复杂计算题。但暂不支持超前沿的数学猜想(如黎曼猜想)和需要专业实验数据支撑的应用数学问题。
2. 问:模型在CPU环境下能否运行?为什么速度很慢?
答:模型支持CPU运行,但由于数学推理任务对计算量要求较高,且CPU的并行计算能力弱于GPU,因此推理速度会显著慢于GPU环境(例如一道竞赛题的推理,GPU需1030秒,CPU可能需要510分钟)。建议优先使用GPU环境部署,若仅做小批量测试,可选择量化后的轻量模型。
3. 问:验证器偶尔会误判推理步骤,如何解决?
答:验证器的误判通常出现在两类场景:一是全新的非标准证明思路,二是跨领域的复杂推理。用户可通过以下方式优化:① 将verification_level调整为strict模式,提升校验的全面性;② 手动补充证明过程中的隐含公理或条件,帮助验证器理解特殊思路;③ 参与项目社区反馈,将误判案例提交给官方,用于验证器的迭代优化。
4. 问:能否将模型用于商业产品?
答:可以。DeepSeek-Math-V2遵循Apache License 2.0开源协议,允许商用,但需遵循协议条款:① 保留原始版权声明和许可证信息;② 若对模型进行修改并分发,需公开修改部分的源代码;③ 不承担开源方的技术和法律责任。
5. 问:如何获取更多的训练数据集?
答:官方仓库已提供核心竞赛数据集,此外可通过三个渠道补充数据:① 参考官方文档的数据集构建指南,自行整理数学教材、论文中的题解数据;② 从HuggingFace Datasets平台下载公开数学数据集(如GSM8K、MATH);③ 加入项目社区,获取社区用户共享的定制化数据集。
6. 问:模型的推理结果是否100%正确?
答:尽管模型在竞赛中表现优异,但无法保证100%的正确率。在面对极端复杂的多步骤推理、特殊边界条件的问题时,仍可能出现步骤疏漏或结论错误。建议将模型输出作为参考,关键场景下需人工复核推理过程和结论。
七、相关链接
HuggingFace模型仓库:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
八、总结
DeepSeek-Math-V2是深度求索团队在数学推理大模型领域的重磅开源成果,它以DeepSeek-V3.2-Exp-Base为基础,通过独创的生成器-验证器闭环机制实现了可自我验证的数学推理能力,不仅在IMO 2025、CMO 2024等顶级数学竞赛中达到金牌水平,还在Putnam 2024中取得接近满分的优异成绩,其技术内核为数学AI的严谨性和可靠性提供了新范式。该项目提供了完整的开源代码、竞赛数据集和推理工具,支持多场景的部署和二次开发,既可为学术研究提供标准化的数学推理测试基准,也能为教育、工业计算等领域的数学AI应用提供核心技术支撑,同时Apache License 2.0协议保障了其商用可行性,是数学垂直领域大模型的标杆性项目,为行业提供了兼具技术深度和实用价值的开源解决方案。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/deepseek-math-v2.html





