InfiniteTalk:开源音频驱动的稀疏帧视频配音框架,支持无限长度多模态视频生成
一、InfiniteTalk是什么?
InfiniteTalk是由美团视觉智能团队开源的音频驱动视频生成框架,专为稀疏帧视频配音(Sparse-Frame Video Dubbing)设计,同时支持图像到视频(Image-to-Video)和视频到视频(Video-to-Video)两种核心生成模式。简单来说,它能接收“参考图像/视频”与“目标音频”作为输入,自动生成一段与音频精准同步的视频——不仅实现唇形与语音的高度匹配,还能让人物的头部转动、身体姿态、面部表情等细节随音频节奏自然变化,且支持无限制时长的视频生成。
与传统视频配音工具相比,InfiniteTalk的核心创新在于打破了“仅关注唇形”的技术局限和“时长受限”的应用瓶颈。传统配音方法往往只优化唇部动作,导致头部、身体动作与音频脱节,且生成视频时长较短;而InfiniteTalk通过多模态特征融合与生成网络优化,实现了“全维度姿态同步+无限长度输出”,同时解决了同类工具(如MultiTalk)存在的手部/身体扭曲、唇形同步精度不足等问题,成为一款兼顾“精准度、稳定性、灵活性”的开源视频生成解决方案。
二、功能特色
InfiniteTalk的功能特色围绕“精准同步、无限长度、高稳定性、灵活适配”四大核心展开,具体可分为以下6点,且部分优势已通过与同类工具(MultiTalk)的对比得到验证:
1. 稀疏帧视频配音:全维度音频-姿态同步
这是InfiniteTalk的核心功能。传统视频配音仅聚焦唇部动作与音频的匹配,而InfiniteTalk实现了“唇形+头部运动+身体姿态+面部表情”的全维度同步。例如,输入一段人物静止的参考视频和一段包含情绪起伏的音频,生成的视频中人物不仅唇形与语音精准对应,还会根据音频的节奏点头、转头,身体姿态自然调整,面部表情(如微笑、严肃)也会随音频情绪变化——这种全维度同步让生成的视频更具真实感和沉浸感。
2. 无限长度生成:突破时长限制
InfiniteTalk支持“无上限时长”视频生成,这是其区别于多数同类工具的关键优势。无论是生成1分钟的短视频,还是10分钟以上的长视频(如课程讲解、直播回放),都能保持姿态同步性和身份一致性。其中:
视频到视频(V2V)模式:可完全模仿原始视频的镜头运动(虽非完全一致,但通过SDEdit优化后精度显著提升);
图像到视频(I2V)模式:单张图像可直接生成最长1分钟的高质量视频,超过1分钟可通过“图像转视频脚本”(平移/缩放图像)延长时长,有效缓解颜色偏移问题。
3. 高稳定性:减少扭曲与失真
相比同类工具MultiTalk,InfiniteTalk大幅优化了生成视频的稳定性。在长视频生成过程中,人物的手部、身体轮廓不易出现扭曲、变形,面部特征(如五官、发型)的身份一致性更强,不会出现“越生成越不像原人物”的问题。这一优势源于其优化的特征融合网络与TeaCache加速技术,减少了帧间特征漂移。
4. 高精度唇形同步:优于同类工具
唇形同步是视频配音的核心需求,InfiniteTalk通过“音频特征精准提取+跨模态注意力对齐”技术,实现了优于MultiTalk的唇形同步效果。用户可通过调整“音频CFG参数”(推荐3-5)进一步优化同步精度——参数越高,唇形与音频的匹配度越高,适合对配音精准度要求极高的场景(如影视台词替换)。
5. 多模态与多场景适配
InfiniteTalk支持两种核心生成模式,且适配多种使用场景:
视频到视频(V2V):输入现有视频+新音频,生成“原画面+新配音+姿态同步”的视频,适合影视本地化配音、短视频二次创作;
图像到视频(I2V):输入单张图像+音频,生成“静态图像动起来”的视频,适合虚拟人直播、广告素材制作、角色动画生成;
额外支持:多人动画生成(输入包含多个人物的图像/视频,实现多角色同时唇形+姿态同步)、480P/720P分辨率切换,满足不同清晰度需求。
6. 灵活部署:适配低显存与多GPU
InfiniteTalk针对不同硬件条件做了充分优化,让更多用户能轻松部署:
低显存设备:通过
--num_persistent_param_in_dit 0参数或FP8量化模型,可在显存有限的GPU上运行(如16GB显存即可生成480P视频);多GPU并行:支持多GPU分布式推理(如8卡并行),提升长视频生成速度;
加速插件兼容:支持FusionX/Lightx2v LoRA插件,推理步数从40步减少至4-8步,生成速度提升5-10倍,且保持高质量输出。

三、技术细节
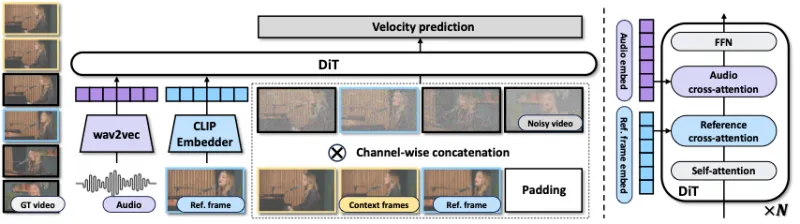
InfiniteTalk的技术核心是“音频-视觉特征精准对齐+无限长度生成优化”,其整体架构由“特征提取模块、特征融合模块、生成模块、优化模块”四部分组成,关键技术细节如下:
1. 整体架构流程
(注:架构图源自项目官方资产,核心流程如下):
输入层:接收参考帧(图像/视频关键帧)、目标音频、上下文帧(稀疏帧);
特征提取:
音频特征:通过chinese-wav2vec2-base模型提取音频频谱特征,生成音频嵌入(Audio Embed);
视觉特征:通过CLIP嵌入器提取参考帧的视觉特征(Ref. frame embed),包含人物身份、姿态、场景信息;
特征融合:通过FFN(前馈网络)和cross-attention(跨模态注意力机制)对齐音频与视觉特征,确保唇形、姿态与音频节奏匹配;
生成模块:基于DiT(Diffusion Transformer)生成网络,通过N层堆叠的Self-attention和cross-attention,逐步生成目标视频帧,同时通过Velocity Prediction(速度预测)优化帧间运动连贯性;
优化模块:通过TeaCache加速、量化技术、多GPU并行(FSDP)等优化推理速度与显存占用。
2. 核心技术组件说明
为了让非技术用户也能理解,以下通过表格简要说明关键技术组件的作用:
| 技术组件 | 核心作用 | 技术优势 |
|---|---|---|
| wav2vec音频编码器 | 提取中文音频的韵律、节奏特征,生成高质量音频嵌入 | 适配中文语音,特征提取精度高,为唇形同步提供基础 |
| CLIP视觉嵌入器 | 提取参考图像/视频的人物身份、姿态、场景特征,确保生成视频身份一致性 | 跨模态特征对齐能力强,减少人物“变脸”“变装”等身份漂移问题 |
| DiT生成网络 | 基于扩散模型的Transformer架构,融合音视频特征生成目标帧 | 支持长序列生成,帧间连贯性好,减少扭曲失真 |
| cross-attention机制 | 对齐音频节奏与视觉姿态(如音频重音对应头部转动) | 实现“全维度同步”,而非仅唇形匹配,提升视频真实感 |
| TeaCache加速技术 | 缓存重复计算的特征,减少推理过程中的冗余运算 | 提升长视频生成速度,降低显存占用 |
| FP8/INT8量化 | 对模型权重进行量化压缩,减少显存占用 | 适配低显存GPU,无需高端硬件即可运行 |
| FusionX/Lightx2v LoRA | 低步数推理插件,通过LoRA微调优化生成效率 | 推理步数从40步降至4-8步,速度提升5-10倍,且保持高质量 |
3. 关键优化策略
身份一致性优化:通过CLIP视觉特征锁定人物身份,结合“帧间特征平滑”技术,确保长视频中人物五官、发型、服装不发生突变;
长视频颜色偏移缓解:针对I2V模式长视频颜色漂移问题,提供“图像转视频脚本”(平移/缩放图像),通过增加帧间视觉关联性减少偏移;
镜头运动优化:V2V模式中支持SDEdit工具,提升镜头运动与原始视频的一致性,适合对画面稳定性要求高的场景(如影视配音);
显存优化:除了量化技术,还通过“参数分片”“动态显存分配”等策略,让16GB显存GPU可流畅运行480P视频生成。
四、应用场景
InfiniteTalk的应用场景覆盖“内容创作、影视制作、虚拟人、在线教育、广告营销”等多个领域,以下结合具体需求与解决方案:
| 应用场景 | 目标用户 | 核心需求 | InfiniteTalk解决方案 |
|---|---|---|---|
| 影视/短视频本地化配音 | 影视制作团队、短视频创作者 | 替换视频音频(如外语转中文),要求唇形+姿态同步,无时长限制 |
采用V2V模式,--mode streaming生成无限长度视频,调整sample_audio_guide_scale=4优化同步 |
| 虚拟人直播/互动 | 直播平台、虚拟人开发者 | 单张虚拟人图像+实时音频,生成长期直播视频,要求姿态自然、身份一致 | 采用I2V模式,结合图像转视频脚本延长时长,启用TeaCache加速实时生成 |
| 在线教育课件制作 | 教师、教育机构 | 将静态PPT/讲义图像+讲解音频,生成动态视频,要求画面连贯、重点突出 |
采用I2V模式,--size infinitetalk-720生成高清视频,搭配头部转动强调重点内容 |
| 游戏/动画角色配音 | 游戏开发者、动画工作室 | 多角色图像/视频+配音音频,生成多人物同步动画,要求角色动作不扭曲 |
采用多人动画模式,使用multi/infinitetalk.safetensors权重,--num_persistent_param_in_dit 0优化显存 |
| 广告营销素材制作 | 营销团队、品牌方 | 快速生成产品宣传视频(如模特介绍产品+音频),要求生成速度快、画质高 |
启用FusionX LoRA,sample_steps=8快速生成,--size infinitetalk-720保证高清输出 |
| 社交媒体内容创作 | 个人创作者、Vlogger | 给旅行Vlog、生活视频替换配音,或给静态照片生成“说话”视频,要求易操作 | 使用Gradio可视化界面,无需命令行,上传图像/视频+音频即可一键生成 |
| 低代码二次开发 | AI开发者、技术团队 | 基于开源框架开发定制化工具(如企业级配音平台),要求接口灵活、可扩展 |
调用核心脚本generate_infinitetalk.py,通过参数配置自定义分辨率、时长、同步精度 |
典型场景示例
短视频创作者的“配音自由”:某创作者拍摄了一段美食制作视频,但原始音频嘈杂,想替换为清晰的讲解音频。使用InfiniteTalk的V2V模式,上传原视频和新讲解音频,一键生成“唇形、动作与新音频完全同步”的视频,无需手动调整,节省后期制作时间。
虚拟人主播直播:某直播平台需要一个虚拟人主播进行2小时的新闻播报,仅拥有虚拟人形象图和新闻文稿音频。通过InfiniteTalk的I2V模式,结合图像转视频脚本延长时长,启用TeaCache加速,实时生成“虚拟人说话+头部转动+表情变化”的直播视频,稳定性高且无需人工干预。
教育机构课件升级:某老师有一套静态PPT讲义,想制作成动态视频课程。使用InfiniteTalk的I2V模式,上传PPT每页图像和讲解音频,生成“图像动态切换+老师讲解同步动作”的课程视频,提升学生注意力。
五、使用方法
InfiniteTalk的使用流程分为“环境搭建→模型下载→推理生成”三步,支持命令行和Gradio可视化两种方式,以下详细说明每一步操作,确保非技术用户也能跟随操作:
1. 前置准备
硬件要求:GPU显存≥16GB(推荐24GB以上,支持720P生成);CPU≥8核;内存≥32GB;
操作系统:Windows/Linux(推荐Linux,兼容性更好);
依赖软件:Anaconda(Python环境管理)、Git(代码下载)、FFmpeg(视频处理)。
2. 环境搭建(以Linux为例)
步骤1:下载代码
git clone https://github.com/MeiGen-AI/InfiniteTalk.git cd InfiniteTalk
步骤2:创建并激活conda环境
conda create -n infinitetalk python=3.10 conda activate infinitetalk
步骤3:安装核心依赖
# 安装PyTorch、TorchVision、Torchaudio(CUDA 12.1版本) pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121 # 安装xformers(优化Transformer显存占用) pip install -U xformers==0.0.28 --index-url https://download.pytorch.org/whl/cu121 # 安装flash-attn(加速注意力计算) pip install misaki[en] pip install ninja psutil packaging wheel pip install flash_attn==2.7.4.post1 # 安装其他依赖 pip install -r requirements.txt # 安装音频处理库librosa和视频处理工具FFmpeg conda install -c conda-forge librosa conda install -c conda-forge ffmpeg # Linux用户;Windows用户可直接下载FFmpeg并配置环境变量
3. 模型下载
需通过Hugging Face CLI下载3个核心模型,确保网络通畅(若下载缓慢可配置HF镜像):
# 1. 基础模型(Wan2.1-I2V-14B-480P) huggingface-cli download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480P # 2. 音频编码器(chinese-wav2vec2-base) huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base huggingface-cli download TencentGameMate/chinese-wav2vec2-base model.safetensors --revision refs/pr/1 --local-dir ./weights/chinese-wav2vec2-base # 3. 音频条件权重(MeiGen-InfiniteTalk) huggingface-cli download MeiGen-AI/InfiniteTalk --local-dir ./weights/InfiniteTalk
4. 快速推理(常用场景示例)
场景1:单GPU生成480P长视频(I2V模式)
python generate_infinitetalk.py \ --ckpt_dir weights/Wan2.1-I2V-14B-480P \ # 基础模型路径 --wav2vec_dir 'weights/chinese-wav2vec2-base' \ # 音频编码器路径 --infinitetalk_dir weights/InfiniteTalk/single/infinitetalk.safetensors \ # 单人生成权重 --input_json examples/single_example_image.json \ # 输入配置(图像+音频路径) --size infinitetalk-480 \ # 分辨率480P --sample_steps 40 \ # 推理步数(默认40,质量最高) --mode streaming \ # 长视频模式 --motion_frame 9 \ # 运动帧数量(控制动作流畅度) --save_file infinitetalk_res # 输出文件名称
场景2:低显存设备运行(16GB显存)
python generate_infinitetalk.py \ --ckpt_dir weights/Wan2.1-I2V-14B-480P \ --wav2vec_dir 'weights/chinese-wav2vec2-base' \ --infinitetalk_dir weights/InfiniteTalk/single/infinitetalk.safetensors \ --input_json examples/single_example_image.json \ --size infinitetalk-480 \ --sample_steps 40 \ --num_persistent_param_in_dit 0 \ # 低显存关键参数 --mode streaming \ --motion_frame 9 \ --save_file infinitetalk_res_lowvram
场景3:720P高清生成(V2V模式)
python generate_infinitetalk.py \ --ckpt_dir weights/Wan2.1-I2V-14B-480P \ --wav2vec_dir 'weights/chinese-wav2vec2-base' \ --infinitetalk_dir weights/InfiniteTalk/single/infinitetalk.safetensors \ --input_json examples/single_example_video.json \ # 输入视频配置 --size infinitetalk-720 \ # 720P分辨率 --sample_steps 40 \ --mode streaming \ --motion_frame 9 \ --save_file infinitetalk_res_720p
场景4:Gradio可视化界面(非技术用户首选)
# 单人生成 python app.py \ --ckpt_dir weights/Wan2.1-I2V-14B-480P \ --wav2vec_dir 'weights/chinese-wav2vec2-base' \ --infinitetalk_dir weights/InfiniteTalk/single/infinitetalk.safetensors \ --num_persistent_param_in_dit 0 \ --motion_frame 9 # 多人生成 python app.py \ --ckpt_dir weights/Wan2.1-I2V-14B-480P \ --wav2vec_dir 'weights/chinese-wav2vec2-base' \ --infinitetalk_dir weights/InfiniteTalk/multi/infinitetalk.safetensors \ --num_persistent_param_in_dit 0 \ --motion_frame 9
运行后,浏览器访问http://localhost:7860,即可通过可视化界面上传图像/视频、音频,调整参数后一键生成视频,无需命令行操作。
5. 关键参数说明
| 参数名称 | 含义 | 推荐值 |
|---|---|---|
| --sample_audio_guide_scale | 音频引导强度(影响唇形同步精度) | 无LoRA:4;有LoRA:2 |
| --sample_text_guide_scale | 文本引导强度(若输入含文本描述) | 无LoRA:5;有LoRA:1 |
| --sample_steps | 推理步数(步数越多质量越高,速度越慢) | 高质量:40;快速生成:4-8(需LoRA) |
| --mode | 生成模式(streaming:长视频;clip:短视频单片段) | 长视频:streaming;短视频:clip |
| --quant | 量化模式(fp8/int8,减少显存占用) | 低显存:fp8;正常情况:不设置 |
| --lora_dir | FusionX/Lightx2v LoRA路径(加速推理) | 快速生成时配置对应LoRA文件路径 |
六、常见问题解答(FAQ)
1. 唇形同步效果不好怎么办?
解决方案:调整
--sample_audio_guide_scale参数(推荐3-5),参数越高同步精度越高;确保输入音频清晰无杂音(杂音会影响音频特征提取);若使用LoRA插件,将该参数调整为2。
2. 运行时显存不足报错(CUDA out of memory)?
解决方案:① 启用低显存参数
--num_persistent_param_in_dit 0;② 使用量化模型(添加--quant fp8和--quant_dir weights/InfiniteTalk/quant_models/infinitetalk_single_fp8.safetensors);③ 降低分辨率(从720P改为480P);④ 减少--motion_frame数值(如从9改为6)。
3. 长视频生成出现颜色偏移或人物“变脸”?
颜色偏移:避免使用FusionX LoRA(该插件会加剧长视频颜色偏移);I2V模式可使用“图像转视频脚本”(平移/缩放图像)增加帧间关联性;
人物变脸:确保参考图像/视频清晰,五官特征明显;调整
--sample_text_guide_scale参数(无LoRA时设为5),增强视觉特征锁定。
4. V2V模式中镜头运动与原始视频不一致?
解决方案:添加
--use_sdedit参数启用SDEdit工具,提升镜头运动一致性;该方法适合短片段(1分钟内),长片段可能出现颜色偏移,需权衡使用。
5. 多人动画生成时部分人物动作不同步?
解决方案:使用多人专用权重(
--infinitetalk_dir weights/InfiniteTalk/multi/infinitetalk.safetensors);确保输入图像中多个人物均清晰可见,无遮挡;调整--motion_frame 12增加运动帧数量,提升同步流畅度。
6. 推理速度太慢,生成1分钟视频需要半小时?
解决方案:启用FusionX/Lightx2v LoRA插件,将
--sample_steps设为8(FusionX)或4(Lightx2v),速度提升5-10倍;使用多GPU并行推理(参考“多GPU推理”命令);启用TeaCache加速(添加--use_teacache参数)。
7. Gradio界面无法打开或加载模型失败?
界面无法打开:检查端口7860是否被占用,可添加
--server_port 7861更换端口;确保所有依赖已安装(尤其是gradio、torch等核心库);模型加载失败:检查模型下载路径是否正确(需放在
./weights/目录下);确保模型文件下载完整(无缺失的.safetensors文件)。
8. 输入视频/音频格式有要求吗?
音频格式:支持wav、mp3格式,推荐采样率16kHz(与chinese-wav2vec2-base模型适配);
视频格式:支持mp4、avi格式,推荐分辨率与生成分辨率一致(480P/720P),避免拉伸失真;
图像格式:支持jpg、png格式,建议图像清晰、人物占比适中(避免过大或过小)。
七、相关链接
技术报告(arXiv):https://arxiv.org/abs/2508.14033
八、总结
InfiniteTalk是一款聚焦稀疏帧视频配音的开源音频驱动视频生成框架,以“全维度姿态同步、无限长度生成、高稳定性、灵活部署”为核心优势,支持图像到视频、视频到视频两种模式,可广泛应用于内容创作、影视制作、虚拟人、在线教育等多个领域。它通过wav2vec音频编码、CLIP视觉嵌入、DiT生成网络等技术,解决了传统配音工具仅关注唇形、时长受限、稳定性差等痛点,同时提供低显存优化、多GPU并行、量化模型、Gradio可视化界面等多种适配方案,兼顾技术开发者与非专业用户的使用需求。作为一款开源免费的工具,InfiniteTalk不仅提供了完整的代码、模型与教程,还支持社区二次开发与整合(如ComfyUI、Wan2GP),为视频生成领域提供了高效、精准、灵活的解决方案,推动音频驱动视频技术的普及与应用。
版权及免责申明:本文由@dotaai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/infinitetalk.html





