KTransformers:专注LLM异构优化的CPU-GPU混合推理与微调开源框架
KTransformers是什么?
KTransformers是一款基于CPU-GPU异构计算的开源框架,专注于大型语言模型(LLM)的高效推理与微调优化。项目核心包含kt-kernel(高性能推理内核)和kt-sft(轻量化微调框架)两大模块,通过AMX/AVX指令集加速、量化技术、MoE优化等核心技术,实现了资源高效利用——支持在有限硬件资源下部署超大规模模型,仅需70GB GPU内存即可微调671B参数的DeepSeek-V3。该框架兼容Intel Arc、AMD ROCm、Ascend NPU等多硬件平台,适配Kimi-K2、Qwen3-Next、DeepSeek系列等主流模型,广泛应用于生产级部署、科研实验、资源受限场景等,为大模型落地提供了灵活、高效的技术解决方案。
项目由清华大学MADSys实验室、Approaching.AI团队及社区贡献者联合开发维护,其核心目标是解决传统LLM推理与微调面临的两大关键痛点:一是超大规模模型(如百亿、千亿参数MoE模型)对硬件资源(尤其是GPU显存)的极致依赖,导致普通用户和中小企业难以部署;二是单一硬件(纯GPU或纯CPU)难以兼顾推理速度与成本控制的矛盾。通过CPU-GPU异构协同计算,KTransformers将模型的核心计算任务(如热点专家层、注意力机制)分配至GPU以保证速度,将非核心任务(如冷专家层、部分线性运算)卸载至CPU/内存甚至磁盘,实现“性能与成本的平衡”。
从项目演进来看,KTransformers保持了高频更新节奏(2024年8月至今持续迭代),逐步扩展了模型支持范围、硬件适配能力和核心优化技术,现已成为兼顾科研灵活性与生产实用性的LLM优化工具包,被用于MoE模型研究、大模型低成本部署、超大规模模型微调等多个场景。

功能特色
KTransformers的功能特色围绕“异构计算优化”核心,通过两大模块的协同配合,形成了“推理高效、微调轻量化、生态兼容、硬件适配广泛”的鲜明优势,具体可分为模块特色与整体特色两部分:
一、核心模块功能特色
1. kt-kernel:高性能推理内核,赋能异构计算
kt-kernel是KTransformers的推理核心,专注于CPU优化的内核操作设计,为LLM异构推理提供底层技术支撑,其核心特色如下:
多指令集加速,算力充分释放:深度优化Intel AMX、AVX512、AVX2等CPU指令集,针对INT4/INT8量化推理场景进行专项优化,同时支持GPU端FP8内核加速(如DeepSeek-V3/R1模型),让不同硬件的算力潜力得到充分发挥。
MoE模型专项优化:针对混合专家模型(MoE)的推理特点,采用NUMA-aware内存管理技术,支持“热点专家GPU部署、冷专家CPU卸载”的异构专家 placement 策略(如256个MoE专家中仅激活8个并部署于GPU),大幅降低MoE模型的显存占用。
全栈量化支持,兼顾速度与精度:覆盖CPU端INT4/INT8量化权重加载、GPU端GPTQ量化推理,在保证模型效果损失可控的前提下,进一步降低硬件资源消耗——例如将DeepseekV2的显存需求从21G降至11G。
生态无缝集成:提供简洁的Python API,可快速集成至SGLang等主流推理框架,支持生产级服务部署;同时兼容llamfile作为线性后端,扩展了框架的使用场景。
多硬件与跨平台兼容:适配Intel Arc GPU、AMD ROCm GPU、Ascend NPU等多种硬件,支持Windows原生运行(无需WSL),打破了硬件和操作系统的限制。
2. kt-sft:轻量化微调框架,降低大模型微调门槛
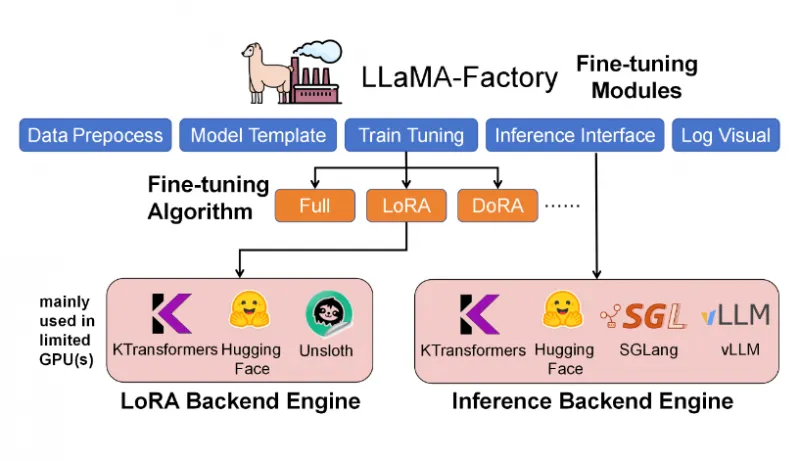
kt-sft是KTransformers的微调核心,通过与主流微调框架LLaMA-Factory深度集成,专注于超大规模MoE模型的高效微调,其核心特色如下:
极致资源高效:依托异构计算技术,实现“低显存、高吞吐量”的微调效果——仅需70GB GPU内存+1.3TB RAM即可微调671B参数的DeepSeek-V3模型,14B参数的DeepSeek-V2-Lite微调仅需6GB GPU内存,让普通实验室和中小企业也能开展超大规模模型微调。
丰富微调算法支持:主打LoRA(Low-Rank Adaptation)微调方案,同时支持DoRA等进阶算法,兼顾微调效果与训练效率;通过异构加速技术,让微调过程中的计算任务在CPU与GPU间合理分配,避免单一硬件瓶颈。
生态兼容与生产就绪:与LLaMA-Factory无缝集成,复用其成熟的数据预处理、模型模板、日志可视化等功能;支持对话生成、批量推理、指标评估等生产级场景,微调后的模型可直接用于实际部署。
高吞吐量优化:针对微调过程中的数据并行、计算调度进行专项优化,DeepSeek-V3(671B)微调吞吐量可达40 tokens/s,DeepSeek-V2-Lite(14B)更是达到530 tokens/s,大幅缩短微调周期。
二、项目整体功能特色
除两大核心模块外,KTransformers作为整体框架,还具备以下跨模块的综合优势:
模型支持广泛:已适配Kimi-K2(含Thinking版本)、Qwen3-Next、Qwen3MoE、DeepSeek-R1/V2/V3、GLM4-MoE、SmallThinker、LLaMA 4、mixtral 87B/822B等主流LLM,覆盖通用大模型、MoE模型等多个类别,用户可直接基于现有模型开展优化。
长上下文推理能力突出:通过3层(GPU-CPU-Disk)前缀缓存复用技术,突破显存限制——在24GB VRAM的单GPU上,可支持DeepSeek-V3/R1模型的139K长上下文推理,同时将部分模型的上下文长度从4K扩展至8K,满足长文本处理需求。
多并发与高性能:支持多并发推理(8-way concurrency),部分模型推理速度提升15%(最高可达16 Tokens/s);DeepSeek-R1-0528(FP8)在8×L20 GPU+Xeon Gold 6454S硬件上,总吞吐量达227.85 tokens/s,输出吞吐量87.58 tokens/s,满足高并发场景需求。
持续迭代与教程完善:保持高频更新,快速跟进主流模型与硬件的适配(如2025年11月支持Kimi-K2-Thinking推理与微调),提供中英文教程(含模型使用、硬件适配、生态集成),降低用户上手难度。
核心功能模块对比表
| 模块 | 核心定位 | 关键优势 | 典型应用场景 | 硬件依赖 |
|---|---|---|---|---|
| kt-kernel | 高性能异构推理内核 | 量化加速、MoE优化、生态集成 | 大模型低成本部署、高并发推理 | CPU+GPU/CPU/NPU(支持单一硬件) |
| kt-sft | 轻量化超大规模模型微调 | 低显存占用、高吞吐量、生态兼容 | 超大规模MoE模型微调、科研实验 | CPU+GPU(需协同工作) |
技术细节
KTransformers的核心技术围绕“CPU-GPU异构计算”展开,通过底层内核优化、资源调度策略、量化技术、微调架构设计等多个维度,实现LLM推理与微调的高效性,具体技术细节如下:
一、kt-kernel:推理内核的技术实现
1. CPU优化内核设计
kt-kernel的CPU内核针对LLM推理的核心算子(注意力机制、线性变换、KV缓存)进行了深度优化:
算子融合与指令集适配:将Layer Norm、Linear、KV Cache等操作进行算子融合,减少数据在CPU与内存间的传输开销;针对Intel AMX指令集优化INT8推理,AVX512/AVX2优化FP16/FP32计算,让每个算子都能匹配最优指令集。
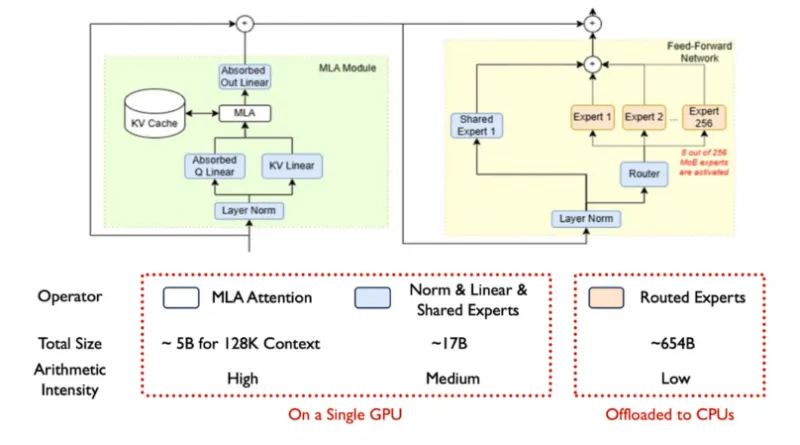
MLA模块集成:吸收MLA(Matrix Lookup Attention)模块,优化注意力机制的计算流程,在长上下文场景下提升计算效率——例如DeepSeek-R1/V3的139K上下文推理,正是依托MLA模块的高效计算能力。
KV Cache优化:采用“GPU-CPU-Disk”三层缓存架构,热点KV数据存储于GPU显存(低延迟),中高频数据存储于CPU内存,低频数据卸载至磁盘,通过缓存复用技术减少重复计算,同时降低显存占用。
2. MoE模型推理优化技术
MoE模型的核心挑战是“专家激活与内存管理”,kt-kernel通过以下技术解决:
NUMA-aware内存管理:针对多CPU节点服务器,采用NUMA(非统一内存访问)感知策略,将冷专家的权重数据存储于距离CPU核心更近的内存区域,减少跨节点内存访问延迟。
异构专家调度:通过路由器(Router)筛选激活的热点专家(如256选8),并将其部署于GPU显存;未激活的冷专家权重存储于CPU内存,推理时按需加载,大幅降低GPU显存占用——这也是MoE模型能在24GB VRAM上运行的关键。
3. 量化技术栈
KTransformers的量化技术覆盖“权重量化”与“计算量化”,兼顾速度与精度:
CPU端量化:支持INT4/INT8权重量化存储,加载时直接以量化格式参与计算,减少内存占用与数据传输开销;
GPU端量化:兼容GPTQ量化方案,针对GPU架构优化量化计算流程,避免量化/反量化过程中的性能损耗;
混合量化策略:支持IQ1_S/FP8混合权重格式,根据不同层的计算特性选择最优量化精度,在推理速度与模型效果间取得平衡。
二、kt-sft:微调框架的技术实现
1. 异构微调架构
kt-sft的核心技术是“异构计算与LoRA结合”,其架构设计如下:
计算任务拆分:将LoRA微调中的核心计算(如低秩矩阵更新、注意力机制计算)分配至GPU,非核心计算(如数据预处理、部分线性变换)卸载至CPU,充分利用双端算力;
内存优化策略:采用“权重卸载+梯度累积”技术,超大规模模型的权重存储于CPU内存/磁盘,仅将当前计算所需的层加载至GPU显存,同时通过梯度累积减少显存占用,实现671B模型的低显存微调。
2. LoRA/DoRA微调优化
全LoRA支持:支持对模型所有层(包括注意力层、Feed-Forward层)进行LoRA微调,而非仅局限于部分层,保证微调效果;
DoRA适配:兼容DoRA(Dominant Eigenvector Rotation)算法,通过旋转低秩矩阵提升微调效率,减少微调数据量需求;
异构加速:LoRA的低秩矩阵计算在GPU上完成,而原始模型权重的存储与读取在CPU内存中进行,避免GPU显存被海量权重占用。
三、关键性能指标表
| 模型名称 | 硬件/配置 | 核心指标 | 数值 |
|---|---|---|---|
| DeepSeek-R1-0528(FP8) | 8×L20 GPU + Xeon Gold 6454S | 总吞吐量 | 227.85 tokens/s |
| DeepSeek-R1-0528(FP8) | 8×L20 GPU + Xeon Gold 6454S | 输出吞吐量(8路并发) | 87.58 tokens/s |
| DeepSeek-V3(671B) | LoRA + AMX + 多GPU | 微调吞吐量 | ~40 tokens/s |
| DeepSeek-V3(671B) | LoRA + AMX + 多GPU | 所需GPU内存 | 70GB |
| DeepSeek-V2-Lite(14B) | LoRA + AMX | 微调吞吐量 | ~530 tokens/s |
| DeepSeek-V2-Lite(14B) | LoRA + AMX | 所需GPU内存 | 6GB |
| DeepseekV2 | 单GPU(24GB VRAM) | 显存占用优化(原/现) | 21G / 11G |
| DeepSeek-R1/V3 | 单GPU(24GB VRAM) | 支持最大上下文长度 | 139K |
应用场景
KTransformers基于其“异构计算、低资源需求、广泛兼容”的技术特点,已在多个场景中得到实用,具体包括:
一、生产级大模型部署
适用场景:企业级LLM服务部署(如智能客服、内容生成、API服务),需要兼顾高并发、低延迟与成本控制;
核心价值:通过CPU-GPU异构推理,降低GPU显存依赖,减少硬件采购成本;支持SGLang集成与多并发处理,满足生产环境的高吞吐量需求;例如,电商平台的智能客服机器人,可基于KTransformers部署Kimi-K2模型,在24GB GPU上实现高并发对话响应,同时通过CPU卸载降低GPU负载。
二、超大规模MoE模型微调
适用场景:科研机构、AI企业对千亿参数MoE模型(如DeepSeek-V3 671B)进行微调,适配特定任务(如专业领域问答、代码生成);
核心价值:仅需70GB GPU内存即可完成千亿模型微调,无需天价GPU集群;与LLaMA-Factory集成,提供成熟的微调流程与可视化工具,降低科研门槛;例如,高校实验室针对医疗领域的问答任务,微调DeepSeek-V3模型时,可通过kt-sft在普通多GPU服务器上完成,无需依赖超级计算中心。
三、资源受限环境下的LLM应用
适用场景:中小企业、个人开发者在低显存GPU(如6GB、12GB VRAM)或无GPU环境下,运行中大型LLM;
核心价值:支持CPU单硬件推理、GPU-CPU混合推理,将模型部分层卸载至CPU/磁盘,让14B甚至更大模型在6GB GPU上运行;例如,个人开发者基于DeepSeek-V2-Lite模型开发本地AI写作工具,通过kt-kernel将冷专家层卸载至CPU,仅用6GB GPU即可实现流畅的文本生成。
四、多硬件异构集群部署
适用场景:已有CPU服务器集群+少量GPU的企业,希望充分利用现有硬件资源部署LLM;
核心价值:支持Intel Arc、AMD ROCm、Ascend NPU等多种硬件混合组网,将不同硬件的算力整合为统一计算资源;例如,某制造企业已有Xeon CPU服务器集群,新增少量Ascend NPU,通过KTransformers实现“CPU卸载冷数据、NPU处理核心计算”的部署模式,无需替换现有硬件即可落地LLM质检、设备维护问答等场景。
五、LLM优化技术科研实验
适用场景:研究人员开展量化推理、MoE优化、异构计算调度等LLM相关技术研究;
核心价值:模块化设计让科研人员可聚焦特定技术点(如自定义量化算法、MoE调度策略),无需从零搭建框架;支持多种模型与硬件,便于对比实验;例如,研究人员测试新型INT4量化算法时,可基于kt-kernel快速集成,在Qwen3-Next模型上验证效果,同时对比CPU与GPU混合部署的性能差异。
使用方法
一、环境准备
操作系统:支持Windows(原生)、Linux(Ubuntu/CentOS等);
硬件要求:CPU需支持AVX2及以上指令集(Intel CPU建议支持AMX,优化效果更佳);GPU支持NVIDIA CUDA、AMD ROCm、Intel Arc、Ascend NPU(可选,纯CPU也可运行基础功能);
依赖安装:Python 3.8+,建议使用虚拟环境(如conda)安装依赖,具体依赖项可参考各模块的README文件。
二、kt-kernel:快速启动推理
1. 安装步骤
# 克隆仓库 git clone https://github.com/kvcache-ai/ktransformers.git cd ktransformers # 进入kt-kernel目录 cd kt-kernel # 安装依赖与模块 pip install .
2. 基础使用示例
kt-kernel提供Python API,可快速集成至推理流程,以下是简化示例(完整示例参考官方教程):
from kt_kernel import KtKernel # 初始化内核(指定模型、量化方式、硬件配置) kernel = KtKernel( model_name="deepseek-ai/DeepSeek-R1", quant_type="int8", # 支持int4/int8/fp8等 device="cuda:0", # 支持cuda/npu/cpu cpu_offload=True # 开启CPU卸载 ) # 推理生成 prompt = "请介绍CPU-GPU异构计算的优势" output = kernel.generate(prompt, max_new_tokens=200, temperature=0.7) print(output)
3. 关键配置说明
quant_type:指定量化类型,可选int4/int8/fp8/gptq,根据硬件与模型支持情况选择;cpu_offload:是否开启CPU卸载,建议在GPU显存不足时启用;n_ctx:设置上下文长度,如139000(需模型支持),需结合硬件内存调整。
三、kt-sft:快速启动微调
1. 安装步骤
# 克隆仓库(若已克隆可跳过) git clone https://github.com/kvcache-ai/ktransformers.git cd ktransformers # 进入kt-sft目录 cd kt-sft # 安装依赖(参考kt-sft/README.md) pip install -r requirements.txt # 安装LLaMA-Factory(已集成,无需单独克隆) pip install llamafactory
2. 微调启动命令
kt-sft与LLaMA-Factory深度集成,通过环境变量USE_KT=1启用KTransformers的异构加速,示例如下:
# 基于LoRA微调DeepSeek-V3模型(配置文件路径参考官方示例) USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
3. 配置文件关键参数(deepseek3_lora_sft_kt.yaml)
model_name_or_path: deepseek-ai/DeepSeek-V3 lora_target_modules: ["q_proj", "v_proj", "k_proj", "o_proj"] # LoRA目标层 lora_rank: 8 # LoRA低秩矩阵维度 lora_alpha: 16 batch_size: 8 gradient_accumulation_steps: 4 max_seq_length: 8192 use_kt: true # 启用KTransformers异构加速 cpu_offload: true # 开启CPU卸载 quantization_bit: 8 # 量化精度(可选)
4. 微调结果导出与部署
微调完成后,可通过LLaMA-Factory的导出命令将LoRA权重与原始模型合并,或直接用于推理:
# 导出合并后的模型 USE_KT=1 llamafactory-cli export examples/export/deepseek3_export_kt.yaml
四、关键教程参考
官方提供了针对不同模型、硬件的详细教程,用户可根据需求查阅:
Kimi-K2-Thinking推理与微调教程:项目文档中“Updates”部分关联链接;
Ascend NPU适配教程:doc/DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md;
Intel Arc GPU使用教程:项目“Updates”中2025年5月14日关联链接;
SGLang集成教程:项目“Updates”中2025年10月10日关联链接;
旧版本完整教程:archive/README.md(英文)、archive/README_ZH.md(中文)。
五、目录结构导航
ktransformers/ ├── .github/ # 项目配置(issue模板等) ├── archive/ # 旧版本代码与文档(归档) ├── doc/ # 教程与文档(含多语言) ├── kt-kernel/ # 推理内核模块(核心代码、安装脚本) ├── kt-sft/ # 微调框架模块(配置示例、Python接口) ├── third_party/ # 第三方依赖(如llamafactory) ├── README.md # 英文主文档 ├── README_ZH.md # 中文主文档 └── book.toml # 在线文档配置
常见问题解答(FAQ)
1. KTransformers与vLLM、SGLang等推理框架的核心区别是什么?
答:核心区别在于“异构计算优化”的定位——vLLM、SGLang主要聚焦纯GPU推理优化(通过PagedAttention等技术提升GPU利用率),而KTransformers专注于CPU-GPU混合计算,核心目标是降低GPU显存依赖,支持超大规模模型在有限硬件资源下运行;此外,KTransformers还集成了微调模块(kt-sft),而vLLM、SGLang仅聚焦推理。若需纯GPU高并发推理,可选择vLLM;若需低显存部署、MoE模型优化或超大规模模型微调,KTransformers更具优势。
2. 如何选择kt-kernel和kt-sft模块?
答:根据使用场景选择:① 若仅需运行大模型(推理生成、API服务),仅需使用kt-kernel;② 若需对模型进行微调(适配特定任务、优化模型效果),需使用kt-sft(依赖kt-kernel的底层支持);③ 生产环境中“微调+部署”联动,可同时使用两大模块,微调后的模型直接通过kt-kernel部署。
3. KTransformers支持哪些模型?是否需要手动适配新模型?
答:已支持Kimi-K2(含Thinking)、Qwen3-Next、Qwen3MoE、DeepSeek-R1/V2/V3、GLM4-MoE、SmallThinker、LLaMA 4、mixtral 87B/822B等主流模型。对于新模型,若其结构与已支持模型(如LLaMA系列、DeepSeek系列)兼容,可直接通过配置文件指定模型路径使用;若结构差异较大,可能需要修改模型模板(参考LLaMA-Factory的模型适配逻辑),或提交issue请求社区支持。
4. 纯CPU环境下能否使用KTransformers?性能如何?
答:支持纯CPU运行(kt-kernel模块),但性能取决于CPU的指令集支持(建议使用支持AMX/AVX512的Intel CPU)。纯CPU环境适合小规模模型(如7B/14B非MoE模型)或低并发场景,推理速度会低于GPU,但通过量化优化(如INT8)和KV缓存复用,可满足基础使用需求(如本地文本生成、小规模问答)。
5. 微调超大规模模型时,内存不足(OOM)怎么办?
答:可通过以下方式解决:① 开启CPU卸载(cpu_offload: true),将模型权重存储于CPU内存/磁盘;② 降低lora_rank(如从16降至8),减少LoRA矩阵的显存占用;③ 增加gradient_accumulation_steps(如从4增至8),减少单次迭代的显存使用;④ 采用量化微调(quantization_bit: 8),降低模型权重的内存占用;⑤ 拆分数据集为更小的批次(减小batch_size)。
6. 如何将KTransformers集成到现有生产系统?
答:有两种方式:① 基于kt-kernel的Python API,直接集成至现有Python服务(如FastAPI、Flask),提供HTTP接口;② 借助SGLang集成能力,通过SGLang的生产级服务框架(如支持负载均衡、动态扩缩容)部署,KTransformers作为底层推理内核;③ 对于需要OpenAI/Ollama兼容API的场景,可结合第三方工具(如text-generation-inference)进行适配。
7. Windows系统下使用需要注意什么?
答:KTransformers支持Windows原生运行,无需WSL,注意以下几点:① 安装依赖时确保适配Windows版本(如PyTorch需下载Windows版本);② GPU支持方面,Windows下优先选择NVIDIA CUDA GPU,AMD ROCm、Intel Arc的Windows适配需参考官方教程;③ 纯CPU运行时,确保CPU支持AVX2及以上指令集(可通过CPU-Z等工具查询);④ 长路径文件可能导致报错,建议将仓库克隆至根目录(如D:\ktransformers)。
相关链接
项目GitHub仓库:https://github.com/kvcache-ai/ktransformers
总结
KTransformers是一款以CPU-GPU异构计算为核心的LLM高效推理与微调开源框架,通过kt-kernel(高性能推理内核)与kt-sft(轻量化微调框架)两大模块的协同,解决了超大规模模型部署显存门槛高、微调资源需求大、多硬件适配难等关键痛点。其核心优势在于深度优化的异构计算调度、全栈量化技术、MoE模型专项支持以及与主流生态(SGLang、LLaMA-Factory)的无缝集成,可在有限硬件资源下实现千亿参数模型的推理与微调,同时兼容多种CPU、GPU、NPU硬件及Windows、Linux操作系统。无论是企业级生产部署、科研机构的技术实验,还是中小企业、个人开发者的低成本LLM应用落地,KTransformers都提供了灵活、高效、易上手的解决方案,成为连接大模型技术与实际应用的重要桥梁。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/ktransformers.html





