什么是上下文工程(Context Engineering)?一文理解其定义与作用
上下文工程是AI应用从提示工程演进而来的核心方法论。本文AI铺子系统解析上下文工程的定义、与提示工程的区别、核心技术方法及其在实际AI系统中的关键作用,帮助开发者理解...

上下文工程是AI应用从提示工程演进而来的核心方法论。本文AI铺子系统解析上下文工程的定义、与提示工程的区别、核心技术方法及其在实际AI系统中的关键作用,帮助开发者理解...

GPT-5.6 vs GPT-5.5 全面对比:上下文窗口从105万扩至150万Token,新增Max/Ultra双推理模式,旗舰性能超越GPT-5.5且价格持平。一文看懂Sol/Terra/Luna三款模型的核心升级。

GPT-5.6是OpenAI最新发布的新一代大语言模型产品线,是GPT-5代系的最新迭代版本,全线分为Sol(旗舰)、Terra(均衡)、Luna(轻量) 三款分层模型,重构原有GPT-5.5单一版...

GLM-5.2是智谱AI最新推出的GLM-5系列第三代旗舰文本大模型,定位为百万长上下文+工程Agent专用开源底座,是当前智谱全系综合能力最强、开放程度最高的大语言模型。

Claude Opus 4.8 是由美国人工智能公司 Anthropic 发布的 Claude 4系列旗舰大语言模型,是Opus 4.7的迭代优化版本,定位为面向企业级复杂任务与专业场景的全能型AI模型。该...

Qwen3.7-Max(通义千问3.7-Max)是阿里巴巴于2026年5月20日在阿里云峰会上正式发布的新一代旗舰级大语言模型,隶属通义千问(Qwen)系列,定位为面向智能体(Agent)时代的...

Claude Mythos Preview是Anthropic公司发布的最高层级通用前沿大语言模型,内部代号Capybara,命名取自希腊语“叙述/话语”,象征对复杂世界的系统性理解与表达。它独立于现...

Qwen3.6-Plus是阿里云通义实验室发布的Qwen 3.6系列旗舰大语言模型,也是继Qwen 3.5系列后的新一代核心产品。官方将其定位为"当下编程能力最强的国产模型",在多项权威编程...

GPT-5.4 mini是OpenAI发布的轻量级高性能大语言模型,以更低成本、更快速度提供接近旗舰GPT-5.4的核心能力,支持多模态理解、函数调用、网页搜索、文件检索、计算机操控等,...

AgentScope Java是由阿里巴巴通义实验室开源的企业级AI智能体编程框架,面向Java 17+技术栈,提供ReAct推理、工具调用、记忆管理、多智能体协作、安全沙箱、可观测性等全栈...

TeleChat3 是中国电信人工智能研究院依托全国产算力研发的开源大语言模型(LLM)项目,聚焦 TeleChat3 系列模型(105B-A4.7B-Thinking、36B-Thinking)的推理、微调、国产化...

IQuest-Coder-V1是一套专注于代码生成、代码理解与软件工程全流程任务的开源大语言模型系列,由国内量化私募头部机构九坤投资旗下至知创新研究院独立开发并开源。作为聚焦垂...

MiMo-V2-Flash 是小米公司开源的千亿级混合专家(MoE)架构语言模型,总参数规模达3090亿,活跃参数仅150亿,实现了高性能与低推理成本的平衡。该模型创新采用混合注意力架...
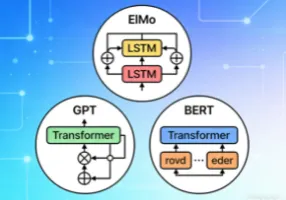
2018年前后,ELMo、GPT和BERT三大模型相继问世,分别代表了预训练语言模型的三个重要技术分支,彻底改变了传统NLP任务依赖人工设计特征和特定任务模型的局面。本文AI铺子将...

KTransformers是一款基于CPU-GPU异构计算的开源框架,专注于大型语言模型(LLM)的高效推理与微调优化。项目核心包含kt-kernel(高性能推理内核)和kt-sft(轻量化微调框架...