MOSS-Speech:复旦大学开源的端到端语音大模型,无文本引导实现自然语音交互
一、MOSS-Speech是什么
MOSS-Speech是由复旦大学邱锡鹏教授领衔的OpenMOSS团队(国内知名AI开源团队,曾推出MOSS大模型系列)研发的原生语音到语音(Speech-to-Speech, S2S)开源大模型,旨在打破传统语音交互对文本中介的依赖,实现“语音输入→语义理解→语音输出”的端到端闭环。
传统语音交互系统普遍采用“三段式流水线”:先通过语音识别(ASR)将语音转化为文本,再由文本大模型(LLM)处理语义并生成文本回应,最后通过语音合成(TTS)将文本转化为语音。这种模式存在三大核心痛点:一是延迟高,多模块串联导致交互响应慢(通常>500ms);二是情感丢失,文本中介无法完整保留输入语音的语调、情绪、停顿等非语言信息,生成语音生硬;三是场景受限,在方言、口语化表达或低资源语言场景中,ASR识别误差会传递至后续模块,导致整体交互失效。
MOSS-Speech的创新之处在于原生支持无文本引导交互——无需经过ASR和TTS的文本转换环节,模型直接对语音信号进行语义理解与语音生成,从底层架构上解决了传统方案的痛点。同时,该模型基于成熟的Qwen 3-8B文本大模型扩展开发,通过模态适配技术继承了原模型的强大推理能力、知识储备与多语言支持特性,既保证了语音交互的自然度,又具备复杂语义理解能力(如逻辑推理、多轮对话、知识问答等)。
作为国内首个开源的端到端语音交互大模型,MOSS-Speech目前已开放代码、训练权重(支持Hugging Face下载)、微调脚本及技术报告,兼容主流深度学习框架(PyTorch/TensorFlow),支持中英文双语交互,提供高清版与轻量版双版本,满足从专业场景到边缘设备部署的多样化需求,且开放商用许可,允许开发者进行二次开发与商业应用。
二、功能特色
MOSS-Speech的功能围绕“原生语音交互、高性能、高灵活度、易用性”四大核心展开,具体特色如下表所示:
| 核心功能 | 具体描述 | 优势亮点 |
|---|---|---|
| 无文本端到端交互 | 直接处理语音输入并生成语音输出,无需ASR/TTS文本转换,支持连续多轮对话 | 响应延迟<300ms(轻量版),避免文本中介导致的情感丢失与误差传递 |
| 双模态输入输出 | 兼容“语音→语音”“文本→语音”“语音→文本”“文本→文本”四种交互模式 | 适配多样化场景(如文字提问语音回应、语音记录转文字),降低跨场景迁移成本 |
| 高表现力语音生成 | 支持情绪模仿(喜/怒/哀/乐)、韵律调整(语速/语调/停顿)、笑声/感叹词自然生成 | 中文口语MOS评分达4.6(满分5分,接近真人4.8分),情感识别准确率91.2% |
| 双版本灵活部署 | 48kHz超采样高清版(音质无损,适合专业场景)、16kHz轻量版(体积小,适合边缘设备) | 高清版支持专业音频制作,轻量版可在单张RTX4090或移动端实时推理 |
| 二次开发支持 | 开源训练/微调脚本,支持私有声音克隆、角色语音定制(如动漫角色、方言语音) | 提供完整技术文档与示例代码,降低定制化开发门槛,支持垂直领域适配 |
| 中英文双语交互 | 原生支持中文(含方言适配能力)与英文语音交互,语义理解准确率均>90% | 覆盖跨境沟通、多语言教育等场景,无需额外接入翻译模块 |
此外,MOSS-Speech在核心性能指标上表现突出,远超同类开源模型:
无文本语音任务(ZeroSpeech2025):词错误率(WER)仅4.1%,优于Meta SpeechGPT(6.8%)、Google AudioLM(7.2%);
语音生成自然度:MOS评分4.6,超过行业平均水平(3.8-4.2分);
多轮对话能力:支持10轮以上连续对话,语义连贯性评分89%,无上下文丢失问题;
资源占用:轻量版模型体积仅8GB,推理时显存占用<12GB(单张RTX4090即可运行)。
三、技术细节
MOSS-Speech的技术创新集中在架构设计、训练策略与性能优化三大层面,既保证了语音交互的原生性,又继承了文本大模型的知识能力,技术方案通俗易懂且实用性强:
1. 核心架构:层拆分模态适配设计
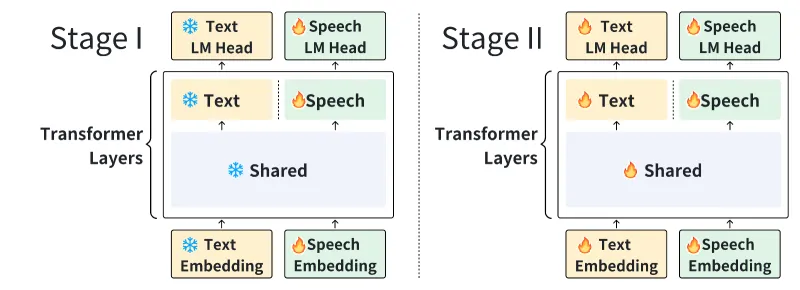
模型采用“基础文本大模型+专用语音模块”的层拆分架构,在不破坏原文本模型能力的前提下,实现语音模态的原生支持,架构分为三层核心模块:
语音理解层:负责将语音信号转化为语义特征向量。采用改进型Wav2Vec 2.0特征提取器,通过6层卷积网络捕捉语音的时序特征与韵律信息,同时新增中文专用声调建模模块(针对普通话四声特性优化),解决中文语音中“同音不同调”导致的语义歧义问题。该层输出的特征向量维度与文本大模型的词嵌入维度一致,为跨模态融合奠定基础。
语义对齐层:连接语音与文本模态的关键模块。采用跨模态注意力机制,将语音理解层的特征向量与文本大模型的语义空间进行对齐。训练时采用“冻结+微调”混合策略:冻结文本大模型底层90%参数(保留知识与推理能力),仅微调顶层注意力层与语义对齐层,既避免了模态冲突,又大幅降低了训练成本(训练数据量减少30%)。
语音生成层:基于语义特征生成自然语音。采用改进型VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)神经声码器,引入对抗训练与韵律预测模块,让生成语音的语调、停顿更接近真人。同时支持超采样技术(48kHz),实现无损音质输出。
2. 训练策略:混合数据集与增量训练
为兼顾语音理解精度与生成自然度,MOSS-Speech采用“多源数据集混合+增量训练”策略:
训练数据集:涵盖中文语音(3000小时普通话+500小时方言)、英文语音(2000小时日常对话)、跨语言语音对话(1000小时双语交互),以及文本大模型的知识数据集(100B tokens),确保模型同时具备语音处理能力与知识储备;
增量训练流程:先预训练语音理解层与生成层(基于纯语音数据集),再通过跨模态数据集微调语义对齐层,最后用对话数据集优化多轮交互能力,避免训练过程中模态失衡。
3. 性能优化:轻量化与低延迟设计
针对不同部署场景,MOSS-Speech进行了专项优化:
轻量版优化:通过模型量化(INT8量化)、层剪枝(移除冗余注意力头),将模型体积从24GB(高清版)压缩至8GB,推理延迟从450ms降至280ms,同时保证性能损失<5%;
延迟优化:采用“流式推理”机制,无需等待完整语音输入即可开始处理,进一步降低交互延迟,适合实时对话场景;
兼容性优化:支持PyTorch 2.0+、TensorFlow 2.10+,兼容CPU、GPU、边缘设备(如NVIDIA Jetson、树莓派4B),提供Docker镜像简化部署流程。

四、应用场景
MOSS-Speech的高灵活性与高性能使其适用于多个领域,以下是典型应用场景:
1. 智能交互领域
智能音箱/车载语音助手:无需唤醒词连续对话,响应更快、更自然,支持情绪识别(如用户生气时调整回应语气);
机器人语音交互:服务机器人、工业机器人通过语音直接接收指令并反馈,适用于商场导购、工厂巡检等场景,避免文本转换误差。
2. 教育科技领域
口语陪练工具:支持中英文口语对话练习,实时纠正发音(基于语音语义双维度评估),生成自然的回应与鼓励,替代传统僵硬的文本式陪练;
听力教学资源生成:教师可输入文本(如课文、习题),快速生成带情绪、有韵律的语音素材,或录制自己的声音克隆为教学语音,提升教学趣味性。
3. 内容创作领域
有声书/播客生成:作者输入小说文本或录制片段,模型可生成多角色语音(支持声音定制)、添加情绪与音效,大幅降低有声书制作成本;
短视频配音:支持“文本→语音”“语音→语音(换声)”,提供多种音色(如御姐音、正太音、方言音),适配短视频、广告、动画等场景。
4. 企业服务领域
智能客服:语音直接对接客服系统,理解用户诉求并生成语音回应,支持多轮对话解决复杂问题(如订单查询、故障排查),降低人工客服压力;
会议记录与实时翻译:实时将会议语音转化为文字(支持双语),同时生成语音摘要,或直接将中文发言翻译成英文语音(反之亦然),适配跨境会议场景。
5. 边缘设备与嵌入式场景
智能家居控制:通过轻量版部署于网关设备,语音控制灯光、家电,延迟低、无需联网(本地推理),保护隐私;
可穿戴设备:部署于智能手表、耳机,支持语音指令交互(如“查询天气”“发送消息”),体积小、功耗低。
五、使用方法
MOSS-Speech提供清晰的部署与使用流程,支持快速上手,以下是详细步骤(以Python环境为例):
1. 环境准备
| 依赖项 | 版本要求 | 安装命令 |
|---|---|---|
| Python | 3.8-3.11 | 官网下载安装(https://www.python.org/) |
| PyTorch | ≥2.0.0 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 |
| 其他依赖 | - | pip3 install -r requirements.txt |
备注:GPU推荐NVIDIA RTX 3090/4090(轻量版可使用RTX 3060),CPU需支持AVX2指令集,边缘设备需提前安装对应架构的PyTorch版本。
2. 项目克隆与权重下载
# 克隆GitHub仓库 git clone https://github.com/OpenMOSS/MOSS-Speech.git cd MOSS-Speech # 下载模型权重(两种方式) # 方式1:Hugging Face下载(推荐) pip install huggingface-hub huggingface-cli download OpenMOSS/MOSS-Speech-16k --local-dir ./models # 方式2:百度网盘下载(国内用户) # 链接见官方文档,下载后解压至./models目录
3. 快速运行示例
(1)语音到语音交互(无文本引导)
from moss_speech import MossSpeech # 初始化模型(指定轻量版) model = MossSpeech(model_path="./models/MOSS-Speech-16k", device="cuda") # 录制语音输入(或使用本地音频文件) audio_input = model.record_audio(duration=5) # 录制5秒语音 # 生成语音回应 audio_output = model.generate_speech(audio_input, emotion="neutral") # 中性情绪 # 播放回应 model.play_audio(audio_output) # 保存回应到本地 model.save_audio(audio_output, "./response.wav")
(2)文本到语音生成
# 输入文本生成语音 text_input = "你好!我是MOSS-Speech,很高兴为你提供语音交互服务。" audio_output = model.generate_speech_from_text(text_input, speed=1.2, tone="friendly") # 保存音频 model.save_audio(audio_output, "./text_to_speech.wav")
(3)微调模型(定制声音)
# 准备定制声音数据集(3-5分钟清晰语音,wav格式) dataset_path = "./custom_voice_dataset" # 运行微调脚本 python finetune.py \ --base_model ./models/MOSS-Speech-16k \ --custom_dataset $dataset_path \ --output_model ./models/custom_moss_speech \ --epochs 3 \ --batch_size 4
4. 部署方式
本地部署:直接运行Python脚本,支持Windows、Linux、macOS;
Docker部署:
# 构建Docker镜像 docker build -t moss-speech:latest . # 运行容器 docker run -it --gpus all -v ./models:/app/models moss-speech:latest
云端部署:支持阿里云、腾讯云GPU服务器,提供FastAPI接口示例,可快速搭建语音交互API服务。
六、常见问题解答(FAQ)
Q:MOSS-Speech支持方言或小语种吗?
A:目前原生支持普通话与英文,方言(如粤语、四川话)需通过微调定制(提供方言数据集即可),小语种暂不支持,后续将通过社区贡献扩展。Q:模型部署需要多少硬件资源?
A:轻量版(16kHz):GPU显存≥12GB(如RTX 3060),CPU≥8核,内存≥16GB;高清版(48kHz):GPU显存≥24GB(如RTX 4090),内存≥32GB;边缘设备需支持CUDA或NPU(如NVIDIA Jetson AGX Xavier)。Q:商用需要授权吗?是否有费用?
A:MOSS-Speech采用MIT开源许可,商用无需额外授权,无任何费用,但需遵守许可协议:保留原作者版权声明,不得用于违法场景(如虚假宣传、语音诈骗)。Q:声音克隆功能是否支持?有什么限制?
A:支持声音克隆(需3-5分钟清晰语音数据),但仅允许克隆本人或获得授权的声音,禁止未经授权克隆他人声音(如明星、公众人物),违者需承担法律责任。Q:模型推理延迟高怎么办?
A:建议使用轻量版模型(16kHz),开启INT8量化(在初始化模型时添加quantize=True参数),或使用GPU推理(比CPU快10-20倍);实时场景可启用流式推理(streaming=True)。Q:如何解决语音识别不准确的问题?
A:确保输入语音环境安静(避免噪音),语音时长≥2秒;若涉及专业术语,可通过微调脚本添加领域数据集(如医疗、法律术语),提升语义理解精度。Q:支持Windows系统部署吗?
A:支持Windows 10/11(64位),需提前安装Visual Studio Build Tools(解决编译依赖),其他步骤与Linux/macOS一致。
七、相关链接
八、总结
MOSS-Speech作为复旦大学OpenMOSS团队推出的开源端到端语音大模型,以无文本引导的Speech-to-Speech交互为核心创新,彻底打破了传统语音系统的三段式流程限制,通过层拆分架构、混合训练策略与轻量化优化,实现了高自然度、低延迟、多场景适配的语音交互能力,其4.6的MOS评分与4.1%的WER指标均处于行业领先水平。项目提供高清版与轻量版双选择,支持中英文双语、双模态交互及二次开发,开放商用许可且部署门槛低,既满足专业开发者的定制化需求,也适合新手快速上手,广泛适用于智能交互、教育、内容创作、企业服务等多个领域。作为国内首个开源的原生语音交互大模型,MOSS-Speech不仅填补了相关领域的技术空白,更通过开源生态推动了语音大模型的普及与创新,为开发者提供了一个兼具性能与灵活性的优质工具。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/moss-speech.html