Qwen3-TTS:通义千问开源的AI语音合成模型,实现多语种语音生成与定制化音色创作
一、Qwen3-TTS是什么
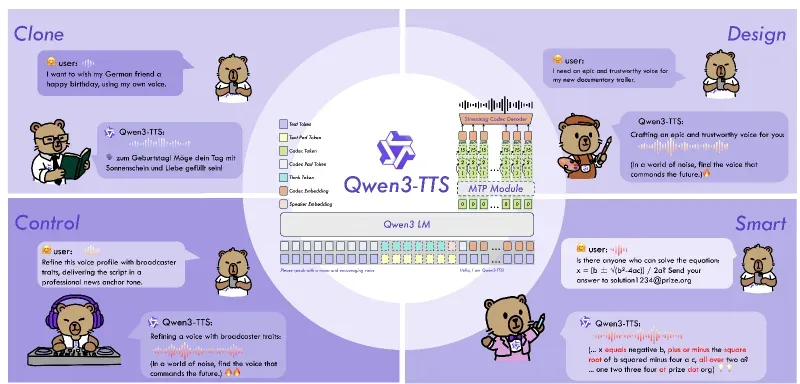
Qwen3-TTS是阿里云通义千问团队开源的一站式多语言语音生成模型全家桶,基于自研Qwen3大模型体系构建,采用离散多码本LM架构与Dual-Track双轨流式生成技术,实现语音克隆、语音设计、超高音质拟人化合成、自然语言指令控制、超低延迟流式输出五大核心能力,覆盖10大主流语言与多种方言,是当前开源生态中功能最全面、性能领先的语音合成解决方案之一。
项目定位为全能力语音生成平台,既支持普通用户通过Web UI快速体验音色克隆与定制,也为开发者提供完整的Python SDK、API接口、微调脚本与部署方案,可无缝集成到智能助手、内容创作、车载交互、教育学习等场景,实现“文本→高保真语音”的端到端生成。

二、功能特色
2.1 多语言与方言全覆盖
支持10大核心语言:中文、英文、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语;
内置8种中国方言:粤语、四川话、上海话、闽南语、陕西话、天津话、东北话、河南话;
多语种评测表现优异:在MiniMax TTS Multilingual Test Set上,平均词错误率(WER)优于MiniMax、ElevenLabs及GPT-4o-Audio-Preview。
2.2 三大核心语音能力
(1)极速语音克隆(3秒起步)
仅需3秒参考音频即可完成音色克隆,支持跨语言克隆(如用中文音频克隆后生成英文/日语语音);
克隆音色相似度高,声纹保留度达0.95,可完美复刻真人音色特征;
支持批量克隆与音色持久化存储,方便多轮对话与长文本生成复用。
(2)自然语言语音设计
支持自由文本指令定义音色:如“沉稳的中年男性播音员,音色低沉浑厚,富有磁性,语速平稳,适合新闻播报”“16岁少女音,声音甜美,语速轻快,带点小俏皮”;
可精细化控制音色、情感、韵律、语速、语调、人设等多维属性,实现“所想即所听”;
在InstructTTS-Eval评测中,综合表现显著优于GPT-4o-mini-tts、Mimo-audio-7b-instruct,角色扮演场景超越Gemini-2.5-pro-preview-tts。
(3)预设音色与风格控制
内置9种优质预设音色,覆盖性别、年龄、语言、方言、场景(如新闻播报、客服、儿童、情感朗读);
1.7B-CustomVoice版本支持指令式风格控制,可动态调整情感(开心/悲伤/严肃)、语速、语调等;
支持多角色对话生成,可同时定义多个角色音色,实现剧本式语音输出。
2.3 超低延迟流式生成
创新Dual-Track双轨流式架构,单模型同时支持流式/非流式生成;
端到端合成延迟低至97ms,单字符输入即可输出首个音频包,适配实时交互场景(如智能客服、车载语音、实时字幕转语音);
支持增量文本输入,边输入边生成,无需等待全文输入完成。
2.4 高音质与强鲁棒性
语音重构质量领先:LibriSpeech测试集宽带PESQ评分3.21、窄带3.68,STOI可懂度0.96,UTMOS综合评分4.16;
对噪声文本(错别字、标点缺失、口语化表达、生僻字、特殊符号)鲁棒性强,可自动解析并生成流畅语音;
支持24kHz高采样率输出,音质接近真人录制,适配广播级、有声书级场景。
2.5 全栈开源与易用性
完整开源:模型权重、推理代码、微调脚本、示例代码、技术白皮书全部开放;
多渠道部署:支持本地推理、Web UI、vLLM加速、DashScope API调用;
低门槛使用:提供一键安装脚本、可视化界面,无需深厚AI背景即可快速体验。
三、技术细节
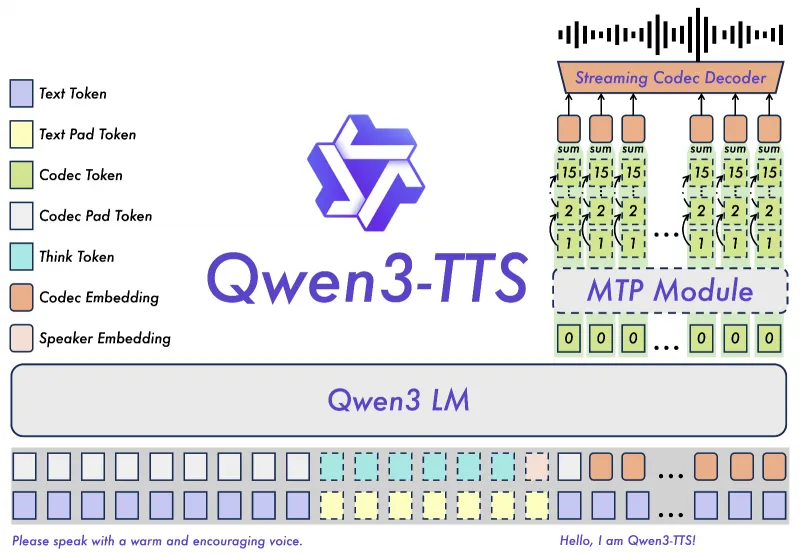
3.1 核心架构:离散多码本LM + Dual-Track流式生成
Qwen3-TTS摒弃传统TTS的“文本→声学模型→声码器”级联架构,采用离散多码本语言模型(LM) 端到端建模,同时通过Dual-Track双轨流式机制实现低延迟生成:
语音Tokenizer:自研Qwen3-TTS-Tokenizer-12Hz,将连续语音信号压缩为12Hz离散码本,实现高效声学表征,完整保留副语言信息(情感、韵律)与声纹特征;
多码本LM:基于Qwen3大模型架构,直接建模“文本→多码本序列”的映射关系,规避级联错误与信息瓶颈;
Dual-Track流式:双轨并行处理——“快速轨”负责首帧音频生成(低延迟),“精准轨”负责后续音频优化(高音质),实现“低延迟+高保真”兼顾。
3.2 关键技术组件
| 组件 | 核心作用 | 技术亮点 |
|---|---|---|
| Qwen3-TTS-Tokenizer-12Hz | 语音编解码(转码/还原) | 12Hz低帧率压缩,PESQ/STOI/UTMOS指标刷新开源纪录,声纹相似度0.95 |
| 离散多码本LM | 端到端语音生成 | 单模型统一建模文本、音色、情感、韵律,支持跨语言与跨音色迁移 |
| Dual-Track流式生成 | 低延迟实时输出 | 首帧延迟97ms,支持增量输入,流式/非流式一键切换 |
| 自然语言指令解析 | 语音控制 | 融合Qwen3语义理解能力,精准解析音色/情感/韵律指令,支持复杂人设描述 |
| 多语言对齐模块 | 跨语言生成 | 统一文本编码器与语音解码器,实现10种语言共享模型权重,降低部署成本 |
3.3 模型矩阵(按能力与规模划分)
Qwen3-TTS提供5类核心模型,覆盖不同场景与算力需求,均支持流式生成:
| 模型名称 | 核心能力 | 参数规模 | 关键特性 | 适用场景 |
|---|---|---|---|---|
| Qwen3-TTS-Tokenizer-12Hz | 语音编解码 | - | 全模型体系基础,支持语音压缩/还原/特征提取 | 语音预处理、克隆基准、声纹分析 |
| Qwen3-TTS-1.7B-Base | 基础语音合成+快速克隆 | 1.7B | 3秒克隆,流式生成,可作为微调底座 | 快速原型开发、基础语音生成 |
| Qwen3-TTS-0.6B-Base | 轻量语音合成+快速克隆 | 0.6B | 低算力需求(4G显存即可运行),流式生成 | 边缘设备、移动端、低成本部署 |
| Qwen3-TTS-1.7B-CustomVoice | 预设音色+指令风格控制 | 1.7B | 9种预设音色,指令控制情感/语速/语调,流式生成 | 内容创作、智能客服、多角色对话 |
| Qwen3-TTS-0.6B-CustomVoice | 轻量预设音色+风格控制 | 0.6B | 低算力,预设音色,基础风格控制 | 轻量化应用、嵌入式设备 |
| Qwen3-TTS-1.7B-VoiceDesign | 自然语言语音设计 | 1.7B | 自由指令定义音色,支持复杂人设,流式生成 | 个性化配音、虚拟人语音、角色创作 |
3.4 训练与优化技术
数据体系:基于通义千问海量多语言语音数据,覆盖日常对话、新闻、朗读、演讲、方言等场景,数据规模达百万小时级;
训练策略:采用“预训练+微调”范式,先通过大规模多语言数据预训练通用语音生成能力,再通过小样本微调适配克隆、设计、流式等专项能力;
加速优化:集成FlashAttention-2、vLLM推理加速、模型量化(FP16/BF16/INT8),在单张RTX 4090/3090显卡上可实时运行1.7B模型;
鲁棒性增强:引入噪声文本、方言口音、跨语言迁移等困难样本训练,提升模型对复杂场景的适配能力。
四、应用场景
4.1 内容创作领域
短视频/直播配音:自动生成多风格语音(搞笑、深情、新闻、广告),支持批量生成,降低配音成本;
有声书/播客制作:高保真24kHz语音,支持多角色对话,可快速将小说/文章转为有声内容;
广告/宣传片配音:通过语音设计定制品牌专属音色,实现“千人千声”的品牌语音形象;
动漫/游戏配音:克隆声优音色,或设计虚拟角色语音,解决配音档期与成本问题。
4.2 智能交互领域
智能客服/虚拟助手:超低延迟流式生成,支持实时语音交互,适配多语言与方言用户;
车载语音系统:支持方言识别与合成,解决“塑料普通话”交互难题,提升驾驶安全;
智能家居/物联网:定制化家庭语音助手音色,实现个性化交互体验;
在线教育/辅导:克隆教师音色,生成课程讲解语音,支持多语言教学。
4.3 辅助与公益领域
视障人士辅助阅读:将文本转为高保真语音,支持长文本流式输出,提升信息获取效率;
语言学习:母语级发音示范,支持10种语言,可定制语速与语调,适配不同学习阶段;
方言文化传承:支持8种方言合成,助力地方文化内容数字化传播;
无障碍通信:为言语障碍人士提供语音合成工具,实现“文本→语音”无障碍交流。
4.4 企业与开发者场景
企业语音定制:克隆企业客服/品牌代言人音色,打造统一的企业语音形象;
RAG+语音集成:将语音生成与检索增强生成结合,实现“知识库问答→语音回复”一体化;
垂直领域微调:基于Base模型微调,适配医疗、金融、法律等专业领域的语音生成需求;
API服务搭建:基于DashScope API或自建服务,为第三方应用提供语音生成能力。
五、使用方法
5.1 环境准备
(1)硬件要求
最低配置:CPU(支持AVX2)+ 16GB内存(可运行0.6B模型,速度较慢);
推荐配置:NVIDIA GPU(RTX 3090/4090/A10等)+ 16GB+显存(1.7B模型推荐24GB+显存);
系统支持:Linux(Ubuntu 20.04+)、Windows 10/11、macOS(Intel/M系列)。
(2)软件依赖
# 克隆仓库 git clone https://github.com/QwenLM/Qwen3-TTS.git cd Qwen3-TTS # 安装依赖(推荐conda环境) conda create -n qwen3-tts python=3.10 conda activate qwen3-tts pip install -e . pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 pip install flash-attn --no-build-isolation # 加速推理(可选)
5.2 本地推理(Python SDK)
(1)基础语音合成(预设音色)
import torch
from qwen_tts import Qwen3TTSModel
import soundfile as sf
# 加载模型(以0.6B-CustomVoice为例)
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# 合成文本
text = "欢迎使用Qwen3-TTS,这是一款开源的多语言语音生成模型,支持语音克隆与设计。"
voice = "xiaoxiao" # 预设音色:晓晓(温柔女声)
# 生成语音
wav = model.synthesize(
text=text,
voice=voice,
speed=1.0, # 语速:0.5-2.0
emotion="neutral", # 情感:neutral/happy/sad/angry
sample_rate=24000,
)
# 保存音频
sf.write("output.wav", wav, 24000)
print("语音已保存为 output.wav")(2)语音克隆(3秒音频)
from qwen_tts import Qwen3TTSModel
import soundfile as sf
import torch
# 加载Base模型
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
)
# 克隆音色(3秒参考音频)
ref_audio, sr = sf.read("reference_3s.wav") # 参考音频:单声道、16kHz/24kHz
cloned_voice = model.clone_voice(ref_audio, sr)
# 用克隆音色生成语音
text = "这是用3秒音频克隆的音色,支持跨语言生成哦!"
wav = model.synthesize(text=text, voice=cloned_voice, sample_rate=24000)
sf.write("cloned_output.wav", wav, 24000)(3)语音设计(自然语言指令)
from qwen_tts import Qwen3TTSModel
import soundfile as sf
import torch
# 加载VoiceDesign模型
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
)
# 设计音色指令
voice_prompt = "25岁青年男性,声音阳光开朗,语速轻快,带点幽默感,适合短视频解说"
designed_voice = model.design_voice(voice_prompt)
# 生成语音
text = "大家好!今天给大家带来一款超好用的开源语音模型——Qwen3-TTS!"
wav = model.synthesize(text=text, voice=designed_voice, sample_rate=24000)
sf.write("designed_output.wav", wav, 24000)5.3 本地Web UI演示
# 启动Web UI(默认端口7860) python app.py # 访问 http://localhost:7860 # 功能:语音克隆、语音设计、预设音色合成、流式生成
5.4 vLLM加速部署(高并发)
# 安装vLLM
pip install vllm>=0.4.2
# 启动vLLM服务
python -m vllm.entrypoints.api_server \
--model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
--tensor-parallel-size 1 \
--dtype bfloat16 \
--port 8000
# 调用API(示例)
curl http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{
"text": "vLLM加速的Qwen3-TTS语音生成",
"voice": "yunyang",
"speed": 1.0,
"sample_rate": 24000
}'5.5 DashScope API调用(云端,无需本地部署)
(1)语音设计API
import requests
import base64
import os
# 获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key = os.getenv("DASHSCOPE_API_KEY")
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
# 语音设计请求
data = {
"model": "qwen-voice-design",
"input": {
"action": "create",
"target_model": "qwen3-tts-vd-realtime-2025-12-16",
"voice_prompt": "沉稳的中年男性播音员,适合新闻播报",
"preview_text": "各位听众朋友,大家好,欢迎收听晚间新闻。",
"preferred_name": "announcer",
"language": "zh"
},
"parameters": {"sample_rate": 24000, "response_format": "wav"}
}
# 发送请求
response = requests.post("https://dashscope.aliyuncs.com/api/v1/services/audio/tts/customization", headers=headers, json=data)
result = response.json()
voice_name = result["output"]["voice"]
audio_data = base64.b64decode(result["output"]["preview_audio"]["data"])
# 保存音频
with open(f"{voice_name}_preview.wav", "wb") as f:
f.write(audio_data)(2)语音克隆API
import requests
import base64
import os
api_key = os.getenv("DASHSCOPE_API_KEY")
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
# 读取参考音频
with open("reference_3s.wav", "rb") as f:
audio_base64 = base64.b64encode(f.read()).decode()
# 语音克隆请求
data = {
"model": "qwen-voice-enrollment",
"input": {
"action": "create",
"target_model": "qwen3-tts-vc-realtime-2025-11-27",
"preferred_name": "my_voice",
"audio": {"data": f"data:audio/wav;base64,{audio_base64}"}
}
}
# 发送请求
response = requests.post("https://dashscope.aliyuncs.com/api/v1/services/audio/tts/customization", headers=headers, json=data)
voice_name = response.json()["output"]["voice"]
print(f"克隆音色名称:{voice_name}")5.6 模型微调(自定义音色/场景)
# 数据准备(参考finetuning/data_prep.py) python finetuning/data_prep.py \ --input_dir ./custom_data \ --output_dir ./finetune_data \ --tokenizer Qwen/Qwen3-TTS-Tokenizer-12Hz # 启动微调(单卡/多卡) torchrun --nproc_per_node=1 finetuning/train.py \ --model_name_or_path Qwen/Qwen3-TTS-12Hz-1.7B-Base \ --data_path ./finetune_data \ --output_dir ./finetuned_model \ --num_train_epochs 3 \ --per_device_train_batch_size 2 \ --learning_rate 2e-5 \ --bf16 True
六、常见问题解答(FAQ)
Q1:运行1.7B模型需要多少显存?
A1:1.7B模型在BF16精度下需16GB+显存(推荐24GB),INT8量化后可降至8GB+;0.6B模型BF16精度需8GB+显存,INT8量化后**4GB+**即可运行。
Q2:Windows/macOS能否运行?
A2:支持,但Windows需安装CUDA 12.1+,macOS M系列芯片可通过MPS加速(速度略低于NVIDIA GPU),Intel芯片仅支持CPU推理(速度较慢)。
Q3:模型加载失败,提示“内存不足”?
A3:1. 降低模型精度(如从BF16改为FP16/INT8);2. 使用device_map="auto"自动分配显存;3. 更换更小参数模型(如0.6B替代1.7B);4. 关闭其他占用显存的程序。
Q4:语音克隆需要多长的参考音频?
A4:最短3秒即可,推荐5-10秒,音频越清晰、语速越平稳,克隆效果越好;避免噪声大、语速过快/过慢的音频。
Q5:语音设计的指令怎么写效果更好?
A5:指令需具体、明确,包含:性别、年龄、音色特征(低沉/甜美/洪亮)、语速、情感、场景(如“30岁女性,温柔甜美,语速中等,情感亲切,适合有声书朗读”);避免模糊描述(如“好听的声音”)。
Q6:流式生成如何使用?
A6:在synthesize方法中设置streaming=True,或通过Web UI的“流式生成”按钮;支持增量输入文本,边输入边输出音频,适合实时交互场景。
Q7:支持哪些音频格式输出?
A7:支持WAV、MP3、FLAC,默认24kHz采样率,单声道;可通过sample_rate参数调整为16kHz/8kHz。
Q8:如何将Qwen3-TTS集成到自己的项目中?
A8:1. 本地集成:直接调用Python SDK;2. 云端集成:使用DashScope API;3. 服务化部署:通过vLLM/FastAPI搭建RESTful API,供前端/后端调用。
Q9:DashScope API收费吗?
A9:DashScope提供免费额度(新用户可领取),超出后按调用次数/音频时长收费,具体价格参考阿里云Model Studio官网。
Q10:模型支持多角色对话生成吗?
A10:支持,可通过多次调用synthesize方法,为不同角色指定不同音色(克隆/设计/预设),再拼接音频;或通过VoiceDesign模型一次性定义多个角色音色,批量生成。
Q11:方言合成效果如何?
A11:内置8种方言均经过专业数据训练,发音标准、韵律自然,可满足日常交流与内容创作需求;部分小众方言可通过微调进一步优化。
七、相关链接
GitHub仓库:https://github.com/QwenLM/Qwen3-TTS
Hugging Face模型库:https://huggingface.co/Qwen
ModelScope模型库(国内):https://www.modelscope.cn/organization/qwen
DashScope API文档:
语音设计:https://www.alibabacloud.com/help/zh/model-studio/qwen-tts-voice-design
语音克隆:https://www.alibabacloud.com/help/zh/model-studio/qwen-tts-voice-cloning
技术白皮书:https://github.com/QwenLM/Qwen3-TTS/blob/main/assets/Qwen3_TTS.pdf
八、总结
Qwen3-TTS作为阿里云通义千问团队开源的全能力语音生成模型,凭借多语言方言覆盖、3秒极速克隆、自然语言语音设计、97ms超低延迟流式生成、高保真音质五大核心优势,构建了从个人体验到企业商用的完整语音生成解决方案。其离散多码本LM架构与Dual-Track流式技术突破了传统TTS的性能瓶颈,模型矩阵覆盖不同算力与场景需求,同时提供完善的SDK、API、微调与部署方案,降低了语音生成技术的使用门槛。无论是内容创作者快速制作配音、开发者搭建智能交互系统,还是企业定制专属语音形象,Qwen3-TTS均能提供高效、高质量的技术支撑,是当前开源语音合成领域的标杆级项目。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/qwen3-tts.html





