Skyvern:开源浏览器工作流自动化工具,基于LLM与计算机视觉实现灵活可靠的网页交互
一、Skyvern是什么?
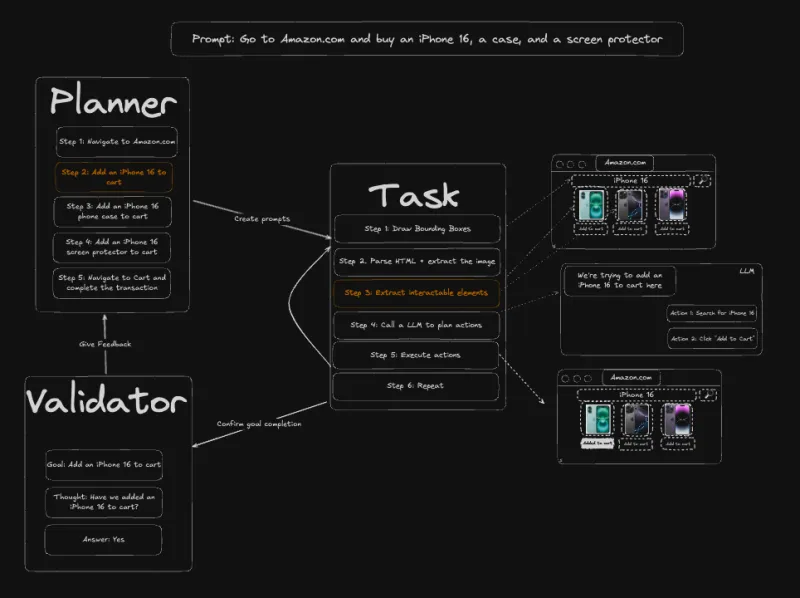
Skyvern是一款基于大语言模型(LLMs)和计算机视觉的开源浏览器工作流自动化工具,旨在解决传统自动化方案(如依赖XPath或DOM解析)的脆弱性问题。它通过视觉理解和逻辑推理能力,实现对各类网站的灵活交互(如表单填写、登录、文件下载等),支持跨站适配和复杂场景处理。无论是电商数据采集、金融报表自动化还是政务流程简化,Skyvern都能提供可靠的自动化支持,同时具备自服务UI和工作流可视化功能,降低使用门槛。
简单来说,传统工具是“按坐标找按钮”,而Skyvern是“看到按钮就知道该点”。这种特性让它能适应几乎所有网站,尤其适合处理结构多变的动态页面(如电商平台、政务网站、企业SaaS系统等)。

二、功能特色
Skyvern的功能设计围绕“灵活、可靠、易用”三大目标,相比传统自动化工具,其核心特色如下:
1. 视觉理解驱动的网页交互,摆脱对固定结构的依赖
传统工具需要开发者手动编写XPath或CSS选择器定位元素(如“//button[@id='submit']”),一旦网页更新(如按钮ID从“submit”改为“submit-btn”),脚本立即失效。而Skyvern通过计算机视觉技术“观察”网页,结合LLM对元素的语义理解(如“识别‘登录’按钮”“找到输入手机号的文本框”),直接定位目标元素,无需依赖固定代码。
例如,当用户需要“点击页面上的‘提交’按钮”时,Skyvern会:
截取当前网页截图;
用计算机视觉模型识别所有按钮元素;
调用LLM分析按钮上的文字(或图标含义),匹配“提交”语义;
精准点击目标按钮。
2. 跨网站适配能力,支持“从未见过的网站”
传统工具的脚本通常针对单一网站编写,换一个网站就需要重新开发。Skyvern则具备“通用认知”能力:通过LLM对网页功能的理解(如“所有电商网站的‘加入购物车’按钮功能相似”),结合视觉识别,能直接处理从未接触过的网站。
例如,用户只需下达“在任意电商网站搜索‘笔记本电脑’并获取前10个商品的价格”的指令,Skyvern就能自动分析网站结构(搜索框位置、搜索按钮、商品列表布局),完成操作,无需针对某一平台单独配置。
3. 复杂场景推理,解决“需要思考”的任务
传统工具只能执行预设的线性步骤(如“点击A→输入B→点击C”),无法处理需要逻辑判断的场景。Skyvern借助LLM的推理能力,能解决涉及规则、计算或语义理解的复杂任务。
典型案例包括:
从身份证照片中提取生日,自动计算年龄并判断是否满足“18岁以上”的表单要求;
在机票预订页面,根据用户“价格低于500元且飞行时间不超过3小时”的条件,筛选符合要求的航班;
识别网页中“相似商品”(如颜色不同但型号一致的手机),并汇总其价格差异。
4. 完整的工作流支持,构建复杂自动化流程
Skyvern不仅能执行单一操作,还支持将多个任务“串联”成工作流,实现端到端自动化。例如:
自动登录企业OA系统;
下载最新的销售报表;
登录数据分析平台并上传报表;
生成可视化图表后发送到指定邮箱。
用户可通过UI工具拖拽配置工作流,无需编写代码,且支持实时查看流程进度(如“当前执行到‘上传报表’步骤”)。
5. 自服务与可视化工具,降低使用门槛
为了让非技术人员也能快速上手,Skyvern提供了一系列辅助功能:
自服务UI:基于React的网页界面,支持任务创建、运行监控、历史记录查询(如查看“昨天10点的商品采集任务为何失败”);
工作流可视化构建器:通过拖拽组件(如“点击”“输入”“等待”)设计流程,自动生成执行逻辑;
实时视口流:将Chrome浏览器的操作过程实时同步到UI,用户可直观看到自动化步骤(类似“远程桌面”),便于调试。
6. 对比传统自动化工具的核心优势
为更清晰展示Skyvern的特色,以下是与传统工具(以Selenium为例)的对比:
| 特性 | 传统工具(如Selenium) | Skyvern |
|---|---|---|
| 元素定位方式 | 依赖XPath、CSS选择器等固定结构 | 计算机视觉+LLM语义理解 |
| 网站布局变化适应性 | 脆弱(布局一变就失效) | 强(自动识别新布局) |
| 跨网站复用性 | 低(需为每个网站编写脚本) | 高(通用逻辑适配多网站) |
| 复杂场景处理能力 | 弱(仅支持线性步骤) | 强(LLM推理解决逻辑判断) |
| 非技术人员使用门槛 | 高(需编程基础) | 低(可视化UI+无代码配置) |

三、技术细节
Skyvern的核心能力源于“LLM+计算机视觉+浏览器自动化”的技术融合,其底层架构和工作原理如下:
1. 核心技术栈
大语言模型(LLMs):负责语义理解、逻辑推理和步骤规划(如GPT-4、Claude等,支持自定义模型配置);
计算机视觉:基于深度学习模型(如YOLO、ResNet)识别网页元素(按钮、文本框、图片等),并提取元素位置和内容;
浏览器自动化引擎:集成Playwright(跨浏览器自动化库),执行点击、输入、滚动等操作;
后端框架:FastAPI(高性能API服务)、Python(核心逻辑)、Node.js(前端依赖);
前端技术:React(构建自服务UI和工作流编辑器)。
2. 工作原理:Task-Driven自主代理模式
Skyvern借鉴了“任务驱动型自主代理”(如BabyAGI)的设计思路,通过“代理集群”协同完成任务,核心步骤分为3步:
(1)理解:解析任务与网页内容
接收用户任务(如“登录某银行官网并查询余额”);
启动浏览器加载目标网页,抓取DOM结构和截图;
调用计算机视觉模型识别网页元素(类型、位置、文本),生成“元素列表”;
结合LLM分析元素功能(如“这个文本框是输入账号的”),构建“网页认知图谱”。
(2)规划:拆解步骤与制定策略
LLM基于“网页认知图谱”和任务目标,拆解出具体步骤(如“1. 点击‘账号输入框’;2. 输入账号;3. 点击‘密码输入框’;4. 输入密码;5. 点击‘登录’按钮”);
针对可能的异常(如“登录后跳转到验证码页面”),提前规划备选方案(如“若出现验证码,调用第三方验证码识别服务”)。
(3)执行:操作网页与动态调整
通过Playwright执行规划的步骤,实时反馈操作结果(如“点击成功”“输入失败”);
若操作失败(如“按钮未被点击”),自动重新识别元素(可能因网页加载延迟导致位置变化)并重试;
完成所有步骤后,返回任务结果(如“余额截图”“数据表格”)。
3. 架构模块说明
Skyvern的代码结构清晰,核心模块如下表所示:
| 模块路径 | 功能描述 |
|---|---|
skyvern/agent/ | LLM驱动的“决策代理”,负责任务解析、步骤规划和异常处理 |
skyvern/webeye/ | “视觉引擎”,集成计算机视觉模型和Playwright,实现元素识别和网页操作 |
skyvern/forge/ | FastAPI服务器,提供API接口(如任务创建、状态查询),处理前端与后端的通信 |
skyvern/services/ | 业务逻辑层,管理任务队列、工作流调度、浏览器会话生命周期 |
skyvern/cli/ | 命令行工具,支持通过终端启动服务、运行任务(适合技术人员快速测试) |
skyvern-frontend/ | React前端项目,包含任务管理UI、工作流编辑器、实时视口流展示等界面组件 |
4. 性能表现
在权威的WebBench基准测试(webbench.ai,衡量网页自动化工具的准确率)中,Skyvern达到64.4%的准确率,远超传统工具(平均约30-40%),尤其在“表单填写”“登录”“文件下载”等RPA核心场景中表现最佳。
四、应用场景
Skyvern的灵活性和可靠性使其适用于各类需要网页自动化的场景,以下是典型案例:
1. 电商数据采集与竞品分析
电商平台(如淘宝、京东、亚马逊)的商品信息(价格、销量、评价)是企业决策的关键,但这些平台的页面布局频繁更新(如促销活动导致按钮位置变化)。
Skyvern可实现:
定时采集指定品类商品的价格、库存,生成价格波动报表;
抓取竞品店铺的新品上架信息,自动同步到企业内部系统;
提取用户评价中的关键词(如“质量好”“物流慢”),生成舆情分析报告。
2. 金融与财务流程自动化
金融行业的报表生成、数据核对等工作依赖多个系统(如银行官网、ERP软件、税务平台),且系统往往有严格的登录验证和复杂的表单逻辑。
Skyvern可实现:
自动登录银行企业网银,下载月度流水并同步到财务系统;
登录税务平台,根据ERP中的销售数据自动填写增值税申报表;
监控股票、基金网站的实时行情,当价格触发预设阈值时发送提醒。
3. 政务服务与公共信息查询
政务网站(如社保、公积金、不动产登记平台)的流程往往繁琐(如多次跳转、验证码、必填项校验),且不同地区的网站结构差异大。
Skyvern可实现:
自动登录个人社保账户,查询缴费记录并生成PDF报告;
批量查询企业信用信息公示系统中的企业年报数据,筛选异常信息;
协助政府部门批量处理市民提交的在线申请(如自动核对表单填写完整性)。
4. 社交媒体与内容运营
社交媒体平台(如微信公众号、抖音、Twitter)的内容发布、数据统计需要重复操作,且平台常更新界面功能。
Skyvern可实现:
按预设时间自动发布图文内容到多个平台(如同时发布到公众号和小红书);
抓取指定账号的粉丝增长、点赞数据,生成周度运营报表;
监测竞品账号的内容更新,自动同步到内容策划团队。
5. 企业内部系统自动化
企业内部的OA、CRM、HRM等系统往往功能固定但操作繁琐(如每月考勤统计、客户信息录入),且部分系统接口封闭,无法通过API集成。
Skyvern可实现:
自动登录OA系统,汇总各部门的周报并生成汇总文档;
从Excel表格中读取客户信息,批量录入CRM系统;
登录HRM系统,导出员工考勤数据并计算薪资扣除项。
五、使用方法
Skyvern提供两种使用方式:托管版(Skyvern Cloud)和本地部署,满足不同用户的需求(如非技术人员偏好托管版,开发者偏好本地定制)。
1. Skyvern Cloud(托管版)
适合无技术背景的用户,无需配置服务器和依赖,直接通过网页使用。
步骤:
(1)访问官网注册:打开 https://app.skyvern.com,注册账号并完成实名认证;
(2)创建任务:在“任务管理”页面点击“新建任务”,选择模板(如“网页登录”“数据采集”)或自定义任务;
(3)配置参数:以“电商商品采集”为例,输入目标网址、关键词、采集字段(价格、标题等);
(4)运行任务:点击“启动”,在“实时视口”中查看自动化过程,完成后下载结果(支持CSV、Excel格式);
(5)创建工作流:在“工作流编辑器”中,拖拽任务节点(如“采集商品→发送邮件”),设置触发条件(如“每天10点执行”)。
2. 本地部署(开源版)
适合开发者或需要定制功能的团队,需自行配置环境。
(1)依赖要求
操作系统:Linux(Ubuntu 20.04+)、macOS(12+)、Windows(需额外安装Rust和C++开发工具,如Visual Studio Build Tools);
编程语言:Python 3.11.x(支持3.12,暂不支持3.13)、Node.js 16+(含NPM);
其他:Chrome浏览器(用于自动化操作)、Git(拉取代码)。
(2)安装步骤
① 拉取代码
git clone https://github.com/Skyvern-AI/skyvern.git cd skyvern
② 安装后端依赖
# 创建虚拟环境(可选但推荐) python -m venv venv source venv/bin/activate # Linux/macOS # 或 venv\Scripts\activate # Windows # 安装Python依赖 pip install -e .
③ 安装前端依赖
cd skyvern-frontend npm install
④ 配置环境变量
创建.env文件,设置必要参数(如LLM API密钥、存储路径等):
# 示例:使用OpenAI的GPT-4 OPENAI_API_KEY=your_openai_key # 浏览器缓存路径 BROWSER_CACHE_DIR=./browser_cache
(3)启动服务
① 启动后端API
# 在项目根目录 skyvern server start
服务默认运行在 http://localhost:8000。
② 启动前端UI
# 在skyvern-frontend目录 npm start
前端默认运行在 http://localhost:3000,打开浏览器即可访问。
(4)快速测试:自动登录示例
通过Python代码调用API,实现“登录某网站”的任务:
from skyvern.client import SkyvernClient
client = SkyvernClient(base_url="http://localhost:8000")
# 定义任务:登录示例网站
task = {
"name": "示例登录",
"url": "https://example-login.com",
"steps": [
{"action": "input", "element": "用户名输入框", "value": "test_user"},
{"action": "input", "element": "密码输入框", "value": "test_pass"},
{"action": "click", "element": "登录按钮"}
]
}
# 提交任务
response = client.create_task(task)
task_id = response["task_id"]
# 查询结果
result = client.get_task_result(task_id)
print("登录结果:", result["status"]) # 输出:success 或 failed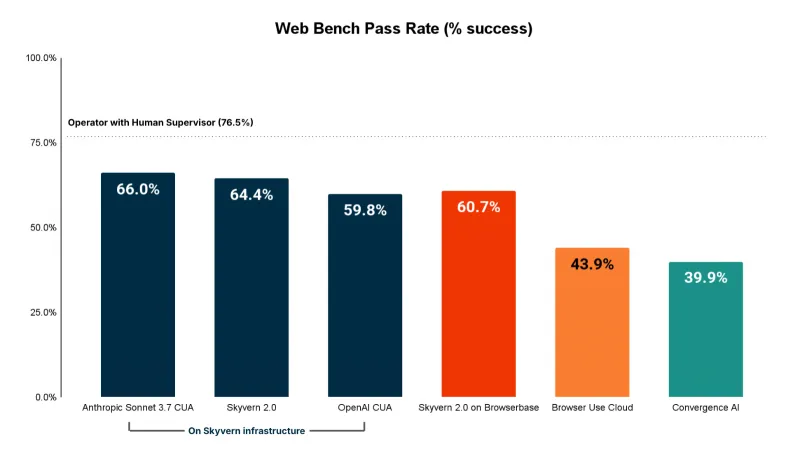
六、常见问题解答(FAQ)
1. Skyvern支持哪些浏览器?
目前主要支持Chrome浏览器(基于Playwright的Chrome驱动),未来计划扩展到Firefox和Edge。
2. 与Selenium相比,Skyvern的性能如何?
在简单场景(如固定结构的网页点击)中,Selenium速度略快(因无需视觉识别和LLM推理);但在复杂场景(如布局多变的网页、需要逻辑判断的任务)中,Skyvern的成功率远超Selenium,综合效率更高。
3. 使用Skyvern需要编程基础吗?
托管版(Skyvern Cloud):无需编程,通过UI界面配置任务和工作流即可;
本地部署版:基础使用无需编程(通过UI操作),但定制化开发(如修改核心逻辑)需要Python和JavaScript基础。
4. 如何处理网页验证码(CAPTCHA)?
Skyvern Cloud内置了第三方验证码识别服务(如Anti-CAPTCHA),可自动处理简单验证码(如数字、字母);复杂验证码(如滑块、图文识别)需手动干预或配置更高级的识别服务。
5. 支持本地化部署LLM模型吗?
支持。用户可将LLM替换为本地部署的模型(如Llama 3、Mistral),只需在环境变量中配置模型API地址即可,但需确保模型具备足够的语义理解和推理能力。
6. 免费吗?
开源版(本地部署):完全免费,可自由修改和商用(遵循Apache 2.0许可证);
Skyvern Cloud:提供免费额度(如每月50个任务),超出后需订阅付费套餐。
七、相关链接
八、总结
Skyvern作为一款基于LLM和计算机视觉的开源浏览器工作流自动化工具,通过模拟人类的网页交互方式,解决了传统自动化工具依赖固定结构、脆弱性高的核心痛点。它兼具跨站适配能力、复杂场景推理能力和低使用门槛,适用于电商数据采集、金融流程自动化、政务服务等多类场景。无论是非技术人员通过托管版快速配置任务,还是开发者基于开源代码定制功能,Skyvern都能提供灵活可靠的自动化支持,成为提升网页操作效率的重要工具。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/skyvern.html





