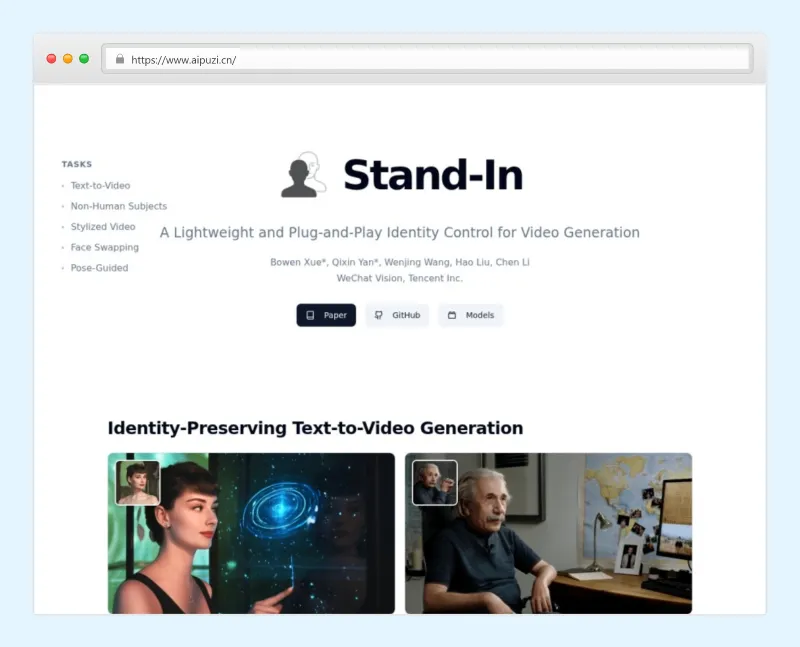
Stand-In:微信CV团队开源的轻量即插即用视频生成身份控制框架
一、Stand-In是什么?
Stand-In是由微信CV团队(WeChatCV)开发并开源的身份保留视频生成框架,定位为“轻量、即插即用、高扩展”,核心目标是解决视频生成过程中“身份一致性”与“生成质量”难以兼顾的痛点。
传统视频生成模型在进行主体驱动(如特定人物、卡通角色)生成时,要么需要全参数微调(计算成本高、耗时久),要么容易出现身份失真(如人脸变形、特征丢失)。而Stand-In通过创新的轻量化设计,仅在基础视频生成模型(如Wan2.1-14B-T2V)上新增1%的可训练参数,就能实现“身份精准保留+视频自然流畅”的双重效果,在人脸相似度(Face Similarity)和生成自然度(Naturalness)两项关键指标上达到当前最优(state-of-the-art)水平。
此外,Stand-In并非局限于单一任务的工具,而是一个灵活的技术框架:它可无缝嵌入现有文本到视频(T2V)工作流,同时兼容风格化(LoRA)、姿态控制(VACE)、人脸互换等多种下游任务,支持人类与非人类主体(如卡通角色、动物)的身份保留生成,具备极强的场景适应性。
二、功能特色
Stand-In的核心竞争力体现在“轻量高效、保真度高、灵活扩展”三大维度,具体功能可分为核心特性与场景化功能两类,兼具技术优势与实用价值:
(一)核心特性(Key Features)
极致高效的训练成本:仅需训练基础模型1%的额外参数,无需全量微调,大幅降低硬件门槛与训练耗时。例如,基于Wan2.1-14B-T2V基础模型,Stand-In v1.0仅新增153M参数,普通GPU即可完成适配训练。
超高身份保真度:在生成视频时,精准保留参考图像/视频中主体的核心特征(如人脸轮廓、五官细节、非人类主体的造型特征),同时保证视频画面的自然流畅,不会因身份约束导致动作僵硬或场景失真。
真正即插即用:无需重构现有文本到视频(T2V)模型的代码框架,可直接集成到主流T2V工作流中,开发者无需大量适配工作,快速启用身份控制功能。
极强扩展性:兼容社区主流技术生态,支持LoRA(风格化模型)、VACE(姿态控制工具)等第三方组件,可灵活扩展到风格化视频生成、姿态引导生成、人脸互换等多种下游任务,而非局限于单一功能。
(二)场景化功能展示
根据项目官方 Showcase,Stand-In已实现以下核心场景的身份保留视频生成,覆盖人类、非人类主体及多种创意需求:
| 功能类别 | 核心描述 | 应用示例 |
|---|---|---|
| 身份保留文本到视频(T2V) | 输入参考图像+文本提示,生成保留主体身份的视频,支持镜头变化(中景转特写)、动作描述 | 参考图像为某女性,提示词“在墙面如水波般涟漪的走廊中,伸手触摸流动的墙面,镜头从中景推至特写”,生成视频保留该女性五官与神态,同时还原场景与动作 |
| 非人类主体保留生成 | 支持卡通角色、动物等非人类主体,精准保留其造型特征,结合文本生成动态视频 | 参考图像为Q版侦探男孩,提示词“踩着滑板疾驰,手持侦探小说,背景为城市街道、树木与广告牌” |
| 身份保留风格化生成 | 集成LoRA风格模型,在保留主体身份的同时,赋予视频特定艺术风格 | 结合吉卜力(Ghibli)LoRA,生成具有Studio Ghibli动画风格、且保留参考主体特征的视频 |
| 视频人脸互换(实验版) | 替换参考视频中的人脸为目标身份,保持背景、动作、场景一致性 | 参考视频为科技类演讲画面,目标身份为某女性,生成视频保留演讲动作与背景,仅替换人脸且自然融合 |
| 姿态引导视频生成(兼容VACE) | 基于参考姿态视频/图像,生成符合指定姿态、且保留主体身份的视频 | 参考姿态为“抬手动作”,输入目标主体图像,生成该主体做出抬手动作的视频,姿态精准且身份不变 |
这些功能的核心共性的是:无论场景、风格、动作如何变化,始终牢牢锁定主体的核心身份特征,解决了传统视频生成中“换场景/动作就换脸”“加风格就失身份”的痛点。

三、技术细节
Stand-In的技术优势源于其“轻量化适配+模块化设计”,以下从核心技术亮点、模型架构、依赖生态三方面拆解,兼顾专业性与通俗性:
(一)核心技术亮点
1%参数训练的奥秘:增量适配架构
Stand-In并未对基础T2V模型(如Wan2.1-14B-T2V)进行全量微调,而是采用“增量参数训练”方案:仅在基础模型的关键特征层插入少量适配模块(总参数153M,约为基础模型的1%),通过聚焦“身份特征提取与对齐”任务,实现用极小的参数成本达到高精度身份保留。这种设计既降低了训练时的显存占用(普通GPU即可支持),又避免了全量微调导致的“过拟合”或“生成质量下降”问题。身份与自然度平衡:双目标优化策略
传统身份控制模型容易陷入“为了保身份而牺牲自然度”的困境(如生成视频动作僵硬、画面卡顿)。Stand-In通过双目标损失函数优化:一方面采用人脸特征相似度损失(基于antelopev2人脸 recognition 模型提取特征,确保身份一致);另一方面沿用基础T2V模型的自然度损失(保证画面流畅、场景合理),两者权重动态平衡,最终实现“身份准、画面美”的双重效果。即插即用的实现:模块化接口设计
Stand-In的核心模块与基础T2V模型采用松耦合设计,通过标准化接口对接,无需修改基础模型的核心代码。例如,对于Wan2.1-14B-T2V,仅需加载Stand-In的增量参数权重,即可启用身份控制功能;若要集成LoRA或VACE,也只需通过指定路径加载对应模块,无需重构整个推理流程。
(二)模型架构与参数规格
基础模型依赖:核心适配Wan2.1-14B-T2V(文本到视频基础模型),后续将支持Wan2.2-T2V-A14B(已列入Todo List);
Stand-In核心参数:v1.0版本总参数153M,支持与基础模型无缝拼接;
依赖辅助模型:
antelopev2:人脸特征提取模型,用于计算生成视频与参考图像的人脸相似度,指导训练优化;
VACE:姿态控制模型(可选),提供姿态特征编码,支持姿态引导生成;
LoRA模型(可选):社区风格化模型,通过接口集成,无需修改Stand-In核心代码。
(三)技术依赖与优化
训练/推理框架:基于DiffSynth-Studio开发,继承其高效的扩散模型训练流水线,支持分布式训练与快速推理;
推理优化:支持Flash Attention(需GPU与CUDA版本兼容),启用后可大幅提升推理速度,减少显存占用;
数据预处理:内置图像/视频预处理流水线,自动处理不同分辨率、不同格式的输入(无需用户手动调整图像尺寸、格式),降低使用门槛。
(四)开源生态依赖
Stand-In基于多个优秀开源项目构建,体现了开源协作精神:
基础视频生成:Wan2.1(提供核心T2V生成能力);
训练/推理框架:DiffSynth-Studio(提供扩散模型训练与推理的基础架构);
人脸识别:antelopev2(提供高精度人脸特征提取);
姿态控制:VACE(提供姿态引导能力,需单独下载权重)。
四、应用场景
基于“身份保留+灵活扩展”的核心能力,Stand-In可广泛应用于内容创作、影视制作、社交媒体、虚拟人等多个领域,以下是具体落地场景与使用示例:
(一)内容创作领域
短视频/自媒体:快速生成“固定IP形象+不同场景”的系列视频。例如,博主可上传自己的形象作为参考,通过不同文本提示词,生成“在海边度假”“在书房看书”“在街头探店”等多个场景的视频,无需反复拍摄,且始终保持自己的形象一致;
动画/插画师:为原创角色生成动态视频。例如,插画师设计了一个卡通角色,通过Stand-In+LoRA,可快速生成该角色在不同场景(森林、城市、太空)、不同风格(水墨、二次元、3D渲染)的动态短片,用于作品集展示或短视频平台发布。
(二)影视与广告制作
低成本替身合成:在影视拍摄中,若演员无法完成特定动作(如危险动作、复杂姿态),可先用替身拍摄姿态视频,再通过Stand-In替换为目标演员的脸,保持画面连贯,降低拍摄成本与风险;
广告个性化定制:品牌可基于同一产品广告片,通过Stand-In替换为不同地区、不同风格的代言人形象,无需重新拍摄,快速适配多区域市场需求。
(三)社交媒体与个性化娱乐
人脸互换趣味视频:用户可上传自己的照片,替换热门视频(如电影片段、综艺名场面)中的主角人脸,生成个性化趣味内容,用于社交分享;
虚拟形象动态生成:游戏玩家可上传自己的虚拟角色形象,通过文本提示生成该角色的战斗、休闲等动态视频,用于游戏社区分享或直播背景。
(四)虚拟人与数字人领域
虚拟人动作生成:为虚拟人设定固定形象后,通过文本或姿态提示,生成该虚拟人进行演讲、跳舞、互动的视频,无需手动制作关键帧动画;
数字人身份复用:企业数字人(如客服、主播)可通过Stand-In快速生成不同场景的视频内容(如产品介绍、节日祝福),保持数字人形象一致,提升品牌辨识度。
(五)科研与开发者生态
视频生成技术研究:为研究“身份控制”“轻量化适配”“多模态对齐”等方向的科研人员提供开源框架与数据集(后续将开源训练数据与代码);
工具链集成:开发者可将Stand-In集成到自己的视频生成工具中(如ComfyUI、Stable Diffusion WebUI),快速添加身份保留功能,丰富工具生态。
四、使用方法
Stand-In提供了清晰的部署与使用流程,支持Windows、Linux等系统,核心分为“环境搭建→模型下载→功能调用”三步,以下是详细操作指南:
(一)前置条件
硬件要求:支持CUDA的GPU(建议显存≥16GB,启用Flash Attention后可降低至12GB);
软件依赖:Python 3.11、Conda(环境管理)、Git(仓库克隆)。
(二)第一步:环境搭建
克隆项目仓库
打开终端,执行以下命令下载项目代码:
git clone https://github.com/WeChatCV/Stand-In.git cd Stand-In # 进入项目根目录
创建并激活Conda环境
使用Python 3.11创建独立环境,避免依赖冲突:
conda create -n Stand-In python=3.11 -y conda activate Stand-In # 激活环境(后续操作均需在该环境下执行)
安装依赖包
项目提供了requirements.txt文件,一键安装核心依赖:
pip install -r requirements.txt
(可选)安装Flash Attention(推理加速)
若GPU与CUDA版本兼容,可安装Flash Attention提升推理速度、减少显存占用:
pip install flash-attn --no-build-isolation
提示:若安装失败,可忽略此步骤,不影响核心功能使用,仅推理速度略有下降。
(三)第二步:模型下载
Stand-In需要三类模型文件:基础T2V模型(wan2.1-T2V-14B)、人脸 recognition 模型(antelopev2)、Stand-In核心模型。项目提供自动下载脚本,一键获取:
python download_models.py
脚本会自动将所有模型下载到项目根目录的checkpoints文件夹下,无需手动配置路径。
特殊情况处理:
若本地已拥有
wan2.1-T2V-14B模型:编辑download_models.py脚本,注释掉该模型的下载代码,然后将本地模型文件夹复制到checkpoints/wan2.1-T2V-14B路径下即可。
(四)第三步:功能调用(核心操作)
Stand-In为不同功能提供了独立的推理脚本,以下是五大核心功能的完整使用命令与参数说明,直接复制修改即可运行:
1. 标准身份保留文本到视频生成
使用infer.py脚本,输入参考图像+文本提示,生成身份保留视频:
python infer.py \ --prompt "A man sits comfortably at a desk, facing the camera as if talking to a friend. His gaze is gentle with a natural smile. The background is a decorated personal space with photos and a world map on the wall." \ --ip_image "test/input/lecun.jpg" \ --output "test/output/lecun.mp4"
关键参数说明:
--prompt:文本提示词,支持中文/英文(例如中文提示:“一个男人舒适地坐在书桌前,面对镜头微笑,背景是挂有照片和世界地图的私人空间”);--ip_image:参考图像路径(支持任意分辨率、任意格式,内置预处理会自动处理);--output:输出视频路径(格式为MP4)。
Prompt写作技巧:若不想修改主体外貌,仅用“a man”“a woman”“一个男孩”等通用描述,避免添加“高鼻梁”“长发”等外貌细节;建议生成正面、中近景视频,效果最佳。
2. 集成LoRA的风格化身份保留生成
使用infer_with_lora.py脚本,加载LoRA模型,生成风格化+身份保留视频:
python infer_with_lora.py \ --prompt "一个女孩站在樱花树下,轻轻抬手触碰花瓣,背景是飘落的樱花" \ --ip_image "test/input/girl.jpg" \ --output "test/output/girl_ghibli.mp4" \ --lora_path "path/to/your/ghibli_lora.safetensors" \ --lora_scale 1.0
关键参数说明:
--lora_path:LoRA模型文件路径(建议使用适配Wan2.1-14B-T2V的LoRA,官方推荐吉卜力风格LoRA:https://civitai.com/models/1404755/studio-ghibli-wan21-t2v-14b);--lora_scale:LoRA风格强度(0-2.0,1.0为默认,数值越高风格越明显)。
3. 视频人脸互换(实验版)
使用infer_face_swap.py脚本,替换参考视频中的人脸为目标身份:
python infer_face_swap.py \ --prompt "The woman is presenting tech news in front of a screen with 'Tech Minute' logo, background is a cityscape." \ --ip_image "test/input/ruonan.jpg" \ --output "test/output/ruonan_face_swap.mp4" \ --denoising_strength 0.85
关键参数说明:
--denoising_strength:去噪强度(0-1.0),数值越高,背景重绘越彻底,人脸融合越自然;数值越低,背景保留越完整,但人脸可能出现“过拟合”(僵硬、不自然);--force_background_consistency(可选):强制背景一致,需配合调整denoising_strength(建议0.6-0.7),可能导致人脸轮廓不自然,非必要不启用。
注意:该功能为实验版,因Wan2.1模型无内置修复功能,复杂场景可能出现轻微轮廓瑕疵,需通过调整
denoising_strength优化。
4. 姿态引导生成(兼容VACE)
使用infer_with_vace.py脚本,基于参考姿态生成身份保留视频:
python infer_with_vace.py \ --prompt "A woman raises her hands slowly" \ --vace_path "checkpoints/VACE/" \ --ip_image "test/input/first_frame.png" \ --reference_video "test/input/pose.mp4" \ --output "test/output/woman_pose.mp4" \ --vace_scale 0.8
关键参数说明:
--vace_path:VACE模型权重路径(需提前从VACE仓库下载:https://github.com/VACE-team/VACE);--reference_video:参考姿态视频(需用VACE预处理工具处理);--vace_scale:姿态控制强度(0-1.0),因VACE默认偏向人脸控制,建议设置0.5-0.8,平衡姿态精准度与身份保留度;--reference_image(可选):参考姿态图像,可与reference_video同时使用。
注意:该功能配置较复杂,若仅需基础姿态控制,建议先降低
vace_scale(如0.5)测试效果;若出现身份失真,可进一步调低数值。
(五)ComfyUI集成使用
若习惯用ComfyUI可视化操作,可使用官方提供的预处理节点:
下载官方ComfyUI节点:
git clone https://github.com/WeChatCV/Stand-In_Preprocessor_ComfyUI;将节点文件夹复制到ComfyUI的
custom_nodes目录下;重启ComfyUI,在节点列表中搜索“Stand-In Preprocessor”,替换第三方实现的节点(避免性能问题);
后续将推出完整官方ComfyUI节点,建议等待正式版以获得最佳效果。
五、常见问题解答(FAQ)
(一)安装与环境类
Q:运行
download_models.py时下载速度慢或失败怎么办?
A:可手动下载模型:基础模型(wan2.1-T2V-14B)、antelopev2、Stand-In核心模型,将其分别放入checkpoints对应文件夹(如checkpoints/wan2.1-T2V-14B),文件夹命名需与脚本一致;若仅基础模型下载失败,可注释脚本中该模型的下载代码,手动放置本地模型。Q:安装Flash Attention时提示“CUDA版本不兼容”?
A:忽略该步骤,不影响核心功能,仅推理速度略有下降;若需启用,可升级CUDA版本(建议11.8+)或更换支持的GPU(如NVIDIA A100、3090、4090等)。Q:Conda创建环境时提示“Python 3.11未找到”?
A:更新Conda至最新版本:conda update conda,再重新创建环境;若仍失败,可使用Python 3.10(需测试依赖兼容性,官方推荐3.11)。
(二)使用操作类
Q:输入图像有什么要求?什么样的图像生成效果最好?
A:最佳输入为“高分辨率正面人脸图像”(无遮挡、光线均匀);非人类主体需保证图像清晰、主体特征明确;无需手动调整分辨率或格式,内置预处理会自动处理,但模糊、遮挡严重的图像会影响身份保留效果,建议优先选择清晰素材。Q:Prompt支持中文,为什么生成效果不如英文?
A:基础模型Wan2.1-14B-T2V对英文提示词的理解更精准,若需中文输入,建议提示词简洁明确,避免复杂句式;重要场景(如精准动作描述)可尝试中英文对照输入。Q:ComfyUI中使用第三方Stand-In节点后,生成效果差怎么办?
A:立即替换为官方Preprocessor节点(https://github.com/WeChatCV/Stand-In_Preprocessor_ComfyUI),第三方节点实现与官方版本差异较大,会导致身份保留精度下降;建议等待官方完整ComfyUI节点发布。
(三)效果优化类
Q:人脸互换时,人脸与背景融合不自然,有明显轮廓怎么办?
A:调整--denoising_strength参数(建议0.8-0.9),提高背景重绘程度;若启用了--force_background_consistency,建议关闭该参数,优先保证人脸自然度;若仍有问题,可更换分辨率更高的参考图像。Q:使用VACE进行姿态控制时,身份失真(生成的人脸不像参考图像)怎么办?
A:降低--vace_scale参数(如从0.8调至0.5),VACE默认对人脸有控制偏向,过高的强度会覆盖Stand-In的身份保留逻辑;同时确保参考姿态视频/图像的姿态不要过于极端,避免模型难以平衡姿态与身份。Q:集成LoRA后,风格不明显或身份丢失怎么办?
A:调整--lora_scale参数(风格不明显则调高至1.2-1.5,身份丢失则调低至0.7-0.9);确保使用的LoRA模型与Wan2.1-14B-T2V兼容(官方推荐的吉卜力LoRA已验证兼容性);Prompt中避免同时添加过多风格描述与外貌描述,减少冲突。Q:生成视频的帧率较低或画面卡顿怎么办?
A:启用Flash Attention(参考环境搭建步骤4);降低输出视频的分辨率(可在脚本中添加--resolution 512x384等参数,默认分辨率较高);关闭不必要的优化选项(如--force_background_consistency)。
六、相关链接
项目GitHub仓库:https://github.com/WeChatCV/Stand-In
官方ComfyUI预处理节点:https://github.com/WeChatCV/Stand-In_Preprocessor_ComfyUI
VACE模型仓库(姿态控制依赖):https://github.com/VACE-team/VACE
推荐LoRA模型(吉卜力风格):https://civitai.com/models/1404755/studio-ghibli-wan21-t2v-14b
项目论文(arXiv):https://arxiv.org/abs/2508.07901
七、总结
Stand-In作为微信CV团队开源的轻量级身份控制视频生成框架,以“1%参数训练、即插即用、高保真度、强扩展性”为核心亮点,成功解决了传统视频生成中“身份与自然度难以兼顾”“功能单一难以扩展”的痛点。它无需复杂的硬件配置与代码重构,即可快速集成到文本到视频、风格化生成、人脸互换、姿态控制等多种场景,既满足了内容创作者“快速生成个性化视频”的需求,也为开发者与科研人员提供了轻量化身份控制的开源方案。无论是短视频创作、影视后期、虚拟人应用,还是技术研究与工具集成,Stand-In都以其高效、灵活、精准的特性,成为视频生成领域“身份控制”方向的实用工具,其开源生态的持续完善(如后续将发布的训练数据、完整ComfyUI节点)也将进一步降低使用门槛,推动身份保留视频生成技术的普及。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/stand-in.html





