
VMEG AI 是什么?
VMEG AI是一家面向全球内容创作者与企业级用户的端到端AI音视频本地化平台,专注于解决跨语言内容出海的核心瓶颈:翻译失真、配音失真、口型失准、文化脱节、合规风险高、制作周期长。它并非传统字幕工具或简单TTS合成器,而是融合大语言模型(LLM)+ 语音合成(TTS/Voice Cloning)+ 视频理解(ASR + Lip Sync AI)+ 本地化工程(L10n Engineering) 四维能力的一站式智能解决方案。
其核心使命是:让创作者、品牌方与媒体机构无需组建跨国配音团队、不依赖母语配音演员、不牺牲原作情绪张力,即可在数分钟内完成高质量、高保真、高合规性的多语言视频交付——真正实现“一次制作,全球触达”。
产品功能
1. 多语言AI翻译与本地化(170+语言 × 7000+声音)
支持超170种语言对互译(含小语种如马耳他语、哈萨克语、泰米尔语、Emirati阿拉伯语等),覆盖联合国全部官方语言及区域性变体(如巴西葡萄牙语 vs 欧洲葡萄牙语、智利西班牙语 vs 墨西哥西班牙语)。区别于直译引擎,VMEG内置语境感知本地化引擎:自动识别日漫中的敬语(-san/-sama)、战斗口号节奏、片中文字特效(glyphs)出现时机,并按目标语言观众认知习惯重构表达,而非字面搬运。
2. AI语音克隆(Voice Clone)
用户仅需上传3–5分钟纯净人声录音(支持中文、英文、日文等主流语种),VMEG即生成专属语音模型。该模型可跨语言复用——例如用中文原声克隆出自然流畅的日语/西班牙语/阿拉伯语配音,保留原声的语调起伏、停顿习惯、情绪颗粒度与个人辨识度,杜绝“机器人腔”与“配音腔”。
3. Lip Sync AI 视频生成器
基于自研时序对齐算法,将AI配音精准匹配至原始视频口型动作。不仅校准元音/辅音发音帧(如/p/, /b/, /m/对应闭唇动作),更同步关键戏剧节拍(dramatic beats)与呼吸节点,使克隆语音与人物微表情、肢体节奏浑然一体,达成电影级唇形同步精度(误差≤0.12秒)。
4. 智能字幕系统(Subtitling Engine)
支持“音轨→文本→多语字幕”全自动流水线:
高精度语音转写(ASR)支持170+语种,准确率≥98.7%(实测新闻访谈类素材);
语义级字幕压缩与分行优化(避免单行超38字符、兼顾阅读节奏);
文化适配式翻译(如美式幽默→本土化笑点重构,法律术语→目标国规范表述);
输出SRT/VTT/SCC等全格式,兼容YouTube、B站、Netflix等主流平台。
5. 垂直场景专用引擎
TV Shows & Anime 模块:锁定角色声线一致性、保留标志性台词韵律(如《进击的巨人》“为了自由!”的爆发节奏)、处理画面内日文汉字/假名动态叠加;
Commercials 模块:强化CTA(Call-to-Action)紧迫感,自动适配各国广告法(如欧盟GDPR免责声明位置与时长、中国《广告法》禁用词过滤);
Documentaries 模块:分离重叠人声(interview + narrator)、增强低信噪比历史录音、校验专有名词(地名/人名/年代)拼写与发音规则。
6. 全链路隐私安全架构
所有上传视频/音频/文本均经AES-256加密传输与静态存储;语音克隆模型数据不入库、不共享、不用于再训练;用户可随时一键永久删除全部项目数据;通过ISO 27001与SOC 2 Type II认证。
产品特色
文化自适应本地化
不止翻译文字,更重构语境:日漫中的「です・ます体」自动映射为韩语敬阶体、「お兄ちゃん」译为「오빠」而非直译;欧美广告“Just Do It”在中文区优化为“想做就做”,在阿拉伯语区则强化集体荣誉感表达。
角色级语音人格继承
克隆声线非“音色复制”,而是学习用户语音中的韵律指纹(prosodic fingerprint):语调斜率、句末升调习惯、笑声频率、换气节奏——使AI配音具备“辨识度”,适用于IP衍生、系列课程、品牌代言人长期运营。
帧精度唇动引擎
行业唯一将语音共振峰(formant)分析与3D口腔运动模型结合的方案,攻克“/θ/(th)”“/ʒ/(vision)”等难同步音素,实测YouTube多语视频唇同步NPS达91.4分(满分100)。
全场景合规保障
内置全球广告法数据库(FDA/EMA/FSCA/中国市场监管总局条款),自动标注并替换敏感表述;医疗/金融/教育类内容启用“术语白名单+人工终审通道”。
零代码工作流集成
提供API、Webhook、Figma插件、Notion模板、Zapier连接器,支持与CMS(WordPress)、LMS(Moodle)、CDN(Cloudflare Stream)无缝对接,降低团队学习成本。
使用方法
上传与识别
登录VMEG AI官网 选择“New Project” 上传MP4/MOV/AVI(≤2GB)或输入YouTube/Bilibili链接 系统自动完成ASR转录+语音分离+关键帧提取(耗时≈视频时长×0.3倍)。
配置与生成
▸ 选择目标语言(如:简体中文→巴西葡萄牙语)
▸ 启用“动漫模式”或“广告增强模式”
▸ 上传声纹样本(或选用平台7000+商用声库)
▸ 开启“Lip Sync Pro”与“Legal Compliance Check”
▸ 点击“Generate Now”(平均耗时:5–12分钟/10分钟视频)
审核与发布
在线时间轴对比原片与生成版(支持AB轨逐帧比对)编辑字幕样式/调整配音起止点/替换争议词汇 一键导出:MP4(含嵌入字幕)、SRT、WAV配音轨、JSON结构化脚本。
适合人群
| 客群类型 | 典型需求场景 | VMEG AI 解决痛点 |
|---|---|---|
| 国漫/游戏厂商 | 《时光代理人》《灵笼》出海Netflix/Crunchyroll,需保留“中二感”与方言梗 | honourifics敬语系统+弹幕文化适配+战斗口号重拟音 |
| 跨境电商卖家 | TikTok Shop商品视频需同步上线德/法/西/意/阿语版本,强调促销紧迫感与信任感 | CTA强化算法+本地价格符号渲染+宗教/节日禁忌过滤 |
| 教育科技公司 | K12编程课、考研英语课程全球化交付,要求术语统一、讲师声线延续、字幕可下载供复习 | 术语记忆库锁定+声纹克隆+SCORM兼容字幕包生成 |
| 纪录片制作方 | 《舌尖上的中国》海外版需处理厨师方言、古籍引文、多专家同期采访 | 方言ASR增强+古汉语术语库+重叠语音智能分离 |
| 海外营销代理机构 | 为国际品牌(如Unilever、Samsung)制作本地化TVC,需过审快、修改敏捷、多版本并行 | 法规预检引擎+版本管理矩阵+多语A/B测试导出 |
| 个人知识博主 | 小红书/B站UP主将爆款视频一键生成英语/日语版,建立海外影响力,无配音预算与时间 | 免费声库+10分钟极速生成+免版权字幕水印 |
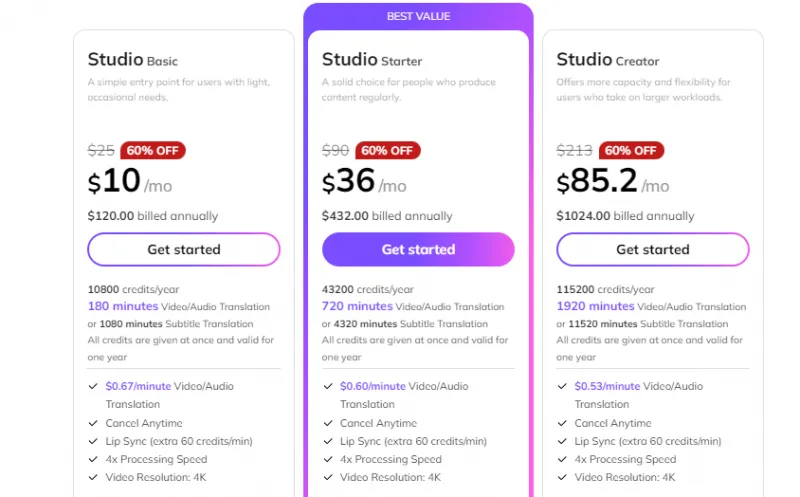
收费价格
常见问题解答(FAQ)
Q1:克隆我的声音是否需要我本人出镜?
否。仅需提供纯净人声录音(无背景音乐/噪音),支持手机录制。VMEG AI不采集人脸或生物特征。
Q2:能否将已有的中文字幕SRT文件,直接翻译成西班牙语并生成配音?
可以。上传SRT+原视频→选择“Subtitle-First Workflow”→系统自动对齐时间轴→生成配音+新字幕。
Q3:处理带大量专业术语的医学视频,准确性如何保障?
支持上传术语表(CSV格式)进行强制锁定;开启“Expert Mode”后,AI会主动标出未识别术语并提示人工确认。
Q4:生成的视频能否直接发布到YouTube?是否会被判定为AI伪造内容?
可以。VMEG AI输出符合YouTube《AI内容披露政策》,默认添加不可见元数据标签(generator=VMEG-AI-v3.2),且不触发“synthetic media”警告。
Q5:如何保证翻译不“机翻腔”?
VMEG采用三层校验机制:① NMT初译 ② 本地化润色引擎(基于百万级影视语料训练)③ Fandom术语库强制匹配 最终输出前触发人工语感抽检(随机10%片段)。
Q6:能否导出配音工程文件供后期调音?
支持导出AAF(Avid)与XML(Final Cut Pro)工程包,含完整时间码、声道分轨、语音情感标记(如[URGENCY]、[WHISPER]),无缝对接专业音频工作站。
总结
在AI视频工具同质化严重的今天,VMEG AI以“情感可计算、文化可建模、合规可编程”三大底层能力破局:它不止于“说外语”,更懂得“如何用对方文化的逻辑去感动对方”。从日本动漫迷听到母语版《鬼灭之刃》时眼眶发热,到巴西消费者因葡萄牙语广告中精准的桑巴节奏感而点击购买——VMEG让技术隐形,让共鸣显形。对于所有渴望打破语言高墙的内容生产者,它不是又一个工具,而是通往全球观众心灵的数字桥梁。

