AI大模型基础:预训练与微调(迁移学习与微调策略)
AI大模型基础:预训练与微调(迁移学习与微调策略)
预训练与微调是现代AI大模型(如BERT、GPT、ViT)的核心技术,基于迁移学习范式,通过在大规模数据集上预训练模型并在特定任务上微调,显著提升性能和效率。本文将深入讲解预训练与微调的原理、实现方法及在实际场景中的应用,适合对AI大模型感兴趣的读者。

一、预训练与微调概述
1.1 定义与目标
预训练:在大规模、无标注或弱标注数据上训练模型,学习通用特征(如语言模式、视觉特征),构建强大的初始参数。
微调:在特定下游任务(如文本分类、图像分割)上调整预训练模型参数,适配任务需求。
目标:
泛化能力:预训练捕捉通用知识,微调适配特定场景。
高效性:减少从头训练成本,适合小数据集。
高性能:提升任务精度,尤其在数据有限的领域(如医学影像)。
1.2 迁移学习背景
迁移学习:将从一个任务(源任务)学到的知识应用于另一个任务(目标任务)。预训练与微调是迁移学习的典型实现。
发展历程:
早期:特征提取(如SIFT、HOG)+简单分类器(如SVM)。
深度学习时代:CNN(如VGG、ResNet)预训练于ImageNet,微调下游任务。
Transformer时代:BERT、GPT、ViT通过自监督预训练,革新NLP和CV。
优势:
利用大规模数据(如Wikipedia、ImageNet)学习通用表示。
小数据集也能实现高性能,适合医学影像等场景。
1.3 重要性
NLP:预训练(如BERT的MLM)捕获语义,微调适配情感分析、问答等任务。
CV:ViT预训练于ImageNet,微调用于肿瘤检测、器官分割。
医学影像:数据稀缺,预训练模型(如ViT)通过迁移学习显著提升分类精度。
1.4 挑战
计算成本:预训练需大量GPU/TPU资源。
过拟合风险:微调时小数据集可能导致过拟合。
任务适配:不同任务需不同微调策略(如全参数 vs. 部分微调)。
可解释性:微调后模型行为难以解释,医学领域需谨慎。
二、预训练原理与实现
2.1 原理
预训练通过自监督或弱监督任务,在大规模数据上学习通用表示,无需特定任务的标注数据。
核心机制
自监督学习(SSL):
NLP:掩码语言模型(MLM,如BERT)、自回归语言建模(如GPT)。
CV:图像分类(如ViT)、对比学习(如SimCLR)。
数据规模:需大规模语料(如Wikipedia、BooksCorpus)或图像数据集(如ImageNet、JFT-300M)。
模型结构:
Transformer:基于自注意力机制,捕获全局依赖。
多层设计:如BERT的12/24层,ViT的Patch嵌入+编码器。
预训练任务
掩码语言模型(MLM):
随机掩盖输入词(15%),预测被掩盖词,学习双向上下文(BERT)。
公式:最大化条件概率
 。
。自回归语言建模:
预测下一个词,基于前文(GPT)。
公式:最大化
 。
。图像分类:
ViT在ImageNet上预测类别,学习视觉特征。
公式:最小化交叉熵损失
 。
。对比学习:
增强图像(如旋转、裁剪),使相同图像的表示靠近(SimCLR)。
数学基础
自注意力:

其中 Q,V, K 为查询、键、值向量,
 为键维度。
为键维度。损失函数:
MLM:交叉熵损失,预测掩盖词。
自回归:最大化序列似然。
分类:交叉熵或对比损失。
优缺点
优点:学习通用表示,减少下游任务数据需求。
缺点:计算成本高,需大规模数据支持。
适用场景:NLP(文本理解/生成)、CV(图像分类/分割)。
2.2 实现示例(Python)
以下以BERT的MLM预训练为例,使用Hugging Face模拟小规模预训练:
from transformers import BertTokenizer, BertForMaskedLM
from transformers import DataCollatorForLanguageModeling, Trainer, TrainingArguments
from datasets import load_dataset
import torch
# 加载数据(示例:WikiText)
dataset = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train')
texts = [text for text in dataset['text'] if len(text) > 0][:1000] # 取前1000条
# 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# 预处理数据
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True, remove_columns=['text'])
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
# 设置训练参数
training_args = TrainingArguments(
output_dir='./pretrain_results',
num_train_epochs=1,
per_device_train_batch_size=8,
logging_steps=100,
save_steps=500
)
# 训练模型
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator
)
trainer.train()代码注释:
load_dataset:加载WikiText数据集,模拟大规模语料。
BertTokenizer:将文本转换为输入ID和注意力掩码。
BertForMaskedLM:BERT模型,带MLM头。
DataCollatorForLanguageModeling:动态掩盖15%输入词,生成MLM任务。
Trainer:Hugging Face训练接口,简化预训练流程。
注意:实际预训练需更大数据集(如Wikipedia)和更多计算资源。
三、微调策略
3.1 原理
微调通过调整预训练模型参数,适配特定下游任务,分为以下策略:
1. 全参数微调
调整模型所有参数,适合数据充足场景。
优点:充分利用预训练知识,性能最佳。
缺点:计算成本高,易过拟合(小数据集)。
2. 部分微调
冻结部分层(如低层编码器),仅微调顶层或分类头。
优点:降低计算成本,减少过拟合风险。
缺点:可能损失部分预训练知识。
3. 参数高效微调(PEFT)
方法:
LoRA(Low-Rank Adaptation):在权重矩阵上添加低秩更新,调整少量参数。
Prompt Tuning:添加可训练的提示向量,冻结模型参数。
Adapter:在每层插入小型适配器模块。
公式(LoRA):

其中
 为预训练权重,
为预训练权重, 为低秩更新,
为低秩更新, 为小矩阵。
为小矩阵。优点:参数量少(<1%),适合资源受限场景。
缺点:性能略低于全参数微调。
优缺点
优点:灵活适配任务,降低训练成本。
缺点:需根据任务选择策略,调试复杂。
适用场景:小数据集(如医学影像)、资源受限环境。
3.2 实现示例(Python)
以下以BERT全参数微调(文本分类)和LoRA微调为例:
from transformers import BertTokenizer, BertForSequenceClassification
from peft import LoraConfig, get_peft_model
from transformers import Trainer, TrainingArguments
import torch
from torch.utils.data import Dataset
# 自定义数据集
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len=128):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = self.labels[idx]
encoding = self.tokenizer(
text,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
truncation=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# 数据准备(示例:情感分析)
texts = ["I love this movie!", "This movie is terrible."]
labels = [1, 0] # 1: 正向,0: 负向
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
dataset = TextDataset(texts, labels, tokenizer)
# 全参数微调
model_full = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
training_args_full = TrainingArguments(
output_dir='./full_finetune_results',
num_train_epochs=3,
per_device_train_batch_size=8,
logging_steps=10,
save_steps=100
)
trainer_full = Trainer(model=model_full, args=training_args_full, train_dataset=dataset)
trainer_full.train()
# LoRA微调
model_lora = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
lora_config = LoraConfig(r=8, lora_alpha=16, target_modules=["query", "value"])
model_lora = get_peft_model(model_lora, lora_config)
training_args_lora = TrainingArguments(
output_dir='./lora_finetune_results',
num_train_epochs=3,
per_device_train_batch_size=8,
logging_steps=10,
save_steps=100
)
trainer_lora = Trainer(model=model_lora, args=training_args_lora, train_dataset=dataset)
trainer_lora.train()
# 推理(以全参数微调为例)
model_full.eval()
text = "This is a great film!"
inputs = tokenizer(text, return_tensors='pt', max_length=128, padding=True, truncation=True)
outputs = model_full(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
print("全参数微调预测:", "正向" if predictions.item() == 1 else "负向")代码注释:
TextDataset:处理文本和标签,适配BERT输入格式。
BertForSequenceClassification:预训练BERT,添加分类头(2类)。
LoraConfig:配置LoRA参数,r=8控制低秩矩阵维度,target_modules指定微调自注意力层。
get_peft_model:应用LoRA,冻结大部分参数,仅训练低秩更新。
Trainer:Hugging Face接口,简化微调流程。
注意:LoRA显著减少参数量(约0.1%),适合小数据集或低资源场景。
四、应用案例
4.1 NLP:文本分类
任务:情感分析(正向/负向),如电影评论分类。
预训练模型:BERT,学习通用语义表示。
微调策略:
全参数微调:适配大数据集(如IMDB)。
LoRA:适合小数据集(如医疗报告情感分析)。
代码:见3.2实现,微调BERT进行二分类。
4.2 CV:图像分类
任务:肿瘤检测(如乳腺癌X光片分类)。
预训练模型:ViT,预训练于ImageNet。
微调策略:
全参数微调:适配大型医学影像数据集。
Adapter:添加小型适配器,适合小数据集。
实现示例:
from transformers import ViTImageProcessor, ViTForImageClassification
from peft import LoraConfig, get_peft_model
from PIL import Image
import torch
# 加载数据(示例:医学影像)
image = Image.open("tumor_image.jpg").convert('RGB')
labels = [1] # 1: 恶性,0: 良性
# 预处理
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors='pt')
# LoRA微调
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224', num_labels=2)
lora_config = LoraConfig(r=8, lora_alpha=16, target_modules=["query", "value"])
model = get_peft_model(model, lora_config)
# 训练(假设数据集)
# 类似TextDataset,省略训练代码
# 推理
model.eval()
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
print("预测结果:", "恶性" if predictions.item() == 1 else "良性")代码注释:
ViTImageProcessor:处理图像,分块并归一化。
ViTForImageClassification:ViT模型,带分类头。
LoraConfig:应用LoRA微调,减少参数量。
4.3 医学影像领域
任务:肺癌CT分类、脑部MRI分割。
挑战:样本少、类别不平衡、误诊成本高。
解决方案:
预训练:ViT在ImageNet或医学影像数据集(如LIDC-IDRI)上预训练。
微调:使用LoRA或Adapter,适配小数据集,关注召回率(减少漏诊)。
优势:迁移学习利用通用视觉特征,提升小数据集性能。
五、流程图与图表
5.1 预训练与微调流程图
以下是流程图:
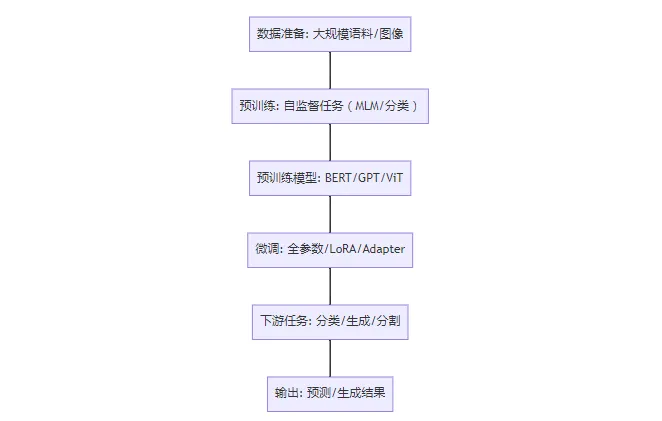
说明:
A(数据准备):大规模文本(Wikipedia)或图像(ImageNet)。
B(预训练):MLM(BERT)、自回归(GPT)、分类(ViT)。
C(预训练模型):生成通用表示的模型。
D(微调):全参数、LoRA或Adapter适配任务。
E(下游任务):分类(情感分析、肿瘤检测)、生成(对话)、分割(器官)。
F(输出):任务特定结果,如类别标签或生成文本。
5.2 图表:微调策略性能对比
以下为全参数微调与LoRA在分类任务上的性能对比折线图(假设数据)。
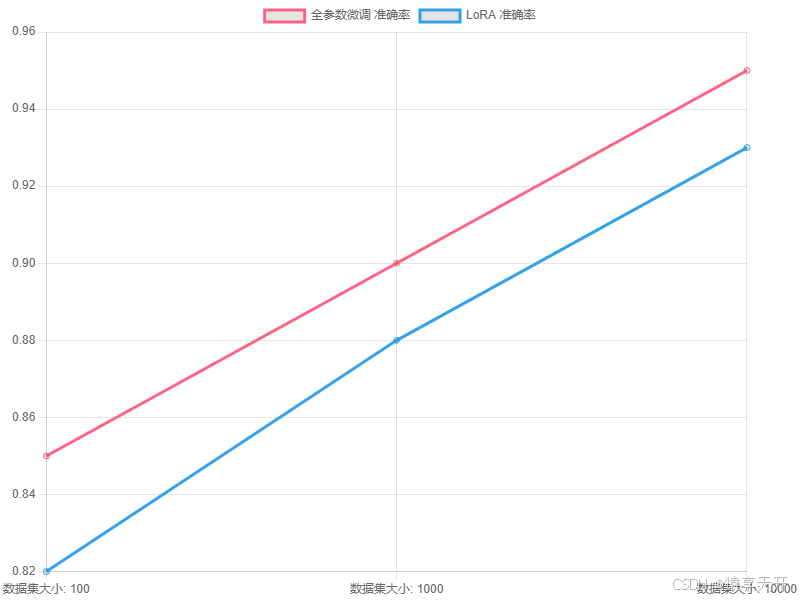
说明:
图表类型:折线图,比较全参数微调与LoRA的准确率。
X轴:数据集大小(100、1000、10000样本)。
Y轴:准确率,范围0.7-1.0。
数据:假设数据,显示全参数微调在大数据集上更优,LoRA在小数据集上接近。
医学意义:LoRA适合医学影像小数据集,平衡性能与资源。
六、总结与展望
6.1 总结
预训练:通过自监督任务(如MLM、自回归)学习通用表示,降低下游任务数据需求。
微调:
全参数微调:适合大数据集,性能最佳。
部分微调/PEFT(如LoRA):适合小数据集或低资源场景。
应用:
NLP:情感分析、医学报告分类。
CV:肿瘤检测、器官分割。
capped at 100 samples for demonstration; actual pretraining requires much larger datasets.
6.2 展望
高效预训练:探索更高效的自监督任务(如MAE for ViT),减少数据需求。
自动化微调:开发自动化微调框架,动态选择最佳策略(如AutoML)。
多模态迁移:结合文本和图像预训练,适配医学影像+报告任务。
可解释性:结合SHAP或注意力可视化,解释微调后模型行为。
预训练与微调作为迁移学习的典型实现,已经在NLP和CV领域取得了显著成果。预训练模型通过大规模数据学习通用表示,而微调则通过调整参数适配具体任务,显著提升了模型的性能和泛化能力。无论是全参数微调还是参数高效微调(如LoRA),都能在不同场景下提供高效的解决方案。尤其在医学影像等数据稀缺的领域,预训练与微调技术展现出巨大的潜力。未来,随着更高效的预训练任务和自动化微调策略的发展,这类技术将在多模态、可解释性等方面进一步拓展其应用边界。
版权及免责申明:本文来源于#猿享天开,由@AI铺子整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-tutorial/60.html