BERT 与 ELMo、GPT 有何不同?三大语言模型对比分析
在自然语言处理(NLP)领域的发展历程中,预训练语言模型的出现是具有里程碑意义的技术突破。2018年前后,ELMo、GPT和BERT三大模型相继问世,分别代表了预训练语言模型的三个重要技术分支,彻底改变了传统NLP任务依赖人工设计特征和特定任务模型的局面。三者在模型架构、上下文建模方式、预训练任务设计以及下游任务适配逻辑上存在本质差异,这些差异也决定了它们在不同NLP场景中的适用边界和性能表现。本文AI铺子将从技术原理、核心特性、优缺点及应用场景等维度,对三大模型进行全面对比分析。
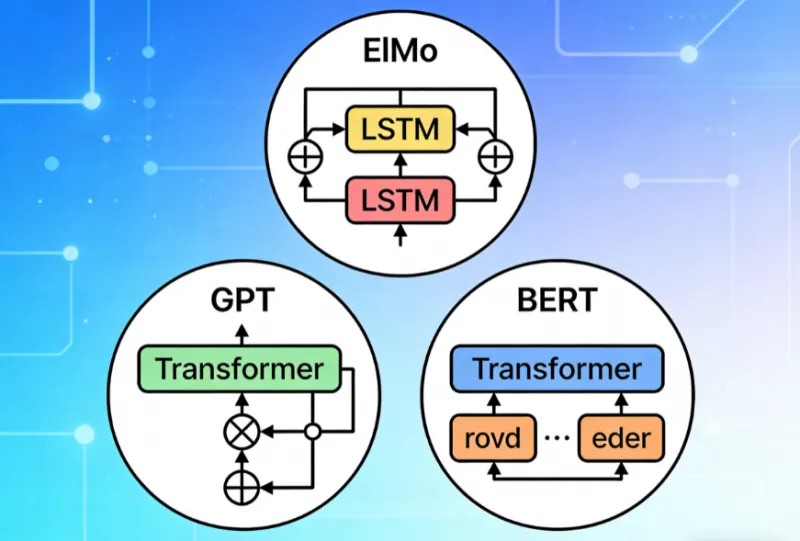
一、三大模型的技术原理与核心特性
1.1 ELMo:基于双向LSTM的上下文敏感词嵌入模型
ELMo(Embeddings from Language Models)由艾伦人工智能研究院于2018年提出,是首个真正意义上的深度上下文相关词嵌入模型,其核心目标是解决传统静态词向量(如Word2Vec、GloVe)无法处理一词多义的问题。
1.1.1 模型架构
ELMo的底层架构基于字符级CNN+双向LSTM构建,整体流程可分为三个阶段:
字符嵌入层:ELMo先将每个单词拆解为字符序列,通过字符嵌入矩阵将字符映射为低维向量,再利用多尺度CNN卷积核捕捉字符组合的形态学特征(如前缀、后缀、词根),最后通过全局最大池化将变长的卷积输出压缩为固定长度的字符级词表示,解决了未登录词(OOV)的处理难题。
Highway层:为缓解深层网络的梯度消失问题,ELMo在字符嵌入层后加入Highway层,通过Transform Gate和Carry Gate的门控机制,实现对原始字符特征的选择性过滤和增强,既保留基础特征又传递深层语义信息。
双向LSTM层:ELMo的核心是两层双向LSTM网络,包含一个前向LSTM和一个后向LSTM,且两层网络间设置残差连接。前向LSTM从左到右建模文本序列的上下文依赖,后向LSTM则从右到左建模,最终每个单词的表示由字符嵌入层、两层前向LSTM输出和两层后向LSTM输出共5个向量加权拼接而成。
1.1.2 预训练任务与表示生成逻辑
ELMo的预训练任务为双向语言模型(BiLM),其目标是同时最大化前向和后向语言模型的似然概率:
前向语言模型:给定前文序列
 ,预测当前词
,预测当前词 的概率
的概率 ;
;后向语言模型:给定后文序列
 ,预测当前词的概率
,预测当前词的概率 。
。
在下游任务中,ELMo并非作为端到端模型使用,而是作为特征提取器存在:先将任务数据输入预训练好的ELMo模型,得到每个单词的多层上下文嵌入,再将这些嵌入与任务模型的基础词向量拼接,共同参与下游任务的训练,且各层嵌入的融合权重会在下游任务中重新学习。
1.2 GPT:基于Transformer解码器的自回归生成模型
GPT(Generative Pre-trained Transformer)由OpenAI于2018年提出,是首个将Transformer架构与预训练-微调范式结合的生成式语言模型,开创了自回归预训练的技术路线。
1.2.1 模型架构
GPT彻底摒弃了传统的RNN/LSTM架构,完全基于Transformer解码器构建,其核心组件包括:
输入嵌入层:由词嵌入和位置嵌入相加而成,其中词嵌入采用BPE(字节对编码)分词算法处理文本,解决了词汇表大小与覆盖率的平衡问题;位置嵌入则为每个token分配固定的位置向量,弥补Transformer架构缺乏序列顺序信息的缺陷。
多层Transformer解码器:GPT-1包含12层Transformer解码器,每层由掩码多头自注意力机制和前馈神经网络组成。掩码自注意力机制确保模型在预测当前token时,只能关注到前文的token(即左向上下文),无法获取后文信息,这一设计是其自回归生成能力的核心。
输出层:通过线性层将解码器的隐藏状态映射到词汇表维度,再经Softmax函数得到下一个token的概率分布。
1.2.2 预训练任务与微调逻辑
GPT的预训练任务为自回归语言模型(CLM),其目标是最大化整个文本序列的生成概率 ,即通过前文token预测下一个token,让模型学习语言的生成逻辑和上下文关联。
,即通过前文token预测下一个token,让模型学习语言的生成逻辑和上下文关联。
在下游任务适配阶段,GPT采用统一的微调范式:针对不同的NLP任务(如文本分类、问答、自然语言推理),将任务数据转化为文本序列形式输入模型,再在解码器顶层增加任务特定的输出层(如分类层、问答匹配层),通过少量标注数据对整个模型进行微调,实现从通用语言模型到特定任务模型的迁移。
1.3 BERT:基于Transformer编码器的双向理解模型
BERT(Bidirectional Encoder Representations from Transformers)由谷歌于2018年提出,是NLP领域的革命性模型,其双向上下文建模能力大幅提升了各类理解类任务的性能上限。
1.3.1 模型架构
BERT基于Transformer编码器构建,其架构与GPT的解码器存在本质区别,核心组件包括:
多维度输入嵌入:BERT的输入嵌入由词嵌入、位置嵌入和段嵌入三部分相加而成。段嵌入用于区分输入中的不同句子(如句子对任务中的两个句子),这一设计使其能直接处理句间关系类任务。
多层Transformer编码器:BERT提供Base和Large两个版本,其中BERT-Base包含12层编码器、12个注意力头,BERT-Large包含24层编码器、16个注意力头。编码器中的多头自注意力机制为非掩码设计,模型可同时关注到当前token的左、右双向上下文,实现对语义的全面理解。
特殊token设计:BERT在输入序列开头添加
[CLS]token,其对应的隐藏状态可作为整个序列的聚合表示,用于分类等任务;同时用[SEP]token分隔不同句子,用[MASK]token实现掩码语言模型任务。
1.3.2 预训练任务与适配逻辑
BERT采用双预训练任务,分别从词级和句级层面学习语言知识:
掩码语言模型(MLM):随机将输入文本中15%的token替换为
[MASK]、随机token或保持原token,让模型预测被掩码的token,其目标是最大化 。这一任务迫使模型同时利用左右上下文信息,实现了真正的双向语义建模,解决了GPT单向建模的局限性。
。这一任务迫使模型同时利用左右上下文信息,实现了真正的双向语义建模,解决了GPT单向建模的局限性。下一句预测(NSP):构造句子对(A,B)作为输入,其中50%的B是A的真实下一句,50%的B是随机选取的句子,模型需预测B是否为A的下一句。该任务让模型学习到句子间的逻辑关联,适配自然语言推理、问答等句间关系类任务。
在下游任务适配中,BERT的微调方式更灵活:针对单句分类任务,直接取[CLS]token的隐藏状态进行分类;针对序列标注任务,取每个token的隐藏状态进行标签预测;针对句对任务,则结合[CLS]token和句间注意力信息完成任务,无需对输入格式进行复杂转换。
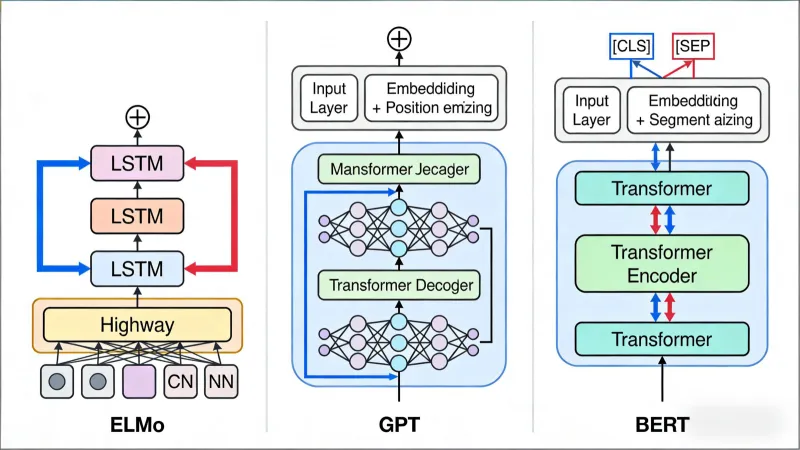
二、三大模型的核心差异对比
2.1 上下文建模方式差异
上下文建模能力是语言模型的核心竞争力,三大模型在这一维度的设计逻辑存在本质区别,直接决定了它们对语义的理解深度和适用场景:
ELMo的“伪双向”建模:ELMo的双向性由独立的前向和后向LSTM拼接实现,两个方向的网络无信息交互,属于“拼接式双向”,其上下文建模的粒度和关联性较弱,且LSTM的串行计算特性导致其难以捕捉长距离依赖关系。
GPT的“单向”建模:GPT的掩码自注意力机制仅允许模型关注前文token,属于“左向单向”建模,其优势是天然适配文本生成任务,但无法利用后文信息,在理解类任务中存在语义信息缺失的缺陷。
BERT的“真双向”建模:BERT的非掩码自注意力机制让模型可同时获取左右双向的上下文信息,属于“融合式双向”建模,能更精准地捕捉一词多义、长距离语义关联等复杂语言现象,是理解类任务的最优选择。
2.2 预训练任务设计差异
预训练任务决定了模型学习到的语言知识类型,三大模型的任务设计各有侧重:
| 模型 | 核心预训练任务 | 学习目标 | 知识覆盖范围 |
|---|---|---|---|
| ELMo | 双向语言模型 | 预测当前词的前向和后向概率 | 词级上下文关联、基础语法规则 |
| GPT | 自回归语言模型 | 基于前文预测下一个token | 文本生成逻辑、序列连贯性 |
| BERT | 掩码语言模型+下一句预测 | 预测掩码token、判断句间关系 | 词级双向语义、句间逻辑关联 |
从任务设计的完整性来看,BERT的双任务组合覆盖了词级和句级的语言知识,而ELMo和GPT的单任务仅能学习单一维度的语言规律,这也是BERT能适配更多下游任务的关键原因。
2.3 下游任务适配逻辑差异
三大模型在下游任务的适配方式上存在显著差异,直接影响了任务迁移的效率和效果:
ELMo的“特征注入”模式:ELMo仅作为特征提取器,不参与下游任务的端到端训练,需将其生成的上下文嵌入与任务模型的特征拼接后使用。这种模式的优点是轻量化、易部署,缺点是无法实现模型的全局优化,任务适配能力有限。
GPT的“统一序列”模式:GPT将所有下游任务转化为文本生成类的序列任务,通过统一的微调流程适配不同场景。这种模式的优点是任务适配逻辑简单,缺点是对非生成类任务的适配性较差,且微调时需修改整个模型的参数,计算成本较高。
BERT的“任务定制”模式:BERT针对不同任务设计了差异化的输出层,仅需微调顶层的任务特定参数即可实现迁移,且双向上下文表示能直接适配各类理解类任务。这种模式的优点是迁移效率高、任务性能优,缺点是对生成类任务的支持不足。
2.4 性能与优缺点差异
三大模型在不同NLP任务中的性能表现和自身优缺点存在明显边界,具体如下:
ELMo
优势:生成的词嵌入具有上下文敏感性,可有效处理一词多义问题;字符级输入能解决未登录词问题;模型体量较小,部署成本低。
劣势:仅能作为特征提取器,无法端到端训练;双向LSTM的串行计算效率低,长文本建模能力弱;任务适配灵活性差,性能上限低于Transformer类模型。
典型任务性能:在早期的命名实体识别、情感分析任务中,相比静态词向量有1-3个百分点的提升,但远落后于BERT和GPT。
GPT
优势:基于Transformer解码器的自回归架构,文本生成能力突出,生成的文本流畅度高;预训练-微调范式可实现跨任务迁移;后续版本(如GPT-3)具备零样本/少样本学习能力,降低了标注数据依赖。
劣势:单向上下文建模导致理解类任务性能不足;生成过程为逐token预测,推理速度慢;模型参数量大,训练和部署成本高。
典型任务性能:在文本生成、对话系统任务中表现优异,但在问答、自然语言推理等理解类任务中,准确率比BERT低5-10个百分点。
BERT
优势:双向上下文建模使其在各类理解类任务中达到SOTA性能;灵活的微调方式适配多类任务;模型架构可扩展性强,衍生出RoBERTa、ALBERT等改进模型。
劣势:MLM任务存在预训练-微调的掩码不一致问题;无生成能力,无法直接用于文本生成;大模型版本(如BERT-Large)的计算和内存开销大。
典型任务性能:在文本分类、问答、命名实体识别等任务中,相比传统模型提升10-20个百分点,成为理解类任务的基准模型。
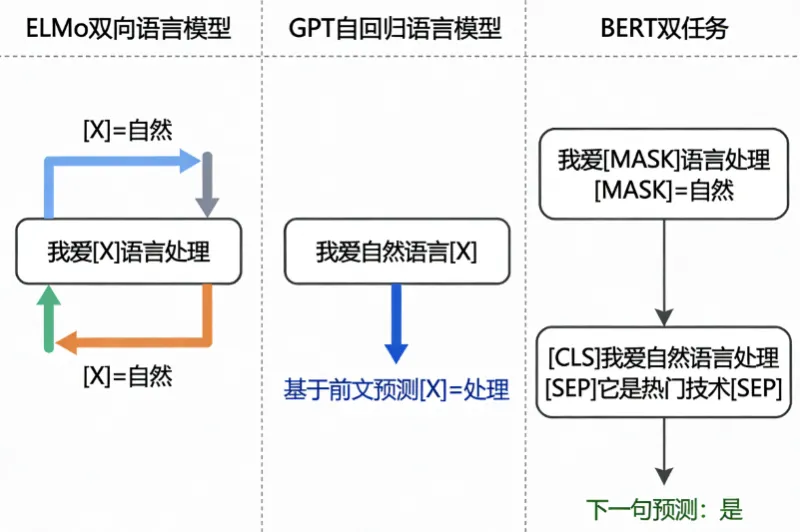
三、三大模型的应用场景划分
基于上述技术特性和性能差异,三大模型的应用场景存在明确的边界,需结合任务类型和资源条件进行选择:
3.1 ELMo的适用场景
ELMo的核心价值在于轻量化的上下文词嵌入生成,适用于以下场景:
低资源NLP任务:在标注数据和计算资源有限的场景下,可将ELMo生成的上下文嵌入作为基础特征,快速提升传统任务模型的性能,如小语种的情感分析、低资源领域的命名实体识别。
词向量相关研究:ELMo的上下文敏感词嵌入可用于词义消歧、词汇语义相似度计算等基础语言学研究,为后续模型提供对比基准。
嵌入式NLP系统:在算力受限的嵌入式设备中,ELMo的小体量优势明显,可作为轻量级特征提取器嵌入终端NLP应用,如智能音箱的基础语义理解模块。
3.2 GPT的适用场景
GPT的核心优势是文本生成能力,适用于以下场景:
创意内容生成:包括小说续写、诗歌创作、营销文案生成等,利用其自回归生成能力产出连贯且符合语境的文本,如电商平台的商品标题生成、自媒体的文章初稿创作。
对话交互系统:构建智能客服、聊天机器人等对话系统,GPT可基于用户的历史对话生成自然的回复,实现多轮上下文关联的交互,如企业的智能售后咨询机器人。
零样本/少样本任务:在标注数据稀缺的专业领域,利用GPT的大模型版本(如GPT-3)的零样本学习能力,直接通过提示词完成任务,如医疗领域的病历文本结构化、法律领域的条款分类。
3.3 BERT的适用场景
BERT的核心竞争力是双向语义理解,适用于以下场景:
文本理解类任务:包括文本分类(如新闻类别划分、情感倾向判断)、自然语言推理(如蕴含关系识别、矛盾检测)、信息抽取(如实体关系抽取、事件抽取)等,是这类任务的首选模型。
问答系统构建:在知识库问答、阅读理解等任务中,BERT可精准理解问题和文本的双向语义关联,实现答案的精准定位,如智能教育平台的答疑系统、搜索引擎的问答模块。
序列标注任务:在命名实体识别、词性标注、语义角色标注等任务中,BERT的双向上下文表示能提升标签预测的准确率,如金融领域的实体识别、法律文本的条款标注。

四、总结
ELMo、GPT和BERT作为预训练语言模型的三大里程碑,分别代表了“上下文词嵌入”“自回归生成”和“双向语义理解”三个技术方向,其核心差异可总结为以下三点:
技术架构:ELMo基于双向LSTM,GPT基于Transformer解码器,BERT基于Transformer编码器,架构差异决定了模型的计算效率和上下文建模能力;
学习范式:ELMo是“预训练特征提取”,GPT是“预训练-生成式微调”,BERT是“预训练-理解式微调”,学习范式差异影响了任务适配的灵活性和性能上限;
能力边界:ELMo擅长基础语义特征生成,GPT擅长文本生成和零样本任务,BERT擅长各类理解类任务,能力边界差异决定了它们在实际应用中的场景划分。
三大模型的技术演进,不仅推动了NLP领域的快速发展,也为后续大语言模型的研发奠定了核心基础,其设计理念和技术逻辑至今仍对NLP技术的发展具有重要的参考价值。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-tutorial/how-is-bert-different-from-elmo-gpt.html





