Emu3.5:北京智源开源的原生多模态世界模型
一、Emu3.5是什么
Emu3.5(又称“悟界·Emu3.5”)是由北京人工智能研究院(BAAI)研发并开源的大规模原生多模态世界模型,其基于单一340亿参数Transformer架构,以“下一状态预测(NSP)”为核心训练目标,在超13万亿多模态Token(含790年时长视频及对应转录文本)上完成端到端预训练。该模型突破了传统多模态模型“模态割裂”“推理低效”“缺乏时空因果”的痛点,实现了图像、文本、视频的统一建模与生成,同时通过离散扩散适配(DiDA)技术将图像推理速度提升20倍。其具备长视野视觉-语言生成、任意到图像合成、具身智能指导、虚拟世界探索等核心能力,可广泛应用于内容创作、机器人操控、虚拟仿真等领域,且已开源代码与模型权重,为多模态AI研究与落地提供了高效且通用的开源工具。
研发背景
在AI多模态领域,传统模型存在三大核心痛点:一是模态割裂,需为图像、文本、视频分别设计专用模块,无法实现原生的跨模态交互;二是缺乏时空因果,仅能完成短序列的静态内容生成,难以理解“杯子落地会碎”“炒菜需先倒油”这类物理规律与步骤逻辑;三是推理效率低,自回归模型逐Token生成的模式导致图像生成耗时过长,无法满足实时应用需求。
在此背景下,BAAI团队延续Emu3“单一自回归目标统一多模态任务”的技术路线,通过扩大模型规模、升级训练数据、创新推理加速技术,推出了Emu3.5,首次实现了多模态模型从“任务工具”到“世界理解与交互载体”的跃迁。
核心定位
Emu3.5的核心定位是“多模态世界模型”,其目标并非单纯生成高质量图像,而是让AI学会“理解世界、预测变化、指导交互”。例如输入“如何制作虾仁芹菜饺子”的指令,模型不仅能输出文字步骤,还能按逻辑生成从备料、拌馅、包饺子到煮制的连贯视觉序列,且每一步都符合真实的烹饪物理规律与时空顺序。

二、Emu3.5核心功能特色
Emu3.5的功能特色围绕“原生多模态统一”“时空因果连贯”“高效推理”“通用任务适配”四大维度展开,具体如下:
1. 真正的原生多模态统一I/O
不同于传统多模态模型依赖“模态适配器”或“任务专用头”的拼接式架构,Emu3.5从输入阶段就将所有模态转化为统一的离散Token序列。无论是单张图像、长文本描述,还是多帧视频,都能在同一个Transformer架构中完成编码、理解与生成,支持“文本→图像→文本→视频”的交错式输入输出。例如用户可先上传一张“松鼠在草地”的照片,再输入文本指令“将背景换成雪地并添加落日光影”,模型能直接生成符合要求的新图像,且松鼠的姿态、毛发质感与新场景的光影完全适配,无“拼贴感”。
2. 时空连贯的世界规律建模
依托“下一状态预测(NSP)”的训练目标,Emu3.5可学习物理世界的时空连续性与因果逻辑,而非仅模仿像素或文本的表面关联。其能力体现在两个层面:一是长序列视觉叙事,能生成5分钟以上的连贯视觉故事,且前后帧的物体位置、光影、逻辑保持一致,如生成“卧室→逐步进入房间→调整家具→模拟100年后房间状态”的完整探索序列;二是物理因果推理,可识别并遵循真实世界的物理规则,例如指导机器人折叠T恤时,会生成“左手抓左下衣角→右手抓右下衣角→同步向上折叠”的符合力学的步骤,避免出现“抓空”“穿模”等物理错误。
3. 20倍提速的高效推理能力
针对自回归模型“图像生成慢”的行业痛点,Emu3.5创新提出**离散扩散适配(DiDA)**技术,将传统的“逐Token串行解码”转化为“双向并行预测”,在不损失生成质量的前提下,将单张图像的推理速度提升约20倍,达到闭源扩散模型的实用级效率。实测数据显示,传统自回归模型生成一张512×512的图像需51秒,而Emu3.5通过DiDA加速后仅需2.2秒,可满足机器人实时操控、在线内容生成等低延迟场景需求。
4. 泛化性强的具身智能指导
Emu3.5突破了多模态模型“仅能生成虚拟内容”的局限,可直接为真实机器人提供视觉-语言操控指导,解决了传统模型“步骤断片”“物理错误”“延迟过高”的三大痛点。在实测中,其指导家用Songling Aloha机器人折叠T恤的7步全对率从30%提升至60%,指导工业Agibot双臂机器人完成12步餐桌清理任务的成功率达82%(传统模型仅40%),且指导延迟从50秒压缩至2秒,实现了机器人操控的实时性与准确性统一。
5. 高精度的任意到图像(X2I)生成
在图像生成与编辑领域,Emu3.5支持多类X2I任务,且细节还原度与指令对齐度表现优异:一是精准内容编辑,可实现“添加物体”“替换背景”“修复老照片”等操作,如将鼓楼夜景从仰视视角改为鸟瞰视角时,能自动补全周边建筑与道路,保持场景逻辑一致;二是高保真文本渲染,可生成包含复杂文字的图像,如带“π=3.1415926535”数学公式的黑板、含“欢迎回家”霓虹灯牌的城堡,字符清晰度达印刷级标准;三是跨风格迁移,能根据指令生成迪士尼动画、写实油画、赛博朋克等多样风格的图像,且风格统一无割裂感。
三、Emu3.5技术细节
1. 模型架构与核心参数
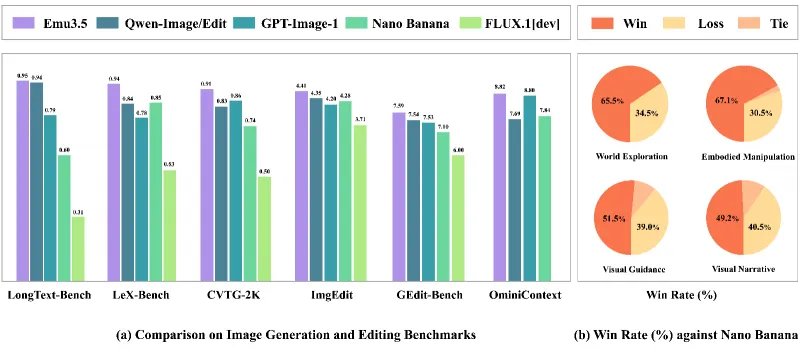
Emu3.5采用纯Transformer解码器架构,未引入任何专用模态处理模块,其核心参数相较于前代Emu3实现了全方位升级,具体对比如下表1所示:
| 参数维度 | Emu3(2024版) | Emu3.5(2025版) | 升级价值 |
|---|---|---|---|
| 模型参数量 | 80亿 | 340亿(312亿Transformer+29亿嵌入层) | 支撑长序列时空建模与复杂因果推理 |
| Transformer层数 | 32层 | 64层 | 提升特征抽象能力,适配高分辨率视觉信号 |
| 隐藏层维度 | 4096 | 5120 | 扩大特征容量,增强多模态信号融合精度 |
| 注意力头配置 | 32个Q头/8个KV头 | 64个Q头/8个KV头 | 提升细粒度注意力分配,优化文本渲染与局部编辑 |
| 词汇表规模 | 18.4万(混合视觉/文本) | 28.3万(15.2万文本+13.1万视觉) | 分离视觉/文本嵌入,减少模态干扰,提升细节表达 |
| 最大上下文长度 | 131072 Token | 32768 Token | 结合视频交错打包技术,实现5分钟长视频建模 |
| 支持最高分辨率 | 720×720(图像) | 2048×2048(图像)/1080p(视频) | 满足高清内容生成与编辑需求 |
表1:Emu3与Emu3.5核心参数对比表
此外,Emu3.5在架构上新增两项关键优化:一是QK-Norm归一化,解决长序列训练中注意力矩阵不稳定的问题;二是分离式视觉/文本嵌入层,避免不同模态Token的特征干扰,同时从SigLIP模型蒸馏视觉特征,提升Token的语义表达能力。
2. 训练数据与训练流程
(1)训练数据规模与构成
Emu3.5的训练数据总量达13万亿Token,分为两阶段构建,核心数据为“视频-文本交错序列”,具体构成如下:
第一阶段(10万亿Token):以通用多模态数据为主,包含5亿+图像-文本对、3000万+短视频、6300万条“视频帧+ASR转录文本”交错序列,其中视频总时长超790年,覆盖教育、烹饪、工业操控、娱乐等12大领域,且通过PySceneDetect完成智能场景分割,保留核心视觉信息,剔除冗余帧;
第二阶段(3万亿Token):以高质量数据为主,包含2735万条X2I专用数据、高分辨率图像数据及精细标注数据(如语义分割、多模态总结),通过CLIP美学评估与SimHash去重技术,过滤低质与冗余内容,确保数据的有效性。
该数据体系的核心优势是“时空连贯性”,例如“炒菜”视频会按“倒油→热油→下菜→翻炒”的时序提供帧与文本的对应关系,让模型自然学习到真实世界的步骤逻辑与物理规律。
(2)四阶段训练流程
Emu3.5采用“预训练→监督微调(SFT)→强化学习(RL)→DiDA适配”的四阶段训练流程,实现从“基础能力”到“任务适配”再到“高效推理”的能力跃迁:
大规模预训练:在13万亿Token数据上执行“下一状态预测(NSP)”任务,让模型学习多模态对齐关系与世界基本规律,此阶段不区分具体任务,仅强化通用建模能力;
两阶段监督微调:先在标准分辨率数据上统一多任务接口,再在高分辨率数据上提升细节生成质量,使模型学会遵循人类指令,实现X2I、视觉叙事等任务的精准对齐;
多模态强化学习:基于“美学质量+指令对齐+物理一致性”的多维奖励系统,采用GRPO算法优化模型,使其生成内容更符合人类偏好,且规避物理错误;
DiDA推理适配:在130亿Token的微调数据上完成DiDA技术适配,将自回归串行生成转化为并行生成,实现推理效率的大幅提升。
3. 核心技术原理
(1)下一状态预测(NSP)
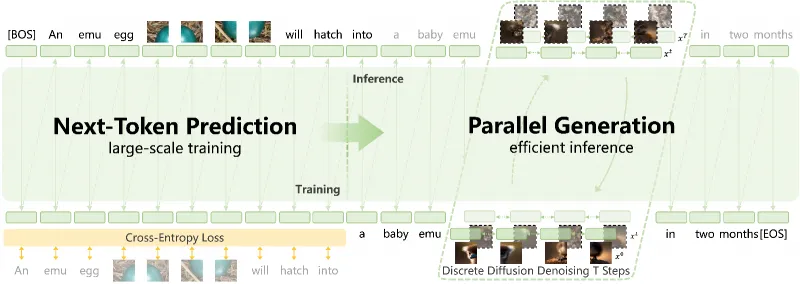
NSP是Emu3.5区别于传统“下一个Token预测(NTP)”的核心创新。传统NTP仅预测序列中的单个Token,而NSP以“完整状态”为预测单元,例如对于“视频帧A→文本描述A→视频帧B”的序列,NSP会直接预测“视频帧B+对应文本描述B”的完整状态,而非逐Token生成。这一目标迫使模型必须学习帧间的时空关联、物体的运动规律及事件的因果逻辑,从而具备世界建模能力。
(2)离散扩散适配(DiDA)
DiDA是解决自回归模型推理低效的关键技术,其核心逻辑是“将串行Token生成转化为并行状态优化”:首先为视觉Token添加可控噪声,再通过双向扩散模型同步优化所有Token的状态,最后通过去噪得到完整的视觉序列。该技术不改变模型的预训练能力,仅在推理阶段做适配,实现了“速度提升20倍”与“质量无损失”的平衡,让自回归模型首次具备媲美闭源扩散模型的实用效率。
4. 模型权重类型
Emu3.5开源了三类模型权重,适配不同任务场景,具体如下表2所示:
| 权重名称 | 核心定位 | 适用场景 | 关键优势 |
|---|---|---|---|
| Emu3.5 | 通用多模态预测 | 交错视觉-文本生成、X2I、视觉叙事 | 兼顾多任务能力,支持复杂多模态交互 |
| Emu3.5-Image | 专用图像生成 | 文本到图像(T2I)、图像编辑、高分辨率生成 | 优化图像细节与风格一致性,文本渲染精度高 |
| Emu3.5-VisionTokenizer | 视觉Token化工具 | 多模态数据预处理、第三方模型适配 | 压缩效率高,1024×1024图像仅需1024个Token |
表2:Emu3.5模型权重类型与适配场景表
四、Emu3.5典型应用场景
Emu3.5的能力覆盖“虚拟内容创作”“真实世界交互”“学术研究”三大领域,以下为典型应用场景及案例:
1. 高质量内容创作与编辑
在内容创作领域,Emu3.5可满足自媒体、设计师、文创从业者的多样化需求:
商业海报生成:输入“为咖啡新品设计海报,背景为秋日落叶,包含‘秋日限定’艺术字,风格为日系治愈风”,可直接生成符合品牌调性的高清海报,且文字与图像融合自然;
老照片修复与重绘:上传泛黄的黑白家庭老照片,指令“还原色彩并添加复古相框,背景替换为老上海街景”,模型可精准还原人物面部细节,且新背景与人物的光影、年代感保持一致;
多模态教程制作:为烹饪博主生成“虾仁芹菜饺子”的图文教程,不仅输出步骤文字,还能生成每一步的实景图,且步骤逻辑与物理操作完全匹配,可直接用于视频剪辑素材。
2. 长时程视觉叙事与知识科普
Emu3.5的时空连贯能力使其成为知识科普与故事创作的高效工具:
教育类视觉叙事:为中小学物理课生成“杠杆原理实验”的动态视觉序列,从“搭建支架→悬挂砝码→观察平衡”逐步展示,且每一步都标注物理公式与原理,实现“可视化教学”;
虚构故事创作:输入“写一个‘小狐狸与女孩的厨房冒险’故事,并生成对应插画”,模型可输出连贯的文字故事,同时生成多幅风格统一的插画,且插画的场景、人物服饰与故事剧情完全匹配。
3. 机器人具身智能操控指导
Emu3.5的物理因果能力可直接赋能工业与家用机器人,解决传统操控模型的痛点:
家用机器人任务:指导Songling Aloha机器人完成“折叠T恤”任务,生成“左手抓左下衣角→右手抓右下衣角→同步上折→整理领口”的7步视觉-语言指导,物理错误率从45%降至12%,抓握成功率从50%提升至85%;
工业机器人任务:为Agibot双臂机器人提供“餐桌清理”指导,不仅生成连贯的12步动作序列,还能在机器人漏拿餐巾时自动补全中间步骤,任务完成率从40%提升至82%。
4. 虚拟世界探索与仿真
Emu3.5可构建具备时空一致性的虚拟世界,支持沉浸式探索与未来场景模拟:
虚拟场景漫游:先生成“复古卧室”的初始图像,再通过“向前走→左转→打开抽屉→查看窗外”的指令,逐步生成连贯的视角切换图像,构建可“行走”的虚拟空间;
未来场景预测:输入“预测该卧室100年后的样子”,模型可基于时代演变规律,生成“智能家具替换老式家具、墙面出现科技感装饰、窗外建筑现代化”的合理场景,且保持房间的核心结构不变。
五、Emu3.5使用方法
1. 环境配置要求
Emu3.5对软硬件有明确要求,基础环境配置步骤如下:
(1)硬件要求
显卡:需NVIDIA GPU,显存≥24GB(推荐A100、RTX 3090及以上型号,多卡可提升高分辨率生成效率);
内存:主机内存≥64GB,确保数据加载与模型运行的稳定性;
存储:预留≥200GB空间,用于存放模型权重、数据集及输出结果。
(2)软件环境配置
Emu3.5要求Python 3.12及以上版本,具体依赖安装步骤如下:
# 1. 克隆开源仓库 git clone https://github.com/baaivision/Emu3.5 cd Emu3.5 # 2. 安装基础依赖 pip install -r requirements/transformers.txt # 3. 安装flash_attn加速库(必装,提升注意力计算效率) pip install flash_attn==2.8.3 --no-build-isolation # 4. 可选:安装vLLM依赖(用于离线高效推理) pip install -r requirements/vllm.txt
2. 模型权重获取
Emu3.5的模型权重托管于Hugging Face平台,用户可通过两种方式获取:
直接下载:访问Emu3.5 Hugging Face仓库,根据需求下载对应权重(如Emu3.5-Image适用于图像生成);
代码自动加载:在推理脚本中配置Hugging Face仓库地址,运行时自动下载权重,示例代码片段如下:
from src.modeling_emu import EmuForCausalLM
from src.tokenization_emu import EmuTokenizer
# 加载tokenizer与模型
tokenizer = EmuTokenizer.from_pretrained("baaivision/Emu3.5")
model = EmuForCausalLM.from_pretrained("baaivision/Emu3.5", device_map="auto")3. 基础推理流程
Emu3.5支持多种任务的推理,以“文本到图像(T2I)”为例,具体步骤如下:
(1)配置推理参数
编辑仓库内configs/config.py文件,核心参数设置如下:
# 任务类型:t2i为文本到图像,x2i为任意到图像,interleave为交错生成 task_type = "t2i" # 模型权重路径(本地路径或Hugging Face仓库名) model_path = "baaivision/Emu3.5-Image" # 生成图像分辨率 image_size = (1024, 1024) # 采样步数(DiDA加速下可设为4步,平衡速度与质量) sample_steps = 4
(2)运行推理脚本
执行以下命令启动推理,生成对应图像:
python inference.py --cfg configs/config.py
(3)自定义指令输入
在推理过程中,可通过命令行或脚本传入自定义指令,例如输入“迪士尼风格的橙色狐狸与辫子女孩在厨房做蛋糕”,模型将自动生成符合要求的图像。
4. 交互式演示工具
Emu3.5提供Gradio交互式演示工具,支持可视化操作,具体启动命令如下:
(1)图像生成专用演示
# 支持T2I/X2I,需双卡GPU(单卡可调整参数) CUDA_VISIBLE_DEVICES=0,1 python gradio_demo_image.py --host 0.0.0.0 --port 7860
(2)交错生成演示(支持视觉叙事/世界探索)
CUDA_VISIBLE_DEVICES=0,1 python gradio_demo_interleave.py --host 0.0.0.0 --port 7860
启动后,用户可在浏览器访问http://localhost:7860,通过可视化界面输入指令、上传图像,实时查看生成结果。
六、常见问题解答(FAQ)
Q1:安装flash_attn时出现编译错误,如何解决?
A1:flash_attn依赖CUDA环境,需确保本地CUDA版本≥11.7,且PyTorch版本与CUDA版本匹配;若编译失败,可尝试安装预编译版本:pip install flash-attn --no-build-isolation --find-links https://flash-attn.s3.amazonaws.com/wheels.html。
Q2:运行时提示“显存不足”,如何优化?
A2:可通过以下方式降低显存占用:① 降低生成图像分辨率(如从1024×1024改为512×512);② 启用模型量化(加载权重时添加load_in_4bit=True参数);③ 采用vLLM推理框架(可大幅降低显存占用,且提升推理速度)。
Q3:为何我的推理速度未达到官方宣称的20倍提升?
A3:DiDA加速需加载专用适配权重,且需启用vLLM推理框架;若使用基础自回归推理,无法实现加速。可切换至inference_vllm.py脚本,并确保权重包含DiDA适配模块。
Q4:生成的图像存在文字模糊、人脸失真问题,如何优化?
A4:可启用模型的“扩散解码器”选项(在config中设置use_diffusion_decoder=True),该解码器通过LoRA蒸馏技术优化细节,能显著提升文本渲染与面部生成质量,但会增加少量推理耗时。
Q5:Hugging Face下载权重速度慢,有无替代方案?
A5:可通过国内镜像源(如ModelScope)获取权重,访问Emu3.5 ModelScope仓库即可下载,且支持与Hugging Face相同的加载方式。
Q6:能否使用自定义数据集对Emu3.5进行微调?
A6:支持自定义微调,需将数据集转化为“视觉-文本交错Token序列”格式,并参考仓库内finetune.py脚本完成微调;建议先使用小批量数据测试,且微调时需保留NSP训练目标,以维持模型的世界建模能力。
Q7:如何将Emu3.5用于机器人操控任务?
A7:需先将机器人的操控数据转化为“动作帧+文本指令”的交错序列,对模型进行任务专用微调,再通过实时推理接口将模型生成的视觉-语言步骤传输至机器人控制系统;仓库内提供了机器人任务的微调示例脚本(finetune_embodied.py),可直接参考适配。
七、相关链接
模型权重(Hugging Face):https://huggingface.co/baaivision/Emu3.5
国内镜像仓库(ModelScope):https://modelscope.cn/models/baaivision/Emu3.5/summary
八、总结
Emu3.5是一款由北京智源研究院研发的开源原生多模态世界模型,其以340亿参数的纯Transformer架构为基础,通过“下一状态预测”的统一训练目标和超13万亿多模态Token的端到端训练,实现了图像、文本、视频的原生统一建模,同时依托DiDA技术解决了自回归模型推理低效的行业痛点。该模型不仅具备高质量的图像生成与编辑能力,还能通过学习物理世界的时空因果规律,为机器人具身操控、虚拟世界探索等真实交互场景提供连贯指导,其开源的代码与权重为多模态AI的研究与落地提供了高效且通用的工具,既填补了“世界模型”类开源工具的空白,又为多模态Scaling范式的验证提供了重要实践载体,在内容创作、工业智能、教育科普等领域具备极高的实用价值与研究意义。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/emu3-5.html





