HunyuanOCR:腾讯混元开源的轻量高效多模态OCR大模型,全场景多语种图文智能解析
一、HunyuanOCR是什么?
HunyuanOCR是腾讯混元团队推出的一款端到端OCR专家型多模态大模型(VLM),基于混元原生多模态架构与专属训练策略打造,核心定位是“以轻量化参数实现全场景OCR任务的高精度处理”。
与传统OCR工具(如PaddleOCR)需分步骤完成“检测-识别-后处理”不同,HunyuanOCR贯彻大模型“端到端”设计理念,用户通过单一指令即可直接输出最终结果;同时,其仅1B的参数规模,相较于同类大模型(如Qwen3-VL-235B、Gemini-2.5-Pro)大幅缩减,却在文字检测、文档解析、信息抽取等核心任务中达到甚至超越同类产品性能,显著降低了部署门槛与硬件成本。
该项目于2025年11月25日正式开源,同步发布了推理代码、模型权重、技术报告及详细使用文档,支持开发者通过Hugging Face直接调用模型,或基于vLLM/Transformers框架本地部署,覆盖从个人开发到企业级应用的全场景需求。其核心目标是打破传统OCR工具的功能局限与部署复杂度,提供一款“轻量化、全功能、高易用”的开源OCR解决方案。
二、功能特色
HunyuanOCR的核心优势集中在“轻量化、全功能、高易用、广覆盖”四大维度,具体功能特色如下:
1. 高效轻量化架构:1B参数实现SOTA性能
HunyuanOCR采用混元原生多模态架构,通过优化训练策略(如多任务联合训练、模态融合增强),在仅1B参数规模下,实现了远超同量级模型的性能表现:
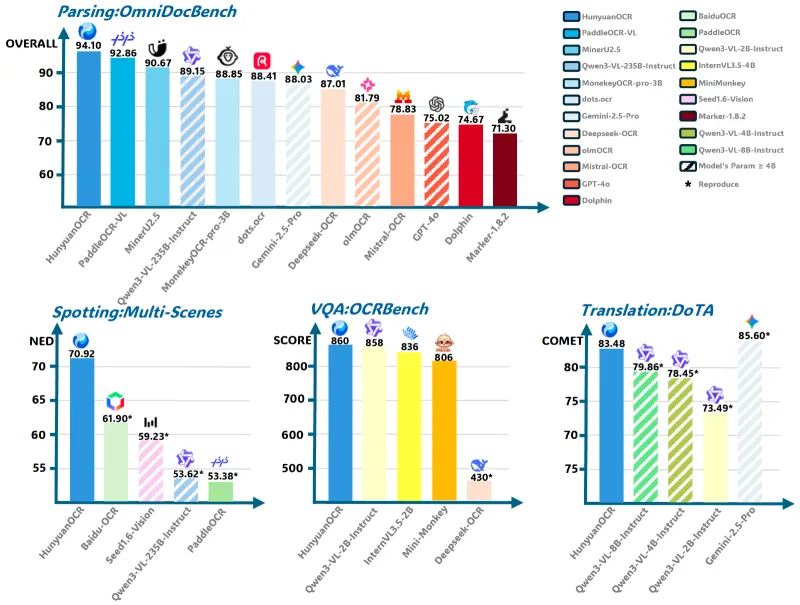
文档解析任务(OmniDocBench基准):综合准确率达94.10%,超过PaddleOCR-VL(92.86%)、Qwen3-VL-235B(89.15%)等模型;
图文翻译任务(DoTA基准):英中翻译准确率83.48%,与235B参数的Qwen3-VL-235B(80.01%)相当;
部署成本优势:仅需80GB显存的NVIDIA GPU即可运行,磁盘空间占用仅6GB,相较于大参数模型(需百GB级显存)大幅降低硬件门槛。
2. 全面OCR能力:单一模型覆盖全场景任务
HunyuanOCR无需额外插件或子模型,单一模型即可支撑8类核心OCR任务,覆盖从基础文字提取到复杂图文解析的全需求:
| 核心任务 | 具体能力描述 |
|---|---|
| 文字检测与识别(Spotting) | 检测图片中所有文字(含文档、艺术字、手写、街景、游戏、视频帧等场景),输出文字内容及坐标信息 |
| 复杂文档解析(Parsing) | 结构化提取文档中的文本、公式(LaTeX格式)、表格(HTML格式)、图表(流程图用Mermaid,其他用Markdown),忽略页眉页脚 |
| 开放字段信息抽取(Information Extraction) | 提取卡证、票据、报告单等中的指定字段(如发票号码、检验日期),支持JSON格式输出;提取视频字幕 |
| 多语种图文翻译(Translation) | 先提取图片文字,再翻译为目标语言(中英互译+14种小语种),保留公式/表格格式 |
| 文档问答(QA) | 基于文档图片内容回答用户问题,无需额外文本转换步骤 |
3. 极致易用性:单一指令+简单部署
端到端推理:无需拆分任务流程,例如“提取文档中的表格并转为HTML”“识别图片文字并翻译为英文”等复杂需求,仅需一条自然语言指令即可完成;
部署便捷:支持vLLM(推荐,推理速度更快)和Transformers两种部署方式,提供现成的安装脚本与推理代码,开发者无需复杂配置;
格式标准化:输出结果自动适配工业级格式(LaTeX/HTML/JSON/Mermaid),可直接用于二次开发或数据存储。
4. 广覆盖语言支持:100+语种识别+14种小语种翻译
识别支持: robust支持超过100种语言,包括中文、英文、日语、韩语、阿拉伯语等,适配单语种、混合语种(如中英文文档)、小众语种场景;
翻译支持:重点覆盖14种高频小语种与中英互译,包括德语、西班牙语、土耳其语、意大利语、俄语、法语、葡萄牙语、阿拉伯语、泰语、越南语、印尼语、马来语、日语、韩语,曾获ICDAR2025文档端到端翻译比赛小模型赛道冠军。
5. 多场景适配:从学术到工业的全场景覆盖
无论是结构化文档(如试卷、发票)、非结构化内容(如手写笔记、街景广告),还是动态场景(如视频帧、游戏画面),HunyuanOCR均能保持高准确率,适配学术研究、办公自动化、智能硬件、内容创作等多领域需求。

三、技术细节
HunyuanOCR的高性能与轻量化优势,源于其底层技术架构与训练策略的优化,核心技术细节如下:
1. 底层架构:混元原生多模态融合
HunyuanOCR基于腾讯混元大模型的原生多模态架构构建,并非“OCR模型+大模型”的拼接,而是从底层实现了“文本-图像”模态的深度融合:
输入层:支持图像(JPG/PNG等格式)与文本指令的联合输入,图像特征提取采用优化后的视觉编码器,适配不同分辨率、复杂背景的图文场景;
融合层:通过跨模态注意力机制,将图像特征与文本指令特征高效融合,实现“指令理解-图像解析-结果生成”的端到端链路;
输出层:针对OCR任务优化的生成器,支持结构化格式(LaTeX/HTML/JSON)的直接输出,避免后续格式转换的误差。
2. 训练策略:多任务联合训练+场景增强
为实现“轻量化+高精度”的平衡,HunyuanOCR采用了多任务联合训练与场景增强策略:
多任务训练:将文字检测、识别、解析、抽取、翻译等任务纳入统一训练框架,让模型共享底层特征,提升参数利用效率;
场景增强:训练数据覆盖文档、艺术字、手写、街景、广告、票据、屏幕截图、游戏、视频帧等9类核心场景,确保模型在复杂场景下的鲁棒性;
语言增强:融入100+语种的文本数据与多语种平行语料,提升跨语言识别与翻译的准确性。
3. 推理优化:框架适配与性能调优
HunyuanOCR针对推理效率进行了专项优化,支持多种部署框架,兼顾速度与精度:
框架支持:官方推荐使用TensorRT框架进行性能测试(评估指标基于该框架),同时兼容vLLM(推理速度更快,适合高并发场景)与Transformers(适配更广泛的开发环境);
显存优化:通过模型量化、批量推理等策略,在80GB显存的GPU上即可稳定运行,支持单张图片或批量图片的高效处理;
结果清洁:内置
clean_repeated_substrings函数,自动清理生成结果中的重复子串,提升输出质量。
4. 性能指标:多基准测试表现优异
HunyuanOCR在多项权威基准测试与自研数据集上表现突出,以下为核心任务的关键性能数据:
(1)文档解析性能(OmniDocBench基准,编辑距离越低越优)
| 模型类型 | 模型名称 | 参数规模 | 综合准确率 | 文本解析 | 公式解析 | 表格解析 |
|---|---|---|---|---|---|---|
| 通用大模型 | Qwen3-VL-235B | 235B | 89.15% | 0.069 | 88.14% | 86.21% |
| 专用OCR模型 | PaddleOCR-VL | 0.9B | 92.86% | 0.035 | 91.22% | 90.89% |
| 专用OCR模型 | HunyuanOCR | 1B | 94.10% | 0.042 | 94.73% | 91.81% |
(2)信息抽取性能(自研数据集,准确率越高越优)
| 模型名称 | 卡片抽取 | 票据抽取 | 视频字幕提取 |
|---|---|---|---|
| DeepSeek-OCR | 10.04% | 40.54% | 5.41% |
| Qwen3-VL-235B | 75.59% | 78.40% | 50.74% |
| Gemini-2.5-Pro | 80.59% | 80.66% | 53.65% |
| HunyuanOCR | 92.29% | 92.53% | 92.87% |
从数据可见,HunyuanOCR在小参数规模下,不仅超越了同量级的专用OCR模型,还在多个任务中优于参数规模远超自身的通用大模型,体现了其高效的参数利用效率与任务适配能力。
四、应用场景
HunyuanOCR的全功能特性与轻量化优势,使其适配从个人开发到企业级应用的多场景需求,核心应用场景如下:
1. 学术与教育场景
试卷/习题解析:自动提取试卷中的题目、公式(LaTeX格式)、图表、解析过程,支持结构化存储与二次编辑,适用于在线教育平台、题库建设;
论文/文献处理:解析多语种学术论文中的文本、公式、表格,自动翻译外文文献(保留公式/表格格式),提升科研效率;
笔记数字化:将手写笔记、打印笔记拍照后,提取文字与公式,转为可编辑文档(如Markdown/Word),适配学生、科研人员的数字化需求。
2. 办公自动化场景
文档数字化:将扫描件、拍照文档转为结构化文本,自动识别表格(HTML格式)、页眉页脚(可忽略),适用于企业档案管理、合同数字化;
票据/卡证处理:提取发票、报销单、身份证、银行卡等中的关键信息(如发票号码、金额、姓名、身份证号),输出JSON格式,适配财务报销自动化、人事档案录入;
会议纪要整理:提取会议白板、手写纪要中的文字与流程图(Mermaid格式),自动转为规范文档,提升办公效率。
3. 内容创作与媒体场景
视频字幕提取:自动提取视频帧中的双语字幕(如影视、教程视频),支持直接导出为字幕文件(SRT/VTT),适配自媒体创作者、视频平台;
图文翻译:将图片中的文字(如海报、宣传图、境外标识)翻译为目标语言,支持14种小语种与中英互译,适用于跨境电商、旅游场景;
广告/海报文字提取:提取海报、户外广告中的文字与艺术字,支持坐标输出,适配广告设计、内容审核场景。
4. 智能硬件与企业应用
智能终端OCR:适配具备GPU算力的智能硬件(如工业平板、智能眼镜),实现现场文字识别(如工业设备标识、物流面单);
医疗报告解析:提取体检报告、检验报告单中的关键指标(如检验日期、结果、正常范围),输出结构化数据,适配医疗信息化系统;
金融票据处理:解析银行汇票、支票等金融票据中的金额、账号、日期等信息,支持合规校验,适配金融机构的自动化审核需求。
5. 个人开发者场景
工具开发:基于HunyuanOCR快速搭建轻量化OCR工具(如截图识字、批量图片文字提取、图文翻译工具);
二次开发:通过API调用或本地部署,将OCR功能集成到个人项目中(如笔记APP、翻译工具、题库工具),降低开发门槛。

五、使用方法
HunyuanOCR提供两种主流部署方式(vLLM推荐、Transformers兼容),以下为详细使用步骤,包含环境准备、安装部署、任务调用等核心流程:
1. 环境准备
(1)系统与软件要求
| 依赖项 | 要求规格 |
|---|---|
| 操作系统 | Linux(仅支持Linux环境) |
| Python | 3.12+(推荐版本,已测试验证) |
| CUDA | 12.8 |
| PyTorch | 2.7.1 |
| GPU | 支持CUDA的NVIDIA GPU(显存≥80GB) |
| 磁盘空间 | ≥6GB(用于存储模型权重与依赖) |
(2)硬件说明
最低配置:单张NVIDIA GPU(80GB显存,如A100 80GB),满足单张图片推理需求;
推荐配置:多张GPU(如2×A100 80GB),支持批量推理与高并发场景;
注意:目前不支持CPU推理,需依赖NVIDIA GPU的CUDA加速。
2. 安装部署
(1)方式一:vLLM部署(推荐,推理速度更快)
步骤1:安装vLLM依赖
pip install vllm --extra-index-url https://wheels.vllm.ai/nightly
步骤2:模型推理代码
from vllm import LLM, SamplingParams
from PIL import Image
from transformers import AutoProcessor
def clean_repeated_substrings(text):
"""清理结果中的重复子串"""
n = len(text)
if n < 8000:
return text
for length in range(2, n // 10 + 1):
candidate = text[-length:]
count = 0
i = n - length
while i >= 0 and text[i:i + length] == candidate:
count += 1
i -= length
if count >= 10:
return text[:n - length * (count - 1)]
return text
# 模型路径(Hugging Face官方仓库)
model_path = "tencent/HunyuanOCR"
# 初始化LLM与处理器
llm = LLM(model=model_path, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_path)
# 采样参数(温度0表示确定性输出,最大 tokens 16384支持长文本)
sampling_params = SamplingParams(temperature=0, max_tokens=16384)
# 输入图片路径与指令
img_path = "/path/to/your/image.jpg" # 替换为你的图片路径
img = Image.open(img_path)
messages = [
{"role": "user", "content": [
{"type": "image", "image": img_path},
{"type": "text", "text": "检测并识别图片中的文字,将文本坐标格式化输出。"} # 替换为你的任务指令
]}
]
# 生成提示词并推理
prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = {"prompt": prompt, "multi_modal_data": {"image": [img]}}
output = llm.generate([inputs], sampling_params)[0]
# 输出结果(清理重复子串)
print(clean_repeated_substrings(output.outputs[0].text))(2)方式二:Transformers部署(兼容更广)
步骤1:安装Transformers依赖
pip install git+https://github.com/huggingface/transformers@82a06db03535c49aa987719ed0746a76093b1ec4
注意:目前该版本为适配HunyuanOCR的专用版本,后续会合并到Transformers主分支。
步骤2:模型推理代码
from transformers import AutoProcessor, HunYuanVLForConditionalGeneration
from PIL import Image
import torch
def main():
# 模型路径
model_name_or_path = "tencent/HunyuanOCR"
# 初始化处理器与模型
processor = AutoProcessor.from_pretrained(model_name_or_path, use_fast=False)
model = HunYuanVLForConditionalGeneration.from_pretrained(
model_name_or_path,
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto" # 自动分配设备(GPU)
)
# 输入图片与指令
img_path = "/path/to/your/image.jpg" # 替换为你的图片路径
image_inputs = Image.open(img_path)
# 任务指令(示例:提取文档正文,忽略页眉页脚,公式LaTeX,表格HTML)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": img_path},
{"type": "text", "text": (
"提取文档图片中正文的所有信息用markdown格式表示,其中页眉、页脚部分忽略,"
"表格用html格式表达,文档中公式用latex格式表示,按照阅读顺序组织进行解析。"
)},
],
}
]
# 生成提示词并编码
texts = [processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True) for msg in messages]
inputs = processor(
text=texts,
images=image_inputs,
padding=True,
return_tensors="pt",
).to(model.device)
# 推理(禁用梯度计算提升速度)
with torch.no_grad():
generated_ids = model.generate(**inputs, max_new_tokens=16384, do_sample=False)
# 解码输出结果
if "input_ids" in inputs:
input_ids = inputs.input_ids
else:
input_ids = inputs.inputs # 兼容 fallback 情况
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(input_ids, generated_ids)]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# 打印结果
print(output_texts[0])
if __name__ == "__main__":
main()(3)快速运行Demo脚本
除上述手动部署外,还可直接运行仓库提供的Demo脚本:
# 进入仓库目录 cd Hunyuan-OCR-master/Hunyuan-OCR-hf # 运行Demo python run_hy_ocr.py
3. 应用导向提示词指南
HunyuanOCR支持通过自然语言指令调用不同任务,以下为常用任务的标准提示词(中英文对照):
| 任务类型 | 英文提示词 | 中文提示词 |
|---|---|---|
| 文字检测识别 | Detect and recognize text in the image, and output the text coordinates in a formatted manner. | 检测并识别图片中的文字,将文本坐标格式化输出。 |
| 公式解析 | Identify the formula in the image and represent it using LaTeX format. | 识别图片中的公式,用LaTeX格式表示。 |
| 表格解析 | Parse the table in the image into HTML. | 把图中的表格解析为HTML。 |
| 图表解析 | Parse the chart in the image; use Mermaid format for flowcharts and Markdown for other charts. | 解析图中的图表,对于流程图使用Mermaid格式表示,其他图表使用Markdown格式表示。 |
| 字段信息抽取 | Extract the content of the fields: ['key1','key2', ...] from the image and return it in JSON format. | 提取图片中的: ['key1','key2', ...] 的字段内容,并按照JSON格式返回。 |
| 视频字幕提取 | Extract the subtitles from the image. | 提取图片中的字幕。 |
| 图文翻译 | First extract the text, then translate the text content into English. If it is a document, ignore the header and footer. Formulas should be represented in LaTeX format, and tables should be represented in HTML format. | 先提取文字,再将文字内容翻译为英文。若是文档,则其中页眉、页脚忽略。公式用latex格式表示,表格用html格式表示。 |
用户可根据实际需求修改提示词,例如将“翻译为英文”改为“翻译为日语”,或调整字段列表(如['发票代码', '发票号码', '金额'])。
六、常见问题解答(FAQ)
1. HunyuanOCR支持哪些操作系统?是否支持CPU推理?
仅支持Linux操作系统,暂不支持Windows、macOS;
不支持CPU推理,需依赖支持CUDA的NVIDIA GPU(显存≥80GB),核心原因是模型的多模态融合与推理过程需要GPU加速,CPU无法满足性能与显存需求。
2. vLLM与Transformers部署方式有何区别?如何选择?
| 部署方式 | 优势 | 适用场景 |
|---|---|---|
| vLLM | 推理速度更快,支持高并发,显存利用率更高 | 企业级应用、高并发场景、批量推理 |
| Transformers | 兼容性更广,适配更多开发环境,集成更灵活 | 个人开发、二次开发、低并发场景 |
推荐优先使用vLLM部署,尤其是需要处理大量图片或高并发请求时;若开发环境限制(如无法安装vLLM),可选择Transformers方式。
3. 为什么我的推理结果与官方测试性能有差异?
官方性能指标基于TensorRT框架测试,而vLLM/Transformers部署方式可能存在轻微差异(误差在1%-3%以内);
图片质量影响:模糊、光照不足、文字扭曲等场景会降低识别准确率,建议输入清晰、正射的图片;
指令规范性:不同指令表述可能影响模型理解,建议使用官方推荐的标准提示词(见“应用导向提示词指南”)。
4. HunyuanOCR支持哪些语言的翻译功能?
翻译方向:支持中文↔英文互译,以及14种小语种与中英互译,具体包括德语、西班牙语、土耳其语、意大利语、俄语、法语、葡萄牙语、阿拉伯语、泰语、越南语、印尼语、马来语、日语、韩语;
识别语言:支持100+语种的文字识别,包括常见语种与部分小众语种,适配混合语种场景(如中英文混合文档)。
5. 如何处理复杂文档中的页眉、页脚?
可通过指令明确要求忽略页眉页脚,例如中文提示词:“提取文档图片中正文的所有信息用markdown格式表示,其中页眉、页脚部分忽略...”;
模型会自动识别文档的页眉页脚区域(基于位置与内容特征),但对于特殊格式文档(如页眉页脚与正文重叠),建议裁剪图片后再进行处理。
6. HunyuanOCR是否可用于商业场景?有何限制?
遵循《Tencent Hunyuan Community License Agreement》,非商业场景可免费使用;
商业场景使用限制:若月活用户(MAU)超过1亿,需向腾讯申请单独的商业许可;
禁止使用场景:危害国家安全、生成虚假信息、歧视性内容、侵犯他人隐私等违反伦理或法律的场景。
7. 显存不足时如何解决?
降低
max_tokens参数:例如将max_tokens=16384改为max_tokens=8192(适用于短文本场景);批量推理时减小批次大小(batch size):例如从
batch_size=8改为batch_size=4;使用模型量化版本:后续官方可能推出量化模型(如INT8),进一步降低显存占用,可关注仓库更新。
七、相关链接
Hugging Face模型页:https://huggingface.co/tencent/HunyuanOCR
Hugging Face Space Demo:https://huggingface.co/spaces/tencent/HunyuanOCR
八、总结
HunyuanOCR是腾讯混元团队开源的一款轻量化、全功能端到端OCR专家模型,以1B参数实现了业界领先的性能表现,覆盖文字检测识别、复杂文档解析、信息抽取、多语种翻译、视频字幕提取等全场景OCR任务,支持100+语种识别与14种小语种互译,具备部署便捷、易用性高、适配性广的核心优势。其底层基于混元原生多模态架构,通过多任务联合训练与推理优化,在保证高精度的同时降低了硬件门槛,仅需80GB显存的NVIDIA GPU即可部署,适用于学术教育、办公自动化、内容创作、企业级应用等多种场景。作为开源项目,HunyuanOCR提供了完整的推理代码、模型权重与详细文档,支持vLLM与Transformers两种部署方式,无论是个人开发者快速搭建工具,还是企业级应用集成OCR能力,都能提供高效、低成本的解决方案,为图文智能解析领域注入了轻量化、全功能的开源力量。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/hunyuanocr.html





