Local-NotebookLM:开源本地部署的PDF转音频工具,支持多 LLM 与 TTS 模型集成
一、Local-NotebookLM是什么?
Local-NotebookLM是一款基于本地人工智能技术的开源工具,其核心定位是“PDF文档的音频化转换器”——通过整合本地大语言模型(LLM)与文本转语音(TTS)模型,将传统静态的PDF文件(如科研论文、课件、报告、手册等)转化为动态的音频内容,例如播客、访谈、讲座、摘要等。
与传统云端PDF转音频工具相比,Local-NotebookLM的核心优势在于“本地化部署”:无需将PDF数据上传至第三方服务器,可在本地设备(如个人电脑、服务器)完成文本提取、脚本生成、音频合成全流程,既保护数据隐私,又避免云端API调用的流量费用与网络依赖。
从本质上看,Local-NotebookLM并非单一工具,而是一套“PDF音频化处理 pipeline”:它先通过文本提取模块清洗PDF内容,再通过LLM生成符合目标风格的音频脚本,最后通过TTS模型将脚本转化为多 speaker(单主播/双嘉宾/多嘉宾)的音频文件,整个流程可通过配置文件灵活调整,适配不同场景的需求。

二、Local-NotebookLM的功能特色
Local-NotebookLM的功能设计围绕“灵活性、本地化、易用性”三大核心,覆盖从PDF处理到音频输出的全链路,具体特色可分为以下8类:
1. 全流程PDF处理:从提取到清洗,适配复杂文档
工具对PDF的处理并非简单“文本复制”,而是包含多步优化:
文本提取:支持提取PDF中的文字内容,同时兼容包含LaTeX数学公式、特殊符号(如公式、图表标注)的文档,避免因格式问题导致的内容丢失;
内容清洗:自动去除PDF中的无关元素,如页码、页眉页脚、重复水印等,确保后续脚本生成的准确性;
分块处理:将长PDF按“1000字符/块”(可配置)拆分为 manageable 片段,避免因文档过长导致LLM处理超时或内存不足,同时支持“重叠分块”(如10%-20%重叠率),防止内容断裂。
2. 高度定制化的音频生成:风格、长度、格式全可控
工具支持14种音频输出格式,且每种格式可搭配不同风格与长度,满足多样化需求。为清晰展示格式分类,下表整理了支持的输出格式及适用场景:
| 格式类型 | 支持speaker数量 | 核心用途 | 典型场景 |
|---|---|---|---|
| 摘要(summary) | 1 | 快速获取PDF核心内容 | 阅读报告后生成要点音频 |
| 播客(podcast) | 2 | 模拟嘉宾对话,生动解读PDF内容 | 科研论文转科普播客 |
| 访谈(interview) | 2 | 以“提问-回答”形式拆解PDF重点 | 教材章节转师生访谈音频 |
| 讲座(lecture) | 1 | 模拟教师授课,系统讲解PDF知识 | 课件转复习音频 |
| 小组讨论(panel-discussion) | 3-5 | 多角色对话,从不同角度分析PDF内容 | 行业报告转专家研讨音频 |
| 辩论(debate) | 3-5 | 模拟正反方辩论,呈现PDF中的争议点 | 政策文件转立场辩论音频 |
| 教程(tutorial) | 1 | 分步讲解PDF中的操作指南或流程 | 软件手册转操作教学音频 |
除格式外,用户还可通过参数自定义:
长度:支持“短(约5分钟)、中(约15分钟)、长(约30分钟)、极长(约60分钟)”四档,工具会根据长度自动调整内容详略;
风格:提供“正常、casual(口语化)、正式、技术、学术、友好、Gen-Z(年轻化)、幽默”8种风格,例如“学术风格”会保留专业术语,“Gen-Z风格”会使用网络流行语;
内容焦点:通过
--preference参数指定重点,例如“聚焦实验数据”“忽略理论部分”“强调 practical 应用”,LLM会根据偏好调整脚本权重。
3. 多模型兼容:本地与云端LLM/TTS自由选
工具不绑定单一模型提供商,支持“本地模型+云端模型”混合使用,用户可根据设备性能与需求灵活选择:
LLM支持:覆盖7类主流提供商,包括本地部署的Ollama、LMStudio,以及云端的OpenAI、Groq、Azure、Google Generative AI、Anthropic;例如设备性能足够时,可使用本地Ollama运行Llama 3模型;追求速度时,可选用Groq的API(文档提到其推理速度较快);
TTS支持:支持ElevenLabs、Azure TTS、本地Kokoro-FastAPI等,用户可选择不同语音(如“afalloy”“afbella”等)分配给主持人与嘉宾,甚至自定义TTS服务器端点(通过“custom”提供商配置);
模型分工:工具将LLM分为“Small Text Model”与“Big Text Model”,前者用于PDF文本分块处理(轻量任务),后者用于脚本生成(复杂任务),可分别配置不同模型,平衡性能与效率。
4. 多端访问方式:满足不同用户群体需求
无论用户是技术开发者还是非技术人员,都能找到适合的使用方式:
Gradio Web UI:可视化界面,支持拖拽上传PDF、选择格式/风格/语言,无需输入命令,适合非技术用户;默认运行在
http://localhost:7860,可通过--share参数生成网络链接,供团队共享使用;CLI命令行:通过
python -m local_notebooklm.start命令启动,支持批量处理PDF,适合熟悉命令行的用户或自动化脚本集成;FastAPI服务器:启动后提供RESTful API,支持通过HTTP请求调用功能(如
/generate-audio接口),可集成到Web应用、小程序等项目中;API文档默认在http://localhost:8000/docs,支持在线调试;编程API:提供
podcast_processor()函数,可直接在Python代码中调用,例如在数据处理 pipeline 中嵌入PDF转音频功能。
5. 多语言支持:突破英文限制
工具默认支持英文音频生成,同时允许用户指定其他语言(如德语、中文等),但需注意:非英文语言需满足两个前提——所选LLM支持该语言的文本生成(如ChatGLM支持中文)、所选TTS支持该语言的语音合成(如Azure TTS支持中文);文档特别提示,建议先验证模型的语言能力,再进行非英文处理,避免出现语法错误或发音问题。
6. 完整的输出文件管理:过程与结果可追溯
工具在处理过程中会生成多类文件,既方便用户查看中间结果,也便于问题排查,典型输出文件如下:
step1/extracted_text.txt:从PDF提取的原始文本;step1/clean_extracted_text.txt:清洗后的文本(去除无关元素);step2/data.pkl:LLM生成的初始脚本数据(二进制格式,可用于后续重新处理);step3/podcast_ready_data.pkl:TTS优化后的脚本数据(包含speaker分配、语音标记);step4/segments/podcast_segment_*.wav:单个speaker的音频片段(如“主持人片段1.wav”“嘉宾1片段1.wav”);step4/podcast.wav:最终拼接的完整音频文件(可直接播放或分享)。
7. 容器化部署:简化环境配置
针对“环境依赖复杂”的痛点,工具提供Docker Compose部署方案,用户无需手动安装Python库、配置模型服务器,只需通过2条命令即可启动Web UI与FastAPI服务:
构建容器:
docker-compose up --build;停止服务:
docker-compose down; 容器启动后,自动映射端口(Web UI 7860、API 8000),用户直接通过浏览器访问即可,适合团队快速部署或跨平台使用(Windows、Linux、macOS均支持)。
8. 示例资源丰富:降低使用门槛
仓库包含多个示例资源,帮助用户快速理解工具功能:
示例音频:
examples/podcast.wav,基于gpt4o与Azure TTS生成,展示播客风格的输出效果;示例配置:
example_config.json,包含完整的配置模板,用户可直接修改API密钥、语音选择等参数;架构图:提供 pipeline 流程图,清晰展示“PDF处理→脚本生成→TTS优化→音频合成”四步逻辑,便于开发者二次开发。
三、Local-NotebookLM的技术细节
要理解工具的工作原理,需从“核心 pipeline 架构”“模型交互逻辑”“技术依赖”三方面展开,这部分内容虽涉及技术术语,但文档已通过流程图与配置示例简化,以下为通俗解读:
1. 核心pipeline架构:四步完成PDF转音频
Local-NotebookLM的核心逻辑是“分步骤处理,每步专注单一任务”,整个pipeline由4个步骤组成,各步骤间通过文件传递数据,流程如下图所示(基于文档流程图简化):
PDF文件 → Step1(PDF处理)→ Step2(脚本生成)→ Step3(TTS优化)→ Step4(音频合成)→ 最终音频(wav)
(1)Step1:PDF处理——从“文档”到“干净文本”
这一步的目标是将PDF转化为LLM可处理的文本,包含4个细分操作:
验证PDF:检查PDF是否损坏、是否加密(加密PDF无法提取文本,工具会报错);
提取文本:使用PyPDF2库(文档
requirements.txt中包含)提取PDF中的文字,支持多页PDF自动合并;分块处理:调用
create_word_bounded_chunks()函数,将文本按“1000字符/块”(可通过配置chunk_size修改)拆分,同时确保分块不切断完整单词(避免“hel-lo”这类断裂);轻量处理:调用“Small Text Model”对每个分块进行初步清洗,例如去除冗余空格、统一格式,最终生成
clean_extracted_text.txt。
(2)Step2:脚本生成——从“文本”到“音频脚本”
这一步是核心,由“Big Text Model”负责将干净文本转化为符合目标格式的脚本,包含3个操作:
读取文本:加载Step1生成的
clean_extracted_text.txt;生成脚本:根据用户指定的“格式(如podcast)、风格(如casual)、长度(如medium)”,LLM生成脚本;例如“podcast格式”会生成“主持人:今天我们来聊一篇关于AI的论文… 嘉宾:我觉得这篇论文的实验设计很有意思…”这类对话式内容;
重叠分块:若文本过长,会按“2000 token/块”(可通过
chunk_token_limit修改)再次分块,且块与块之间保留10%重叠(避免内容断裂),最终生成data.pkl(二进制脚本数据)。
(3)Step3:TTS优化——从“脚本”到“适合语音的脚本”
LLM生成的脚本可能包含“长句、复杂术语”,直接用于TTS会导致发音生硬,因此这一步需优化脚本的“口语化程度”,包含4个操作:
读取脚本:加载Step2生成的
data.pkl;重写脚本:调用“Big Text Model”将脚本改写为“短句、口语化表达”,例如将“该模型在CIFAR-10数据集上的准确率达到95%”改为“咱们来说说这个模型的性能——在CIFAR-10数据集上,它的准确率能到95%,这个成绩还是很亮眼的”;
添加语音标记:为不同speaker分配语音标签(如“[主持人]”“[嘉宾1]”),TTS后续会根据标签调用对应语音;
格式验证:检查脚本是否符合“speaker-文本”格式(避免无speaker标签的内容),最终生成
podcast_ready_data.pkl。
(4)Step4:音频合成——从“脚本”到“音频文件”
这一步是最后环节,由TTS模型将优化后的脚本转化为音频,包含4个操作:
加载脚本:加载Step3生成的
podcast_ready_data.pkl,解析出每个speaker的文本片段;生成片段音频:调用TTS模型(如Kokoro-FastAPI、ElevenLabs),为每个片段生成对应语音的音频(如“主持人片段1.wav”),保存到
step4/segments/目录;拼接音频:按脚本顺序将片段音频拼接,确保过渡自然(无静音或杂音);
输出最终文件:生成
podcast.wav,支持16kHz采样率(默认),确保音频质量清晰。
2. 模型交互逻辑:Small/Big TTS模型如何协作?
工具中涉及三类模型(Small Text Model、Big Text Model、TTS Model),它们的分工与交互逻辑如下:
Small Text Model:仅用于Step1的“分块轻量处理”,任务简单(如文本清洗),因此可选用轻量模型(如Llama 3.2-8B),甚至本地部署的模型,降低资源占用;
Big Text Model:用于Step2的“脚本生成”与Step3的“脚本重写”,任务复杂(需理解PDF内容、生成对话),因此建议选用能力较强的模型(如Llama 3.2-90B、gpt4o),可根据需求选择本地或云端模型;
TTS Model:仅用于Step4的“音频生成”,用户可选择“云端TTS(如ElevenLabs)”或“本地TTS(如Kokoro-FastAPI)”,本地TTS需提前部署服务器(文档提供Kokoro-FastAPI的部署链接)。
三类模型的交互均通过“客户端”实现:工具在local_notebooklm/目录下封装了对应模型的客户端(如llm_client.py、tts_client.py),用户只需在配置文件中指定“提供商、API密钥、端点”,客户端会自动处理请求与响应,无需手动编写API调用代码。
3. 技术依赖:工具运行需要哪些基础?
Local-NotebookLM的技术依赖可分为“软件依赖”与“硬件依赖”,文档已明确列出,以下为整理:
(1)软件依赖
Python版本:必须为3.12及以上(低于该版本可能导致库兼容性问题);
核心Python库:
PDF处理:PyPDF2(提取文本)、pdfplumber(可选,增强复杂PDF处理);
LLM交互:openai(OpenAI API)、groq(Groq API)、ollama(Ollama客户端);
TTS交互:requests(调用TTS API)、soundfile(处理音频文件);
界面与服务:gradio(Web UI)、fastapi(API服务)、uvicorn(ASGI服务器);
其他:tqdm(显示处理进度)、numpy(数据处理)、pathlib(文件路径管理); 所有依赖可通过
requirements.txt一键安装,或通过Docker自动配置。
(2)硬件依赖
内存:最低8GB(仅能运行轻量本地模型,如Llama 3.2-8B);推荐16GB+(可运行Llama 3.2-70B等较大模型,避免内存溢出);
磁盘空间:最低10GB(用于存储Python库、模型文件、输出音频);若部署本地模型,需额外预留模型空间(如Llama 3.2-70B约需20GB磁盘);
CPU/GPU:本地模型运行依赖CPU或GPU,GPU(如NVIDIA RTX 3090/4090)可大幅提升LLM推理速度;若仅使用云端模型,CPU性能无特殊要求。
四、Local-NotebookLM的应用场景
工具的应用场景围绕“PDF音频化”展开,覆盖个人、教育、科研、企业、开发五大领域,以下为具体场景与使用示例:
1. 科研人员:论文转播客,简化学术分享
科研人员常需阅读大量论文,且需向团队或同行分享内容。使用Local-NotebookLM可:
将论文PDF转为“播客格式”,模拟“研究者对话”,例如“主持人(自己):这篇论文的创新点是什么?嘉宾1(模型):它提出了一种新的注意力机制,解决了长文本处理的效率问题…”;
通过
--preference "聚焦实验结果与结论",让脚本重点讲解数据与发现,忽略无关的背景介绍;生成音频后,可在团队会议前分享,节省“逐页读论文”的时间;若需英文分享,可指定
--language english,搭配Azure TTS的英文语音,确保发音准确。
2. 学生群体:课件转教程,提升复习效率
学生面对厚重的课件PDF(如数学公式、编程手册),单纯阅读易疲劳。使用工具可:
将课件转为“教程格式”或“讲座格式”,例如将《机器学习》课件转为“老师讲解音频”,脚本包含“这节课我们讲线性回归——首先,线性回归的基本公式是… 然后,我们通过一个例子来理解…”;
选择“casual风格”与“短长度”,将每章课件拆分为5分钟的音频片段,适合通勤、散步时碎片化复习;
若课件包含中文内容,可部署本地ChatGLM作为LLM,搭配中文TTS(如阿里云TTS),生成中文复习音频。
3. 企业员工:报告转培训音频,优化内部沟通
企业中常有“年度报告、产品手册、政策文件”等PDF,需向员工传达关键信息。使用工具可:
将报告转为“新闻报道格式”或“ executive brief 格式”,例如将《2024年度销售报告》转为“主播:各位同事,2024年我们的销售额达到了1亿元,同比增长20%… 重点市场分布在华东地区…”;
选择“正式风格”,确保内容严谨;通过
--output-dir ./training-audio将音频保存到共享目录,员工可随时收听;若需多部门讨论,可转为“小组讨论格式”,分配“销售部代表、市场部代表、研发部代表”三种speaker,从不同角度解读报告,促进跨部门理解。
4. 内容创作者:PDF素材转播客脚本,降低创作成本
播客创作者常需从PDF素材(如行业报告、历史文献)中获取内容,手动写脚本耗时。使用工具可:
将素材PDF转为“播客格式”脚本,例如从《2025 AI行业报告》中提取内容,生成“主持人:今天我们聊聊AI行业的新趋势… 嘉宾:根据报告,生成式AI的市场规模将突破1000亿美元…”;
选择“幽默风格”或“Gen-Z风格”,让脚本更贴近目标听众;若需多嘉宾互动,可转为“辩论格式”,设置“支持AI发展”“警惕AI风险”两方,增加播客趣味性;
生成脚本后,可直接使用工具的TTS功能生成音频初稿,再手动修改细节,节省“写脚本+找配音”的时间。
5. 开发者:集成API到项目,扩展功能边界
开发者可将Local-NotebookLM的功能集成到自己的项目中,例如:
在“在线文档平台”中添加“PDF转音频”功能:通过FastAPI调用工具,用户上传PDF后,平台自动生成音频并提供下载;
在“教育APP”中嵌入“课件音频生成”模块:调用编程API(
podcast_processor()),根据用户选择的课件章节,实时生成复习音频;二次开发:修改工具的pipeline逻辑,例如添加“PDF图片识别”模块(支持图片型PDF),或集成新的TTS模型(如字节跳动TTS),扩展工具能力。
五、Local-NotebookLM的使用方法
工具的使用流程可分为“环境准备→安装→配置→启动”四步,以下分不同安装方式详细说明,确保用户可按步骤操作:
1. 环境准备:提前安装必要软件
无论选择哪种安装方式,需先准备以下环境:
Python 3.12+:从Python官网(https://www.python.org/)下载,安装时勾选“Add Python to PATH”;
可选:本地模型服务器:若使用本地LLM(如Ollama),需提前安装对应服务器:
Ollama:下载地址https://www.aipuzi.cn/ai-softs/ollama.html,安装后通过
ollama pull llama3:8b下载模型;LMStudio:下载地址https://www.aipuzi.cn/ai-softs/lmstudio.html,在软件中选择模型并启动服务器;
可选:本地TTS服务器:若使用本地TTS,需部署Kokoro-FastAPI(文档推荐),步骤参考:https://github.com/remsky/Kokoro-FastAPI;
Docker(可选):若使用Docker部署,需安装Docker Desktop(Windows/macOS)或Docker Engine(Linux),下载地址https://www.docker.com/。
2. 安装方式:三种方式任选
(1)方式1:通过PyPI安装(最简单,适合非开发者)
PyPI是Python的官方包仓库,安装命令仅需1行:
pip install local-notebooklm
安装完成后,可直接通过命令行或Python代码调用工具,无需下载源码。
(2)方式2:从源码安装(适合需修改代码的开发者)
需先下载源码,再安装依赖:
克隆GitHub仓库:
git clone https://github.com/Goekdeniz-Guelmez/Local-NotebookLM.git cd Local-NotebookLM
创建并激活虚拟环境(避免依赖冲突):
# Windows系统 python -m venv venv venv\Scripts\activate # macOS/Linux系统 python -m venv venv source venv/bin/activate
安装依赖:
pip install -r requirements.txt
若安装过程中出现“PyPDF2安装失败”,可尝试升级pip:pip install --upgrade pip。
(3)方式3:Docker Compose安装(适合团队部署)
无需安装Python,直接通过容器启动:
克隆仓库(同方式2步骤1);
进入docker目录:
cd Local-NotebookLM/docker
构建并启动容器:
docker-compose up --build
首次启动会下载镜像,耗时较长(取决于网络速度);启动成功后,会提示“Gradio UI running on http://localhost:7860”“FastAPI running on http://localhost:8000”。
3. 配置:自定义模型与参数
工具支持“默认配置”与“自定义配置”,若使用云端模型(如OpenAI、Groq),需配置API密钥:
(1)默认配置
无需手动修改,工具会使用base_config(内置的默认配置),但需注意:
默认LLM提供商为Groq,需在环境变量中设置API密钥(以Windows为例):
set GROQ_API_KEY=your-groq-key # 替换为你的Groq密钥
若使用其他提供商,需修改环境变量(如
OPENAI_API_KEY、AZURE_OPENAI_KEY)。
(2)自定义配置
通过example_config.json修改参数,步骤如下:
复制仓库中的
example_config.json,重命名为custom_config.json;编辑
custom_config.json,关键字段解释:
语音设置:修改
Co-Host-Speaker-1-Voice等字段,选择支持的语音(如“afecho”“afnova”);LLM设置:在
Small-Text-Model/Big-Text-Model中修改provider,例如使用Ollama:json "Small-Text-Model": { "provider": { "name": "ollama", "endpoint": "http://localhost:11434", "key": "not-needed" # Ollama无需密钥 }, "model": "llama3:8b" }TTS设置:在
Text-To-Speech-Model中修改provider,例如使用Kokoro-FastAPI:json "Text-To-Speech-Model": { "provider": { "name": "custom", "endpoint": "http://localhost:8880/v1", "key": "not-needed" }, "model": "kokoro", "audio_format": "wav" }
使用时通过
--config参数指定自定义配置文件。
4. 启动与使用:四种方式详解
(1)方式1:Gradio Web UI(推荐非技术用户)
启动命令:
# 从PyPI安装的用户 python -m local_notebooklm.web_ui # 从源码安装的用户(需激活虚拟环境) python -m local_notebooklm.web_ui # Docker用户无需额外启动,容器已包含Web UI
访问界面:打开浏览器,输入
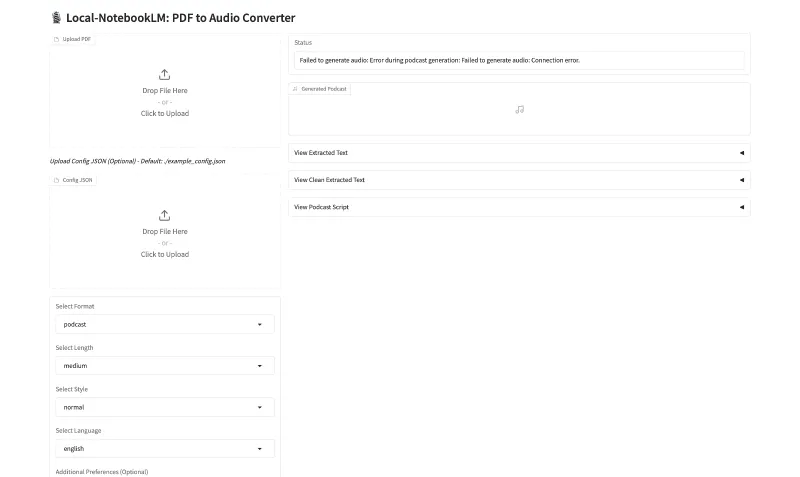
http://localhost:7860,界面包含以下核心功能:
上传PDF:拖拽文件或点击“Click to Upload”;
选择参数:格式(如podcast)、长度(如medium)、风格(如casual)、语言(如english);
上传配置:可选上传
custom_config.json;生成音频:点击“Generate Audio”,等待处理完成后,可播放或下载
podcast.wav。
(2)方式2:CLI命令行(适合批量处理)
基本命令格式:
python -m local_notebooklm.start --pdf 你的PDF路径 [其他参数]
常见示例:
基础使用(默认生成播客,中等长度,正常风格):
python -m local_notebooklm.start --pdf ./documents/research_paper.pdf
自定义风格与长度:
python -m local_notebooklm.start --pdf ./课件.pdf --format tutorial --length short --style casual
指定自定义配置与输出目录:
python -m local_notebooklm.start --pdf ./报告.pdf --config ./custom_config.json --output-dir ./my-audio --language chinese
聚焦特定内容:
python -m local_notebooklm.start --pdf ./AI论文.pdf --preference "重点讲解模型架构与实验数据,忽略相关工作部分"
(3)方式3:FastAPI服务器(适合集成到项目)
启动服务器:
python -m local_notebooklm.server
访问API文档:打开
http://localhost:8000/docs,可看到所有API接口,例如:
/generate-audio:POST请求,上传PDF与参数,生成音频;/get-output-files:GET请求,获取输出文件列表;
调试API:在文档页面点击接口,输入参数(如PDF文件路径、格式),点击“Try it out”即可测试。
(4)方式4:编程API(适合Python开发者)
在Python代码中直接调用podcast_processor()函数,示例:
from local_notebooklm.processor import podcast_processor
# 调用函数生成音频
success, result = podcast_processor(
pdf_path="./documents/机器学习课件.pdf", # PDF路径
config_path="./custom_config.json", # 自定义配置路径
format_type="lecture", # 格式:讲座
length="medium", # 长度:中等
style="academic", # 风格:学术
preference="聚焦算法原理,添加例题讲解", # 内容焦点
output_dir="./lecture-audio", # 输出目录
language="chinese" # 语言:中文
)
# 处理结果
if success:
print(f"音频生成成功,路径:{result}")
else:
print(f"生成失败,原因:{result}")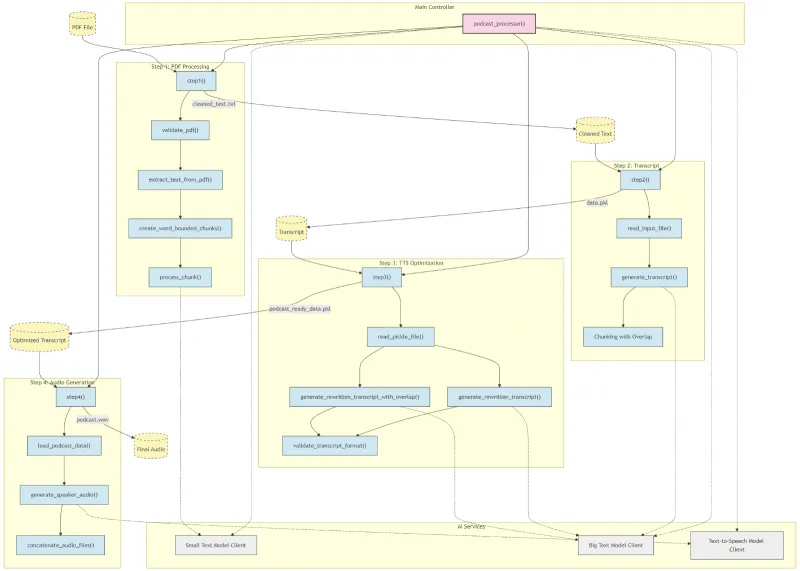
六、常见问题解答(FAQ)
1. 问题1:PDF上传后提示“提取失败”,怎么办?
可能原因:
PDF是加密文件(需密码才能打开);
PDF是图片型(无文本,仅包含扫描图片);
PDF文件损坏或路径错误。
解决方案:
检查PDF是否加密:用Adobe Reader打开,若提示输入密码,需先解密(可使用在线PDF解密工具,如ilovepdf.com/decrypt-pdf);
图片型PDF:工具暂不支持,需先通过OCR工具(如Adobe Acrobat、天若OCR)将图片转为文本,再生成PDF;
路径错误:确保
--pdf参数后的路径正确,例如Windows路径需用\(如C:\documents\paper.pdf),或用/(如C:/documents/paper.pdf)。
2. 问题2:启动后提示“API连接错误”,如何解决?
可能原因:
API密钥错误或过期(如OpenAI、Groq密钥);
网络问题(无法访问云端API);
本地模型服务器未启动(如Ollama、Kokoro-FastAPI)。
解决方案:
验证API密钥:登录对应平台(如Groq官网https://console.groq.com/),检查密钥是否正确,若过期需重新生成;
网络问题:若使用云端模型,确保网络可访问外网(必要时配置代理);若使用本地模型,无需外网;
本地服务器:检查Ollama是否启动(命令行输入
ollama list,若显示模型则正常);检查Kokoro-FastAPI是否运行(浏览器访问http://localhost:8880/v1,提示“Not Found”则正常)。
3. 问题3:运行时提示“内存不足”(Out of Memory),怎么处理?
可能原因:
内存低于8GB,或同时运行其他内存密集型程序(如浏览器、视频软件);
本地模型过大(如Llama 3.2-70B),超出设备内存;
分块大小设置过大(Step1的
chunk_size或Step2的chunk_token_limit)。
解决方案:
关闭其他程序:打开任务管理器(Windows)或活动监视器(macOS),关闭占用内存高的程序;
更换小模型:将本地模型换成轻量版,如将Llama 3.2-70B换成Llama 3.2-8B;
减小分块大小:在自定义配置文件中修改
Step1的chunk_size(如从1000改为500),或Step2的chunk_token_limit(如从2000改为1000)。
4. 问题4:生成的音频质量差(发音生硬、有杂音),如何优化?
可能原因:
TTS模型选择不当(如轻量模型音质较差);
脚本包含长句或复杂术语,TTS无法自然处理;
TTS服务器未正常运行(如Kokoro-FastAPI卡顿)。
解决方案:
更换TTS模型:使用云端TTS(如ElevenLabs、Azure TTS),这些模型音质通常优于本地轻量模型;
优化脚本:在
--preference中添加“使用短句,避免复杂术语”,让LLM生成更适合TTS的脚本;重启TTS服务器:若使用本地TTS,关闭并重新启动Kokoro-FastAPI,确保无卡顿。
5. 问题5:Docker启动后,无法访问Web UI(http://localhost:7860),怎么办?
可能原因:
端口被占用(7860或8000端口已被其他程序使用);
Docker容器未正常启动(日志显示错误);
防火墙阻止了容器端口。
解决方案:
检查端口占用:Windows用
netstat -ano | findstr 7860,macOS/Linux用lsof -i :7860,找到占用程序并关闭;查看容器日志:在docker目录下执行
docker-compose logs,查找“Error”信息,例如“API密钥错误”需在配置文件中修改;关闭防火墙:临时关闭Windows Defender或第三方防火墙,测试是否能访问;若能访问,需添加端口例外(允许7860、8000端口)。
6. 问题6:生成非英文音频时,出现语法错误或发音错误,怎么解决?
可能原因:
LLM不支持目标语言(如用仅支持英文的模型生成中文脚本);
TTS不支持目标语言(如用英文TTS生成中文语音,会出现“拼音发音”);
语言参数设置错误(如
--language chinese拼错为chinese1)。
解决方案:
验证模型语言支持:选择支持目标语言的LLM(如中文用ChatGLM、Qwen),TTS(如中文用阿里云TTS、百度TTS);
检查语言参数:确保
--language参数正确,工具支持的语言需与模型一致(如“german”对应德语模型);测试小样本:先使用短PDF(如1页中文文档)生成音频,验证语法与发音是否正常,再处理长文档。
七、相关链接
八、总结
Local-NotebookLM是一款聚焦“PDF音频化”的开源本地AI工具,通过“PDF处理→脚本生成→TTS优化→音频合成”四步pipeline,实现从静态文档到动态音频的转化。它的核心优势在于“本地化部署”保护数据隐私、“多模型兼容”适配不同设备性能、“多端访问”满足不同用户需求,同时支持高度定制化的音频风格与内容焦点,覆盖科研、教育、企业、内容创作等多场景。工具提供PyPI、源码、Docker三种安装方式,搭配Gradio Web UI与详细示例,降低非技术用户的使用门槛;同时通过开放API与灵活配置,支持开发者二次开发与项目集成。尽管使用过程中可能遇到PDF提取失败、模型连接错误等问题,但文档提供了清晰的 troubleshooting 方案,帮助用户快速解决。作为一款2025年发布的开源工具,Local-NotebookLM填补了“本地PDF转音频”的需求空白,为重视隐私与个性化的用户提供了高效、灵活的解决方案。
相关软件下载

Ollama

LM Studio
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/local-notebooklm.html