Qwen3-VL:Qwen 系列推出的强大多模态 AI 模型,打通视觉与语言的智能融合
一、Qwen3-VL是什么?
Qwen3-VL是Qwen系列开源的强大多模态视觉-语言模型(Vision-Language Model,VLM),支持图像/视频理解、文本交互、视觉代理等全场景任务,具备长上下文处理、空间感知、跨语言OCR等核心能力,提供从部署到微调的完整工具链,适用于智能办公、教育、内容创作等多领域。
作为开源项目,Qwen3-VL的仓库提供了完整的代码、模型权重、使用文档、微调工具及示例,支持开发者直接部署、二次开发或集成到实际应用中。无论是处理单张图片、长视频,还是结合文本进行复杂推理,Qwen3-VL都能以统一的接口实现高效响应,其设计目标是成为“通用多模态智能的基础设施”。
二、功能特色
Qwen3-VL在视觉-语言融合能力上实现了全面升级,核心特色可概括为“全场景覆盖、高精度理解、强交互能力”,具体如下:
1. 视觉代理:像人一样“操作”设备界面
Qwen3-VL具备强大的视觉代理能力,可模拟人类对电脑、手机等设备的GUI(图形用户界面)操作。例如:
识别界面中的按钮、输入框、菜单等元素,理解其功能(如“确认按钮用于提交表单”);
根据自然语言指令完成连贯操作(如“打开浏览器,搜索‘Qwen3-VL’,并下载第一页的PDF文档”);
处理界面异常(如弹窗提示、加载失败),并自主调整操作逻辑。
2. 视觉编码:从图像/视频到代码的直接转换
传统模型仅能对图像进行描述,而Qwen3-VL可将视觉内容直接转换为结构化代码,支持:
从流程图图片生成Draw.io代码,直接复用为可编辑图表;
从网页截图生成HTML/CSS/JS代码,还原页面布局与交互逻辑;
从UI设计图生成前端框架代码(如Vue、React组件),加速开发流程。
3. 空间感知:理解物体的“位置与关系”
Qwen3-VL突破了平面视觉的局限,具备高级空间推理能力:
精准判断物体位置(如“桌子上的杯子在笔记本电脑左侧30厘米处”);
解析视角与遮挡关系(如“从斜上方拍摄,书本遮挡了钢笔的下半部分”);
支持2D/3D目标定位,可输出物体在图像中的坐标框或3D空间中的大致尺寸,为机器人导航、AR/VR场景提供基础。
4. 长上下文与视频理解:处理“超长内容”无压力
针对长文档、长视频等复杂输入,Qwen3-VL具备原生支持256K上下文的能力(可扩展至100万token),实现:
长文档解析:一次性处理数百页PDF/Word,提取关键信息并生成摘要;
长视频理解:分析数小时视频(如会议录像、监控画面),定位关键事件(如“1小时23分时有人进入房间”),并生成时序摘要;
秒级索引与完整召回:无需分段处理,可直接关联视频帧与文本描述(如“视频中第30分钟提到的‘项目进度’对应PPT第5页内容”)。
5. 强化多模态推理:从“看到”到“想明白”
Qwen3-VL不仅能“看懂”内容,还能进行深度逻辑推理,尤其在STEM(科学、技术、工程、数学)领域表现突出:
数学题求解:结合图像中的公式、图表,推导物理公式(如“根据斜面受力图计算摩擦力”)或几何证明;
因果分析:从视频中推断事件因果(如“因为管道漏水,导致地面出现积水”);
证据式回答:基于图像/视频中的细节提供可验证的结论(如“判定这辆车超速,因为视频显示其10秒内通过了200米路段”)。
6. 升级的视觉识别:“见多识广”的识别能力
通过大规模预训练,Qwen3-VL可识别更广泛的对象类型:
人物:涵盖名人、动漫角色、历史人物(如“图中是爱因斯坦,他手中拿着的是相对论手稿”);
物体:包括产品型号(如“这是iPhone 15 Pro,颜色为自然钛金属”)、动植物(如“这是红隼,属于隼科猛禽”)、地标(如“这是迪拜哈利法塔,高828米”);
场景:区分复杂场景(如“这是手术室,医生正在进行腹腔镜手术”)。
7. 扩展的OCR能力:多语言、强鲁棒性的文字识别
OCR(光学字符识别)是Qwen3-VL的核心功能之一,相比前代实现了显著升级:
语言覆盖:支持32种语言(从10种扩展),包括中文(含繁体、古文字)、英文、日文、阿拉伯文等;
场景适应:在低光、模糊、倾斜、扭曲(如曲面瓶身文字)场景下仍保持高准确率;
专业领域:精准识别生僻字、化学公式、乐谱符号、工程图纸标注等专业内容;
结构解析:可提取长文档的排版结构(如标题、段落、表格、图片位置),生成可编辑的Markdown或Word格式。
8. 文本-视觉无缝融合:统一的理解能力
Qwen3-VL的文本理解能力与纯语言大模型(如Qwen3)相当,可实现“文本指令-视觉内容-输出结果”的无缝衔接:
例如,用户输入“根据这张财报图,用中文总结营收增长最快的三个季度,并分析原因”,模型会先识别图表中的数据,再结合文本逻辑生成结构化分析。

三、技术细节
Qwen3-VL的强大功能源于其创新的技术架构,核心升级包括以下三点:
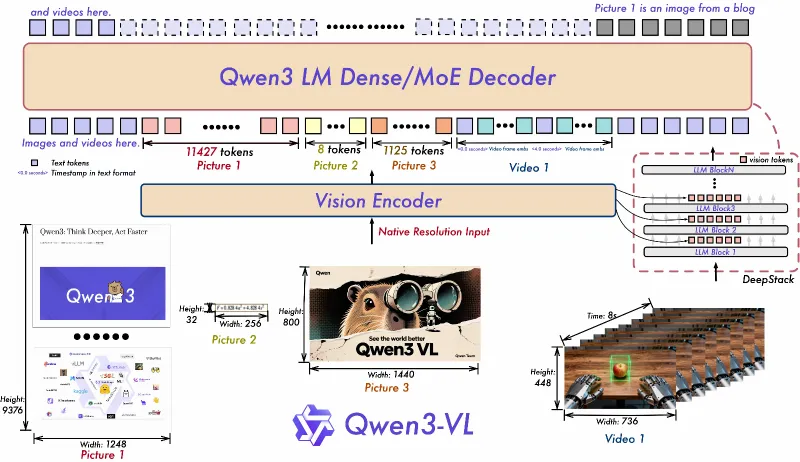
1. Interleaved-MRoPE:全维度位置编码
传统视觉-语言模型的位置编码仅能处理单一维度(如文本长度或图像尺寸),而Interleaved-MRoPE(交错式旋转位置编码)通过以下设计实现全维度覆盖:
同时对“时间(视频帧顺序)、宽度(图像水平像素)、高度(图像垂直像素)”三个维度分配频率,确保模型能感知视频的时序关系、图像的空间布局;
解决长视频中“早期帧信息丢失”问题,让模型在处理数小时视频时仍能保持对初始内容的记忆。
2. DeepStack:多层视觉特征融合
为捕捉图像/视频的细粒度细节(如小字体、微小物体),Qwen3-VL采用DeepStack架构:
融合多层ViT(视觉Transformer)的输出特征,底层特征保留边缘、颜色等细节,高层特征提取语义(如“这是一个禁止吸烟的标志”);
通过自适应权重调整,让模型在不同任务中侧重不同层级特征(如OCR任务侧重底层细节,场景识别侧重高层语义),提升图文对齐精度。
3. 文本-时间戳对齐:精准定位视频事件
相比传统的T-RoPE(时间旋转位置编码),Qwen3-VL的文本-时间戳对齐技术实现了更精细的时序建模:
可将文本描述与视频的具体时间戳绑定(如“视频中00:05:30出现的红色汽车,在00:06:10左转进入隧道”);
支持基于时间戳的逆向查询(如“找出视频中所有提到‘产品价格’的片段,并标记时间点”),强化对视频中动态事件的理解。
模型版本参数
Qwen3-VL提供多种参数规模和版本,满足不同场景需求,具体如下表:
| 参数规模 | 类型 | 量化支持 | 获取渠道 | 适用场景 |
|---|---|---|---|---|
| 2B | Instruct(指令微调) | FP8 | Hugging Face、ModelScope | 轻量应用、边缘设备 |
| 4B | Instruct | FP8 | Hugging Face、ModelScope | 中等算力场景(如手机端) |
| 8B | Instruct/Thinking | FP8 | Hugging Face、ModelScope | 常规开发、中小型服务 |
| 32B | Instruct/Thinking | FP8 | Hugging Face、ModelScope | 高精度推理、企业级应用 |
| 30B-A3B | Thinking(推理增强) | FP8 | Hugging Face、ModelScope | 复杂逻辑推理(如STEM任务) |
| 235B-A22B | Thinking | FP8 | 需申请商业授权 | 超大规模场景(如智能城市) |
四、应用场景
Qwen3-VL的多模态能力使其可广泛应用于各行各业,以下为典型场景:
1. 智能办公
文档处理:自动识别扫描件中的表格、公式,转换为可编辑文档;解析多语言合同,提取关键条款并生成风险提示;
会议辅助:实时分析会议录像,生成带时间戳的文字纪要,自动关联演示PPT中的内容(如“10:15提到的‘市场数据’对应PPT第3页图表”);
界面操作自动化:根据用户指令自动操作办公软件(如“在Excel中计算A列数据的平均值,并生成柱状图”),减少重复劳动。
2. 教育与科研
STEM教学:解析学生上传的数学题图片,分步推导解题过程;根据实验装置图讲解物理原理(如“图中是单摆实验装置,摆长越长,周期越长”);
文献分析:处理PDF格式的科研论文,识别公式、图表并生成摘要;跨语言翻译外文文献中的专业术语(如日文专利中的技术描述);
作业批改:自动识别手写作业中的文字和公式,判断计算正确性并标注错误位置。
3. 内容创作与设计
图文生成:根据用户输入的图片生成文案(如“为这张旅行照片写一段朋友圈文案”);将漫画截图转换为故事脚本;
设计辅助:从手绘草图生成UI代码(如“将这张App原型图转换为Flutter代码”);识别设计图中的颜色值(如“按钮的RGB值为#2E7D32”);
视频剪辑:根据文本指令剪辑视频(如“保留视频中所有出现‘夕阳’的片段,并按时间顺序拼接”)。
4. 机器人与具身智能
环境感知:帮助服务机器人识别家居环境(如“桌子上有一个水杯,位于右上角”),规划抓取路径;
指令执行:根据用户语言指令操作机械臂(如“拿起画面中红色的盒子,放到架子第二层”);
异常检测:在工业场景中识别设备仪表盘的异常读数(如“压力表指针超过红色警戒线,数值为1.8MPa”)。
5. 安防与监控
事件分析:实时监控公共场所视频,识别异常行为(如“有人在禁止吸烟区点火”)并触发警报;
轨迹追踪:记录特定目标(如可疑人员)的移动轨迹,生成带时间戳的文字报告;
多语言标识识别:识别机场、车站的多语言指示牌(如中文、英文、韩文),实时翻译为用户母语。
6. 电商与零售
商品识别:根据用户上传的商品图片,识别品牌、型号(如“这是大疆Mini 4 Pro无人机,官方售价4788元”),推荐同款或替代品;
包装解析:识别商品包装上的成分表、使用说明(如“化妆品成分中的‘烟酰胺’含量为3%”),生成通俗解读;
虚拟试穿:结合用户上传的照片和服装图片,分析穿搭效果(如“这件衣服的颜色与您的肤色匹配度为85%”)。
五、使用方法
Qwen3-VL提供了从快速体验到深度开发的完整工具链,以下为常用使用方式:
1. 快速体验:Web演示
通过Docker一键部署Web演示,步骤如下:
安装Docker(需支持GPU,推荐NVIDIA显卡,驱动版本≥525);
克隆仓库:
git clone https://github.com/QwenLM/Qwen3-VL.git && cd Qwen3-VL;运行部署脚本:
bash docker/docker_web_demo.sh(默认使用8B模型,可通过--model-path指定其他模型,如--model-path Qwen/Qwen3-VL-72B);打开浏览器访问
http://localhost:7860,即可上传图片/视频、输入文本指令进行交互。
2. 代码调用:Python接口
通过Hugging Face Transformers库加载模型,示例代码如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
import torch
# 加载模型和tokenizer
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-VL-8B",
device_map="auto",
torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-VL-8B")
# 准备输入(图片+文本指令)
image = Image.open("example.jpg") # 打开图片
prompt = "描述这张图片的内容,并分析其中的物体关系"
# 构建输入格式
inputs = tokenizer.from_list_format([
{"image": image}, # 图片输入
{"text": prompt} # 文本指令
])
inputs = tokenizer(inputs, return_tensors="pt").to(model.device)
# 生成输出
outputs = model.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)3. 微调模型:自定义训练
若需针对特定任务微调模型,可使用仓库中的qwen-vl-finetune工具:
准备数据集:需遵循格式
[{"image": "图片路径", "conversations": [{"from": "human", "value": "指令"}, {"from": "gpt", "value": "回答"}]}];安装依赖:
pip install -r qwen-vl-finetune/requirements.txt;运行训练脚本:
python qwen-vl-finetune/train/train.py \ --model_name_or_path Qwen/Qwen3-VL-8B \ --data_path ./custom_data.json \ --output_dir ./finetuned_model \ --num_train_epochs 3 \ --per_device_train_batch_size 2
4. 视频处理:长视频分析
处理长视频需使用qwen-vl-utils中的视频工具,示例如下:
from qwen_vl_utils import process_video
# 提取视频关键帧(每10秒1帧)
video_path = "long_video.mp4"
frames = process_video(video_path, frame_interval=10)
# 生成视频摘要
prompt = "总结这个视频的主要内容,并标记关键事件的时间点"
inputs = tokenizer.from_list_format([
{"video": frames}, # 视频帧序列
{"text": prompt}
])
# 后续生成步骤同图片处理六、常见问题解答(FAQ)
Q:Qwen3-VL需要什么硬件配置才能运行?
A:不同参数模型要求不同:2B/4B模型可在16GB显存的GPU(如RTX 3090)运行;8B模型需24GB显存;32B及以上模型建议使用A100(80GB)或多卡分布式部署。CPU也可运行,但速度极慢,不推荐。Q:支持哪些输入格式?
A:图像支持JPG、PNG、WEBP等常见格式;视频支持MP4、AVI、MOV等;文本支持纯文本、Markdown(含公式)。Q:微调时对数据集大小有要求吗?
A:小规模任务(如特定场景OCR)可使用数千条数据;复杂任务(如视觉推理)建议数万条以上,数据需覆盖多样场景以避免过拟合。Q:与其他视觉-语言模型(如GPT-4V、LLaVA)相比,Qwen3-VL有何优势?
A:Qwen3-VL开源可商用,支持更大上下文(256K),视觉代理和视频时序建模能力更强,且提供更完善的微调工具链。Q:OCR识别生僻字的准确率如何?
A:针对中文生僻字(如“𪚥”“𠔻”),通过专门优化的字库训练,准确率可达90%以上,古文字(如小篆)识别准确率约75%(需使用Thinking版本)。Q:是否支持离线部署?
A:是的,所有开源版本均可下载后离线部署,无需联网调用API。
七、相关链接
GitHub仓库:https://github.com/QwenLM/Qwen3-VL
Hugging Face模型库:https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
ModelScope模型库:https://modelscope.cn/collections/Qwen3-VL-5c7a94c8cb144b
八、总结
Qwen3-VL作为开源的强大多模态视觉-语言模型,通过创新的技术架构实现了视觉代理、长视频理解、空间推理等核心能力,覆盖从智能办公到机器人交互的多领域应用场景。其提供的多样化模型版本、完整的部署与微调工具链,降低了多模态AI的使用门槛,既适合开发者快速集成,也为研究者提供了二次创新的基础,是当前视觉-语言融合领域的重要开源成果。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/qwen3-vl.html





