Qwen-AgentWorld:通义千问推出的开源MoE架构智能体世界模拟模型
Qwen-AgentWorld 是阿里通义千问团队开源发布的原生语言世界模型(Language World Model,简称LWM),同步配套自研评测基准 AgentWorldBench,全部模型权重、数据集、工程代...

Qwen-AgentWorld 是阿里通义千问团队开源发布的原生语言世界模型(Language World Model,简称LWM),同步配套自研评测基准 AgentWorldBench,全部模型权重、数据集、工程代...

JoyAI-VL-Interaction 是京东 Joy 未来研究院视频理解团队全栈开源的8B 规模实时视频视觉语言交互系统,也是全球首个完整开放模型权重、训练方案、时序对齐交互数据集、全套...

GLM-5.2是智谱AI最新推出的GLM-5系列第三代旗舰文本大模型,定位为百万长上下文+工程Agent专用开源底座,是当前智谱全系综合能力最强、开放程度最高的大语言模型。

EvoQuality 是字节跳动与香港城市大学联合推出的自进化视觉语言模型框架,专注于无参考图像质量评估,完全无需人工标注,通过成对多数投票与 GRPO 算法实现自进化闭环,零样...

North Mini Code 是 Cohere 发布的开源代码大模型,采用MoE混合专家架构,拥有256K超长上下文窗口,原生适配AI代码智能体,支持仓库级代码编写、项目分析与运维脚本开发,基...

MusaCoder 是摩尔线程打造的垂直领域代码大模型系列,专门针对GPU算子、内核(Kernel)代码场景深度定制,目前包含 MusaCoder-9B 轻量版与 MusaCoder-27B 旗舰版两大版本。

Gemma 4 12B是Google DeepMind开源的稠密架构多模态大模型,隶属于Gemma 4全系产品线,参数规模约11.95B(统称120亿参数),分为google/gemma-4-12B预训练基座(Base)、goog...

Mellum2是JetBrains开源的MoE架构大模型,总参12B推理仅激活2.5B参数,支持128K超长上下文,分Base/Instruct/Thinking三大版本,主打离线IDE编程、企业私有化RAG、AI智能体...

Qwen‑VLA是阿里通义千问推出的开源通用视觉‑语言‑动作统一具身智能模型,基于Qwen多模态基座构建,通过四阶段训练实现视觉感知、语言理解与连续动作生成的端到端融合,单...
Step‑3.7‑Flash是阶跃星辰开源的生产级Agent专用多模态大模型,采用稀疏MoE架构,总参数198B、激活参数11B,最高生成速度400 Tokens/s,支持256K上下文与三级推理级别。模...

Keye-VL-2.0-30B-A3B是快手开源的30B级旗舰多模态大模型,采用DSA稀疏注意力架构,支持256K超长上下文无损推理,长视频理解性能领先同级别模型;原生集成Code/Tool/Search全...

Command A+是CohereLabs推出的Apache2.0协议开源稀疏混合专家大模型,拥有2180亿总参数,支持128K超长上下文、图文多模态交互、48种语种处理与智能工具调用,提供多精度量化...

Confucius4也被称作子曰4,是网易有道人工智能研发团队依托通义千问Qwen3.5-27B基座模型深度二次开发打造的开源多模态大语言模型,整体参数规模达到27B,该模型核心研发方向...
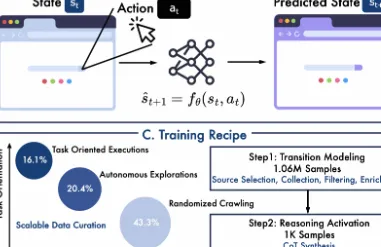
WebWorld 是由阿里通义千问QwenLM团队重磅开源的大规模网页世界模型,依托通义千问3大模型底座构建,是专门为网页智能体(Web Agent) 量身打造的浏览器仿真模拟环境框架。

Ling-2.6-1T 是蚂蚁集团旗下 inclusionAI 团队推出的万亿参数开源旗舰大语言模型,隶属于百灵Ling大模型家族,是面向真实复杂业务场景打造的即时执行型通用大模型。模型整体...