Xiaomi Auto WorldModel:小米推出的自动驾驶仿真与数据生成AI模型
Xiaomi Auto WorldModel是小米推出的自动驾驶联合世界模型,集成WorldRec三维重建、WorldGen视频生成两大模块,采用深度耦合架构,实现秒级场景重建、极速视频推理,有效解...

Xiaomi Auto WorldModel是小米推出的自动驾驶联合世界模型,集成WorldRec三维重建、WorldGen视频生成两大模块,采用深度耦合架构,实现秒级场景重建、极速视频推理,有效解...
Ling-2.6-flash是蚂蚁集团百灵大模型团队于2026年4月22日正式发布的高智效比AI大模型,核心定位为“快速推理+低成本部署”,彻底打破传统大模型“笨重、高价、难落地”的困...
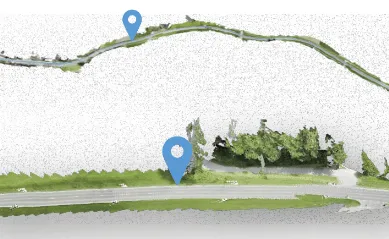
LingBot-Map是蚂蚁灵波科技于2026年4月开源的纯自回归流式3D重建基础模型,基于创新几何上下文Transformer(GCT)架构,仅需普通RGB摄像头即可实现20FPS实时推理与万帧级长...

GPT-Rosalind是OpenAI于2026年推出的、以生命科学家罗莎琳德·富兰克林命名的专用AI推理模型,专注服务于药物研发、基因组学、蛋白质研究、转化医学等生命科学领域。

MAI-Transcribe-1是微软公司发布的自研旗舰级语音转文字(Speech-to-Text,STT)AI模型,隶属于微软MAI系列自研AI模型矩阵(同期发布MAI-Voice-1语音生成、MAI-Image-2文生...

GPT-5.4 nano是OpenAI推出的GPT-5.4系列轻量化AI模型,主打极致轻量、超低延迟、极致性价比,仅通过API提供服务,专为文本分类、数据提取、内容排序、简单子智能体等高频轻...

MODNet是一款发表于AAAI 2022的开源实时无Trimap人像抠图框架,由香港城市大学与商汤科技联合研发,仅需RGB图像输入即可实现高精度人像分割,无需手动标注、无需绿幕、无需...

Capybara是由xgen-universe团队开源的统一视觉创作模型框架,基于先进扩散模型与Transformer架构,一站式支持文本生成图像(T2I)、文本生成视频(T2V)、指令驱动图像编辑...

ELMo(Embeddings from Language Models)模型,通过引入深度双向语言模型架构,首次实现了词向量的动态语境感知。本文AI铺子将从技术原理、架构创新、应用场景及局限性四个...

Claude Opus 4.5是Anthropic推出的最新一代旗舰AI模型,于2025年11月25日正式发布。它以“智能、高效、安全”为核心特质,在编程、智能体运作、计算机工具使用三大领域确立...

Kimi-K2是由Moonshot AI开发的开源代理智能模型,基于混合专家(MoE)架构,总参数达1万亿,激活参数320亿,在15.5万亿token上训练而成。该模型专注于工具使用、复杂推理和...

FG-CLIP是360开源的一系列细粒度视觉-文本跨模态对齐模型,专注于解决视觉与文本信息的精准匹配问题,尤其擅长细粒度特征对齐,且原生支持中英双语。该模型通过两阶段分层学...

SAIL-Embedding是字节跳动在Hugging Face平台开源的全模态嵌入基础模型,该模型突破传统单模态嵌入的局限,可将文本、图像等多类型数据映射至统一向量空间,实现跨模态特征...

DreamOmni2是一款开源多模态指令驱动图像编辑与生成模型,支持基于文本和图像参考的跨模态内容创作。其核心优势在于统一架构下兼顾生成与编辑任务,能精准保持对象身份、姿...

10 月 16 日,人工智能领域迎来新动态,知名人工智能公司 Anthropic 在其官网正式发布了新款小型 AI 模型 Claude Haiku4.5。这款模型凭借独特优势,一经推出便备受瞩目。...